- Linux NFS read-ahead best practices for Azure NetApp Files
- How to work with per-NFS filesystem read-ahead
- How to show or set read-ahead values
- Example
- How to persistently set read-ahead for NFS mounts
- Next steps
- Linux disk performance tuning
- Mount options#
- Swappiness Linux#
- Dirty Pages#
- I/O Scheduler Linux#
- Use separate disk for database and transaction loggin#
- Monitor I/O on disks#
- atop#
- telegraf, influxdb, grafana#
- observium#
- Disk#
- Read ahead in linux
- NAME
- SYNOPSIS
- DESCRIPTION
- RETURN VALUE
- ERRORS
- VERSIONS
- CONFORMING TO
- NOTES
- SEE ALSO
- COLOPHON
Linux NFS read-ahead best practices for Azure NetApp Files
This article helps you understand filesystem cache best practices for Azure NetApp Files.
NFS read-ahead predictively requests blocks from a file in advance of I/O requests by the application. It is designed to improve client sequential read throughput. Until recently, all modern Linux distributions set the read-ahead value to be equivalent of 15 times the mounted filesystems rsize .
The following table shows the default read-ahead values for each given rsize mount option.
| Mounted filesystem rsize | Blocks read-ahead |
|---|---|
| 64 KiB | 960 KiB |
| 256 KiB | 3,840 KiB |
| 1024 KiB | 15,360 KiB |
RHEL 8.3 and Ubuntu 18.04 introduced changes that might negatively impact client sequential read performance. Unlike earlier releases, these distributions set read-ahead to a default of 128 KiB regardless of the rsize mount option used. Upgrading from releases with the larger read-ahead value to those with the 128-KiB default experienced decreases in sequential read performance. However, read-ahead values may be tuned upward both dynamically and persistently. For example, testing with SAS GRID found the 15,360-KiB read value optimal compared to 3,840 KiB, 960 KiB, and 128 KiB. Not enough tests have been run beyond 15,360 KiB to determine positive or negative impact.
The following table shows the default read-ahead values for each currently available distribution.
| Distribution | Release | Blocks read-ahead |
|---|---|---|
| RHEL | 8.3 | 128 KiB |
| RHEL | 7.X, 8.0, 8.1, 8.2 | 15 X rsize |
| SLES | 12.X – at least 15SP2 | 15 X rsize |
| Ubuntu | 18.04 – at least 20.04 | 128 KiB |
| Ubuntu | 16.04 | 15 X rsize |
| Debian | Up to at least 10 | 15 x rsize |
How to work with per-NFS filesystem read-ahead
NFS read-ahead is defined at the mount point for an NFS filesystem. The default setting can be viewed and set both dynamically and persistently. For convenience, the following bash script written by Red Hat has been provided for viewing or dynamically setting read-ahead for amounted NFS filesystem.
Read-ahead can be defined either dynamically per NFS mount using the following script or persistently using udev rules as shown in this section. To display or set read-ahead for a mounted NFS filesystem, you can save the following script as a bash file, modify the file’s permissions to make it an executable ( chmod 544 readahead.sh ), and run as shown.
How to show or set read-ahead values
To show the current read-ahead value (the returned value is in KiB), run the following command:
To set a new value for read-ahead, run the following command:
./readahead.sh set [read-ahead-kb] Example
#!/bin/bash # set | show readahead for a specific mount point # Useful for things like NFS and if you do not know / care about the backing device # # To the extent possible under law, Red Hat, Inc. has dedicated all copyright # to this software to the public domain worldwide, pursuant to the # CC0 Public Domain Dedication. This software is distributed without any warranty. # For more information, see the [CC0 1.0 Public Domain Dedication](http://creativecommons.org/publicdomain/zero/1.0/). E_BADARGS=22 function myusage() < echo "Usage: `basename $0` set|show [read-ahead-kb]" > if [ $# -gt 3 -o $# -lt 2 ]; then myusage exit $E_BADARGS fi MNT=$ BDEV=$(grep $MNT /proc/self/mountinfo | awk '< print $3 >') if [ $# -eq 3 -a $1 == "set" ]; then echo $3 > /sys/class/bdi/$BDEV/read_ahead_kb elif [ $# -eq 2 -a $1 == "show" ]; then echo "$MNT $BDEV /sys/class/bdi/$BDEV/read_ahead_kb = "$(cat /sys/class/bdi/$BDEV/read_ahead_kb) else myusage exit $E_BADARGS fi How to persistently set read-ahead for NFS mounts
To persistently set read-ahead for NFS mounts, udev rules can be written as follows:
- Create and test /etc/udev/rules.d/99-nfs.rules :
SUBSYSTEM=="bdi", ACTION=="add", PROGRAM="/awk -v bdi=$kernel 'BEGIN > END' /proc/fs/nfsfs/volumes", ATTR="15380" sudo udevadm control --reload Next steps
Linux disk performance tuning

To get a better read-ahead on your disk you can set this to 4096 blocks instead of the default 256. This also depends on the type of use (read vs write) of the disk.
