Регулярные выражения в Linux
![]()
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Для работы в основном используются следующие символы:
- » ext» — слова начинающиеся с text
- «text/» — слова, заканчивающиеся на text
- «^» — начало строки
- «$» — конец строки
- «a-z» — диапазон от a до z
- «[^t]» — не буква t
- «[« — воспринять символ [ буквально
- «.» — любой символ
- «a|z» — а или z
Регулярные выражения в основном используются со следующими командами:
- egrep — расширенный grep
- fgrep — быстрый grep
- rgrep — рекурсивный grep
- sed — потоковый текстовый редактор.
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.
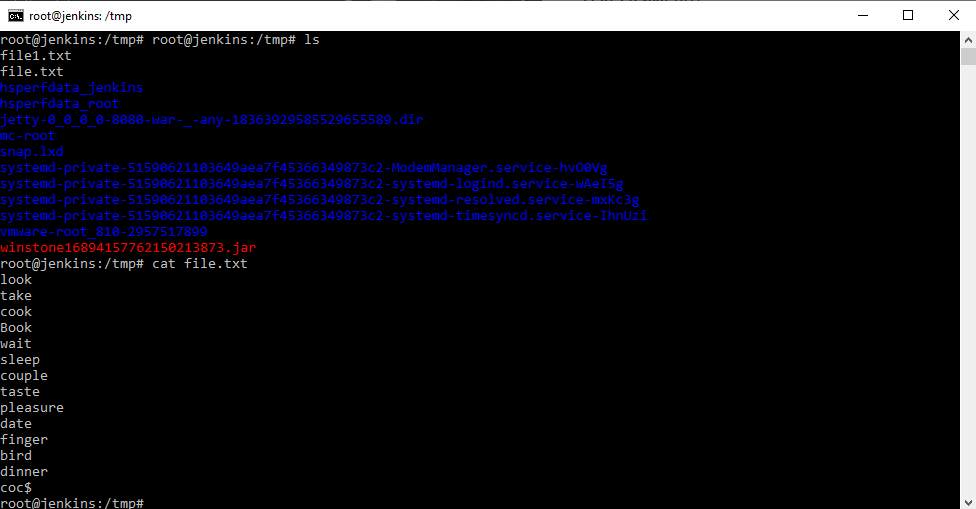
Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.
Первая команда — grep
Получаем справку по данной команде. Как можно понять из справки команда grep и ее производные — это печать линий совпадающих шаблонов. Проще говоря, команда grep помогает сортировать те данные, что мы даем команде, через знак конвейера на ввод. Причем в мануале мы можем видеть egrep, fgrep и т.д. данные команды мы можем не использовать. Использовать можно только grep с ключами различными, т.е. ключи просто заменяют эти команды. Можно на примере посмотреть, как работает данная команда. Например, grep oo file.txt
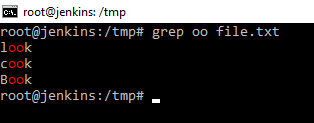
На картинке видно, что команда из указанного файла выбрала по определенному шаблону «oo». Причем даже делает красным цветом подсветку. Можно добавить еще ключик -n, тогда данная команда еще и выведет номер строки в которой находится то, что ищется по шаблону. Это полезно, когда работаем с каким-нибудь кодом или сценарием. Когда необходимо, что-то найти. Сразу видим, где находится объект поиска или что-то ищем по логам.
При использовании шаблона очень важно понимать, что команда grep, чувствительна к регистрам в шаблонах. Это означает, что Boo и boo это разные шаблоны. В одном случае команда найдет слово, а в другом нет. Можно команде сказать, чтобы она не учитывала регистр. Это делается с помощью ключа -i.
Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.
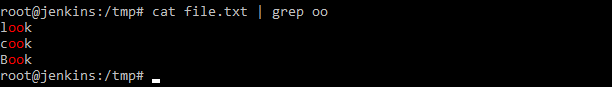
Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.
Давайте найдем файлы в которых содержится сочетание «ple«. grep ple file.txt в данном случае команда нашла оба слова содержащие шаблон. Давайте найдем слово, которое будет начинаться с «ple«. Команда будет выглядеть следующим образом: grep ^ple file.txt . Значок «^» указывает на начало строки. Противоположная задача найти слова, заканчивающиеся на «ple«. Команда будет выглядеть следующим образом grep ple$ file.txt . Т.е. применять к концу строки, говорит значок «$» в шаблоне.

Можно дать команду grep .o file.txt. В данном выражении знак «.» , заменяет любую букву.

Как вы видите вывод шаблона «.ple» вывел только одно слово т.к только слово couple удовлетворяло шаблону , т.к перед «ple» должен был содержаться еще один символ любой.
Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
man egrep — отошлет к справке по grep.
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.
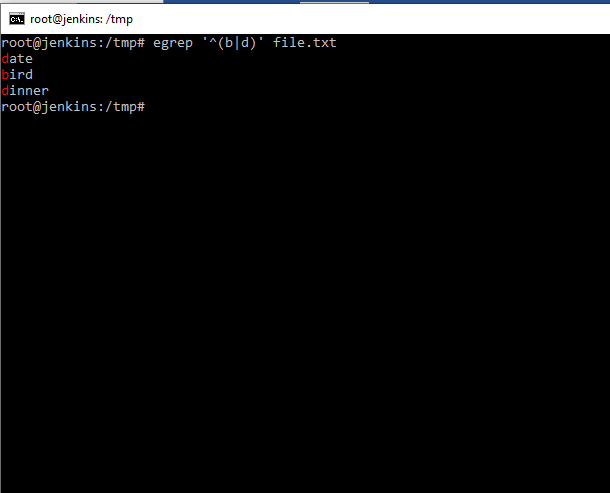
Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:
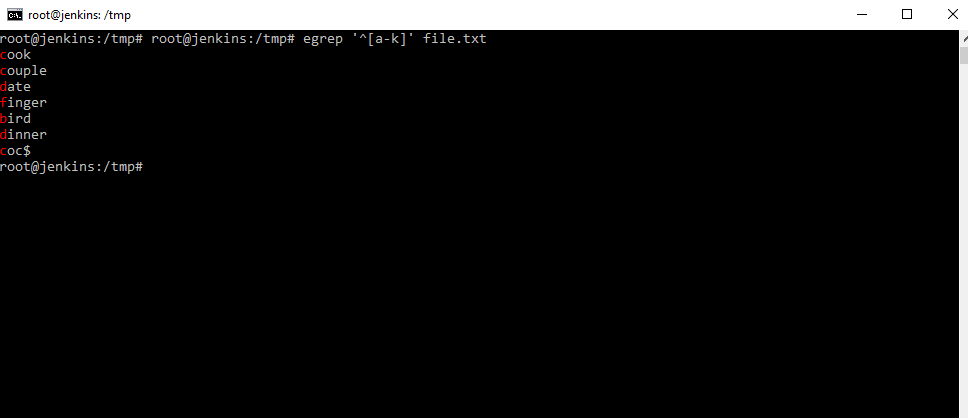
Получим все слова, начинающиеся с «a» по «к». Знак «[]» — диапазона. Как мы видим слова, начинающиеся с большой буквы, не попали. Все эти регулярные выражения очень пригодятся, когда мы что-то ищем в файлах логах.
Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Как вариант egrep можно запускать просто grep с ключиком -e.
Про fgrep
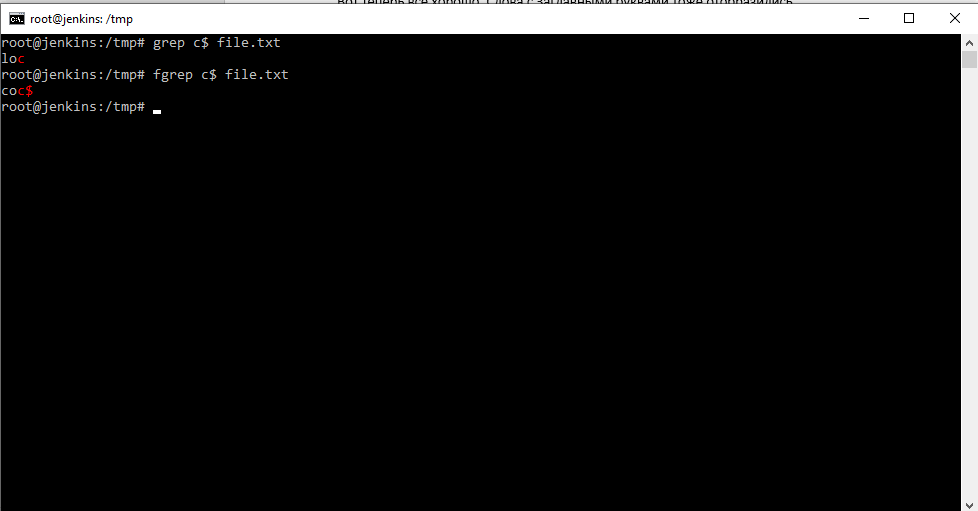
man fgrep — отошлет к справке по grep. Команда fgrep не понимает регулярных выражений вообще.
Получается следующим образом если мы вводим: egrep c$ file.txt . То команда согласно шаблону, ищет в файле букву «c» в конце слова. В случае же с командой fgrep c$ file.txt , команда будет искать именно сочетание «с$». Т.е. команда fgrep воспринимает символы регулярных выражений, как обычные символы, которые ей нужно найти, как аргументы.