For example a database disk with a lots of reads you want a higher read-ahead. But this is very workload depended if you will have any result.
/sbin/blockdev --setra 4096 /dev/sdb In order not to lose these settings after a reboot, place the following per disk in the _/etc/rc.local _ file.
# Mysql Tuning for filesystem # Database Disk /sbin/blockdev --setra 4096 /dev/sdb # Logging Disk /sbin/blockdev --setra 256 /dev/sdc Mount options#
Especially in virtual machines that have their data on shared storage, it is important to prevent as many unnecessary I/O as possible. The option atime writes on every acces the acces time. Better to use is the option relatime. For application that don’t use the acces time on a dedicated mount point we can also use noatime.
# /dev/mapper/vg01-var /var ext4 defaults,relatime 1 2 /dev/sdb /var/lib/mysql ext4 defaults,noatime 1 2 Swappiness Linux#
The following setting in /etc/sysctl.d/swappiness.conf __ causes the kernel to write less aggressive RAM memory to swap space on disk. A couple of years ago a value of 0 was minimal swapping and valid. But with newer kernel releases this has changed. From RHEL 6.4 or Linux kernel 3.5-rc1 the behavior of the swappiness setting has changed. So check your distro/kernel what is valid and not.
# Less aggressive swapping vm.swappiness = 1 Redhat recommends a value of 10 when running a dedicated Oracle database. MariaDB recommends a value of 1 when running a dedicated MariaDB database.
Dirty Pages#
This setting ensures that the kernel speeds up ‘dirty’ pages (changed datain RAM, which has not yet been written to disk) from memory to disk.In the past, with RAM sizing up to 1024MB, a high percentage was fine. Withthe huge amounts of RAM that some servers have this is that after a long time, large amounts of data are suddenly transferred to disk written when the limit is reached.This setting prevents peak load on storage and streamlines I/O.Change the following to /etc/sysctl.d/dirty_pages.conf:
# Write dirty pages faster to disk vm.dirty_background_ratio = 3 vm.dirty_ratio = 40 I/O Scheduler Linux#
Some older Linux distributions are not yet adjusted to the virtual world. So the standard scheduler must be adjusted in the Virtual Machines. VMware has issued the following advice for this.
The NOOP scheduler can also be used for fast storage backends (SAN / NAS). The Deadline scheduler can also be used as an alternative.
To permanently and system-wide adjust the scheduler, the boot options of the kernel must be adjusted. Add the following to the GRUB_CMDLINE_LINUX_DEFAULT and regenerate grub.
It is also possible to adjust the scheduler per disk unit. For example, by including this in /etc/rc.local.
# Use NOOP Scheduler echo "noop" > /sys/block/sdb/queue/scheduler echo "noop" > /sys/block/sdc/queue/scheduler Use separate disk for database and transaction loggin#
Use a separate “virtual” disk for the database and a separate one for transaction logging if you are using a database on a server. This prevents the filling of the disk, for example, the log disk that the database disk also fills up and possible corruption. Another advantage with this is that you can use separate performance optimisation per disk. So you can set the database disk for example to perform better at reads and the transaction log disk better for writes. This is also valid for separating virtual disk over different datastores in a virtual environment.
Monitor I/O on disks#
In dutch we say “meten is weten” **** which translates to “to measure is to know”. So you need to measure your disk performance to see if your changes have the result you want or not.