Рекурсивный rgrep
Создадим каталог mkdir folder . Создадим файл great.txt в созданной директории folder со словом Hello при помощью команды echo «Hello» folder/great.txt
И если мы скажем grep Hello * , поищи слово Hello в текущей директории. Получится следующая картина.
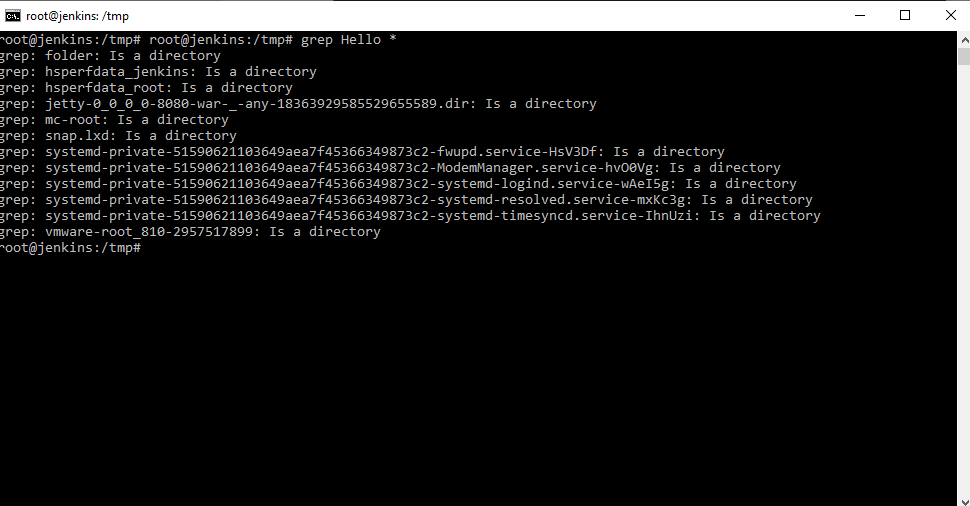
Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
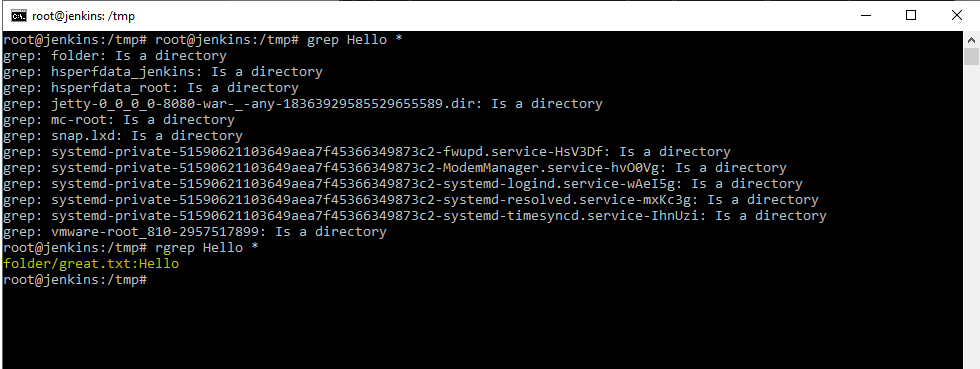
Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Данная утилита пробежалась по всем папкам и файлам в них и нашла подходящее под шаблон слово. Т.е. если нам необходимо провести поиск по всем файлам и папкам, то необходимо использовать утилиту rgrep .
Команда sed
man sed — стрим редактор. Т.е потоковый редактор для фильтрации и редактирования потока данных.
Например, sed -e ‘s/oo/aa’ file.txt — открыть редактор sed и заменить вывод всех oo на aa в файле file.txt. Нужно понимать, что в результате данной команды изменения в файле не произойдут. Просто данные из файла будут взяты и с изменениями выведены на стандартный вывод, т.е. экран. Для сохранения результатов мы можем сказать, чтобы вывел в новый файл указав направление вывода.
sed -e ‘s/oo/aa’ file.txt newfile.txt
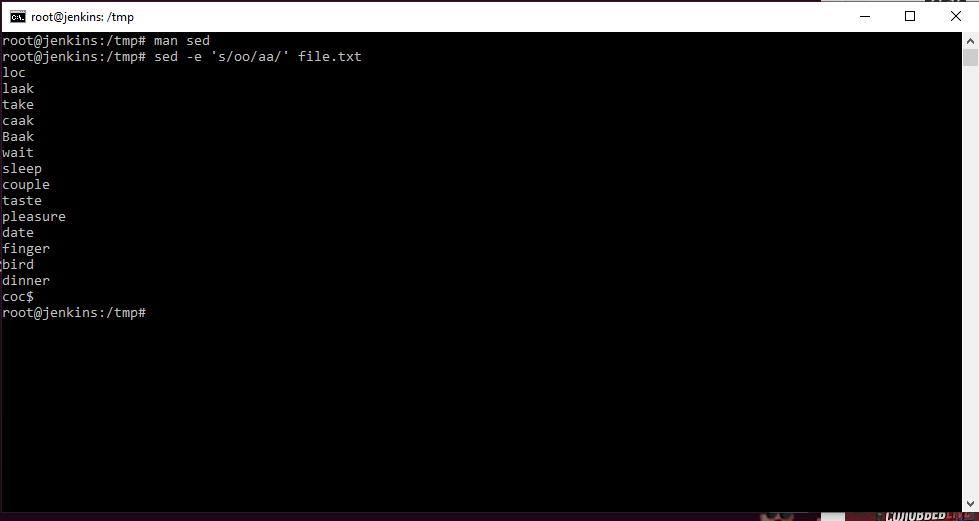
В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.