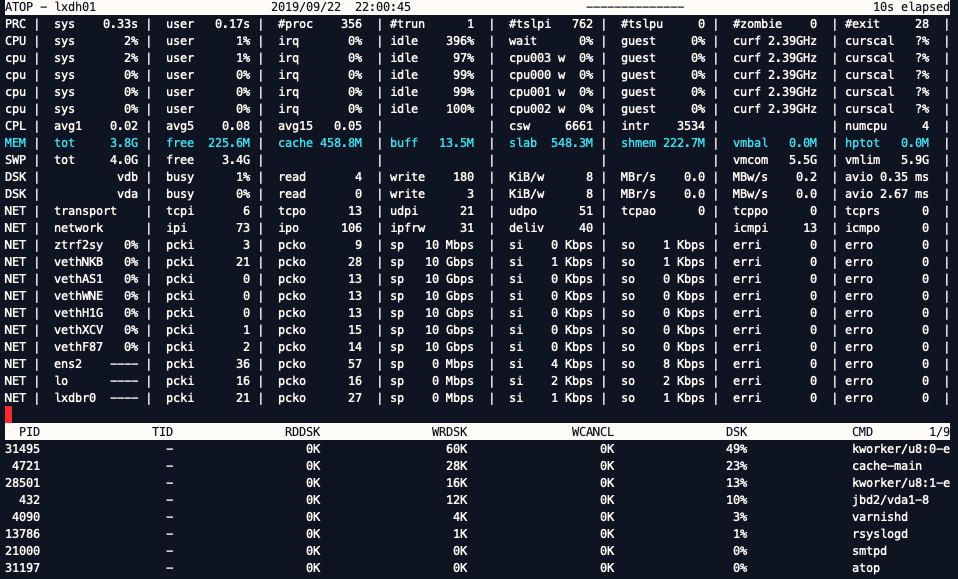
atop#
A nice CLI tool is atop in Linux_,_ here you can see semi realtime the write, reads, transfer speed, io times and wich proces claims the most disk time/
telegraf, influxdb, grafana#
For monitoring whole environments, at home or at work. I use many times the TIG stack. Telegraf collects the metrics and stores them into InfluxDB. Grafana create then the graphs in nice dashboard. telegraf can also collects various disk performance metrics.
observium#
Observium is a lamp stack tool that monitoring various metrics via SNMP. It also can monitor disk performance.

Disk#
To do a syntactic performance test, I used fio on Linux to test read, write and mixed performance.
#Random Read Write ./fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=test --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75 #Random Write ./fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=test --bs=4k --iodepth=64 --size=4G --readwrite=randread #Random Read ./fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=test --bs=4k --iodepth=64 --size=4G --readwrite=randwrite Read ahead in linux
NAME
readahead - perform file readahead into page cache
SYNOPSIS
#define _GNU_SOURCE /* See feature_test_macros(7) */ #include fcntl.h> ssize_t readahead(int fd, off64_t offset, size_t count);
DESCRIPTION
readahead() populates the page cache with data from a file so that subsequent reads from that file will not block on disk I/O. The fd argument is a file descriptor identifying the file which is to be read. The offset argument specifies the starting point from which data is to be read and count specifies the number of bytes to be read. I/O is performed in whole pages, so that offset is effectively rounded down to a page boundary and bytes are read up to the next page boundary greater than or equal to (offset+count). readahead() does not read beyond the end of the file. readahead() blocks until the specified data has been read. The current file offset of the open file referred to by fd is left unchanged.
RETURN VALUE
On success, readahead() returns 0; on failure, -1 is returned, with errno set to indicate the cause of the error.
ERRORS
EBADF fd is not a valid file descriptor or is not open for reading. EINVAL fd does not refer to a file type to which readahead() can be applied.
VERSIONS
The readahead() system call appeared in Linux 2.4.13; glibc support has been provided since version 2.3.
CONFORMING TO
The readahead() system call is Linux-specific, and its use should be avoided in portable applications.
NOTES
SEE ALSO
lseek(2), madvise(2), mmap(2), posix_fadvise(2), read(2)
COLOPHON
© 2019 Canonical Ltd. Ubuntu and Canonical are registered trademarks of Canonical Ltd.