Bash-скрипты: регулярные выражения
Для того, чтобы полноценно обрабатывать тексты в bash-скриптах с помощью sed и awk, просто необходимо разобраться с регулярными выражениями. Реализации этого полезнейшего инструмента можно найти буквально повсюду, и хотя устроены все регулярные выражения схожим образом, основаны на одних и тех же идеях, в разных средах работа с ними имеет определённые особенности. Тут мы поговорим о регулярных выражениях, которые подходят для использования в сценариях командной строки Linux.
Этот материал задуман как введение в регулярные выражения, рассчитанное на тех, кто может совершенно не знать о том, что это такое. Поэтому начнём с самого начала.
- 1 Что такое регулярные выражения
- 2 Типы регулярных выражений
- 3 Регулярные выражения POSIX BRE
- 4 Специальные символы
- 5 Якорные символы
- 6 Символ «точка»
- 7 Классы символов
- 8 Отрицание классов символов
- 9 Диапазоны символов
- 10 Специальные классы символов
- 11 Символ «звёздочка»
- 12 Регулярные выражения POSIX ERE
- 12.1 ▍Вопросительный знак
- 12.2 ▍Символ «плюс»
- 12.3 ▍Фигурные скобки
- 12.4 ▍Символ логического «или»
- 14.1 ▍Подсчёт количества файлов
- 14.2 ▍Проверка адресов электронной почты
Что такое регулярные выражения
У многих, когда они впервые видят регулярные выражения, сразу же возникает мысль, что перед ними бессмысленное нагромождение символов. Но это, конечно, далеко не так. Взгляните, например, на это регулярное выражение
^ ( [ a — zA — Z0 — 9_ \ — \ . \ + ] + ) @ ( [ a — zA — Z0 — 9_ \ — \ . ] + ) \ . ( [ a — zA — Z ] < 2 , 5 >) $
На наш взгляд даже абсолютный новичок сходу поймёт, как оно устроено и зачем нужно 🙂 Если же вам не вполне понятно — просто читайте дальше и всё встанет на свои места.
Регулярное выражение — это шаблон, пользуясь которым программы вроде sed или awk фильтруют тексты. В шаблонах используются обычные ASCII-символы, представляющие сами себя, и так называемые метасимволы, которые играют особую роль, например, позволяя ссылаться на некие группы символов.Типы регулярных выражений
Реализации регулярных выражений в различных средах, например, в языках программирования вроде Java, Perl и Python, в инструментах Linux вроде sed, awk и grep, имеют определённые особенности. Эти особенности зависят от так называемых движков обработки регулярных выражений, которые занимаются интерпретацией шаблонов.
В Linux имеется два движка регулярных выражений:- Движок, поддерживающий стандарт POSIX Basic Regular Expression (BRE).
- Движок, поддерживающий стандарт POSIX Extended Regular Expression (ERE).
Большинство утилит Linux соответствуют, как минимум, стандарту POSIX BRE, но некоторые утилиты (в их числе — sed) понимают лишь некое подмножество стандарта BRE. Одна из причин такого ограничения — стремление сделать такие утилиты как можно более быстрыми в деле обработки текстов.
Стандарт POSIX ERE часто реализуют в языках программирования. Он позволяет пользоваться большим количеством средств при разработке регулярных выражений. Например, это могут быть специальные последовательности символов для часто используемых шаблонов, вроде поиска в тексте отдельных слов или наборов цифр. Awk поддерживает стандарт ERE.
Существует много способов разработки регулярных выражений, зависящих и от мнения программиста, и от особенностей движка, под который их создают. Непросто писать универсальные регулярные выражения, которые сможет понять любой движок. Поэтому мы сосредоточимся на наиболее часто используемых регулярных выражениях и рассмотрим особенности их реализации для sed и awk.
Регулярные выражения POSIX BRE
Пожалуй, самый простой шаблон BRE представляет собой регулярное выражение для поиска точного вхождения последовательности символов в тексте. Вот как выглядит поиск строки в sed и awk: