- How to remove extra spaces in bash?
- 10 Answers 10
- How to Remove Spaces from Filenames in Linux
- Prerequisite
- 1. Removing Spaces from Filename with Specific File Extension
- 2. Replacing Filename Spaces Using rename Command
- 3. Replacing Filename Spaces Using For Loop and mv Command
- How to remove space from string? [duplicate]
- 5 Answers 5
- Removing all spaces from the beginning of lines
- 6 Answers 6
How to remove extra spaces in bash?
Do you really want to remove the whitespace in HEAD , or just provide the expansion of $HEAD without whitespace to another command? The shell provides better tools for controlling the output of expansion than it does tools for just mutating a variable in place.
10 Answers 10
or maybe you want to save it in a variable:
To remove leading and trailing whitespaces, do this:
NEWHEAD=$(echo "$HEAD" | tr -s " ") NEWHEAD=$ NEWHEAD=$
What’s the point of calling tr when you don’t quote $HEAD , so bash does word splitting and therefore collapses the whitespace on itself?
$ echo "$HEAD" | awk '$1=$1' how to remove extra spaces Take advantage of the word-splitting effects of not quoting your variable
$ HEAD=" how to remove extra spaces " $ set -- $HEAD $ HEAD=$* $ echo ">>>$HEAD>>how to remove extra spaces If you don't want to use the positional paramaters, use an array
One dangerous side-effect of not quoting is that filename expansion will be in play. So turn it off first, and re-enable it after:
Note that the behavior depends on the value IFS . With the default IFS , namely $' \t\n' you'll also replace tabs and newlines by a space.
This horse isn't quite dead yet: Let's keep beating it!*
Read into array
Other people have mentioned read , but since using unquoted expansion may cause undesirable expansions all answers using it can be regarded as more or less the same. You could do
Extended Globbing with Parameter Expansion
$ shopt -s extglob $ HEAD="$" HEAD="$" HEAD="$" $ printf '"%s"\n' "$HEAD" "how to remove extra spaces"
*No horses were actually harmed – this was merely a metaphor for getting six+ diverse answers to a simple question.
This is the only answer that really makes sense here. It's sad ugly hacks and semi-broken answers are upvoted instead…
In honor of this answer (which avoids echo, shell expansion and all the other pitfalls all the other answers went into), I deleted my own incorrect answer.
Two more notes: read needs -r to prevent processing backslash escapes, and -d "" to normalize newlines rather than truncating at first newline. Both options need to be passed before -a .
You introduced an error when applying @MichałGórny's suggestion: read -rd'' -a HEAD will not work, it needs to be read -r -d '' -a HEAD or read -rd '' -a HEAD . Also, IFS should be mentioned, as this will only work if IFS contains the space character.
Here's how I would do it with sed:
string=' how to remove extra spaces ' echo "$string" | sed -e 's/ */ /g' -e 's/^ *\(.*\) *$/\1/' => how to remove extra spaces # (no spaces at beginning or end)
The first sed expression replaces any groups of more than 1 space with a single space, and the second expression removes any trailing or leading spaces.
echo -e " abc \t def "|column -t|tr -s " "
tr -s " " will squeeze multiple spaces to single space
BTW, to see the whole output you can use cat - -A : shows you all spacial characters including tabs and EOL:
echo -e " abc \t def "|column -t|tr -s " "|cat - -A
Whitespace can take the form of both spaces and tabs. Although they are non-printing characters and unseen to us, sed and other tools see them as different forms of whitespace and only operate on what you ask for. ie, if you tell sed to delete x number of spaces, it will do this, but the expression will not match tabs. The inverse is true- supply a tab to sed and it will not match spaces, even if the number of them is equal to those in a tab.
A more extensible solution that will work for removing either/both additional space in the form of spaces and tabs (I've tested mixing both in your specimen variable) is:
or we can tighten-up @Frontear 's excellent suggestion of using xargs without the tr :
However, note that xargs would also remove newlines. So if you were to cat a file and pipe it to xargs , all the extra space- including newlines- are removed and everything put on the same line ;-).
Both of the foregoing achieved your desired result in my testing.
How to Remove Spaces from Filenames in Linux
In other operating system environments, creating and using filenames with spaces is irrevocably permissible. However, when we enter the Linux operating system domain, the existence of such filenames becomes an inconvenience.
For instance, consider the existence of the following filenames inside a Linux operating system environment.

As per the command line view of these filenames, processing or moving them becomes an unwarranted inconvenience because of the white space in their naming convention.
Additionally, filename spaces in Linux are a disadvantage to users processing them via web-based applications as the string %20 tends to be included as part of the processed/final filename.
This article takes a look at valid approaches to help you get rid of spaces on filenames while working under a Linux operating system environment.
Prerequisite
Familiarize yourself with the usage of the Linux terminal or command-line interface. For practical reference purposes, we will be using the spaced filenames presented in the following screen capture.
1. Removing Spaces from Filename with Specific File Extension
The find command is combined with the mv command to effectively execute its functional objective to remove spaces on a filename with a specific file extension e.g .xml files.
$ find . -type f -name "* *.xml" -exec bash -c 'mv "$0" "$"' <> \;

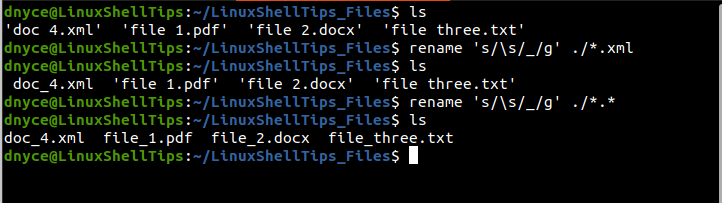
2. Replacing Filename Spaces Using rename Command
Alternatively, instead of using find with mv commands to trace and replace filename spaces, we could use a single rename command, which is a pearl extension and can be installed in the following Linux operating system distributions:
$ sudo apt install rename [On Debian, Ubuntu and Mint] $ sudo yum install rename [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux] $ sudo emerge -a sys-apps/rename [On Gentoo Linux] $ sudo pacman -S rename [On Arch Linux] $ sudo zypper install rename [On OpenSUSE]
Once installed, the rename command can be used in the following manner:
The above command will replace the spaces in all .xml files with an underscore. To replace all the spaces in all the filenames regardless of the file extension, use:

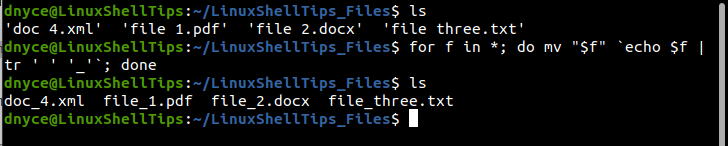
3. Replacing Filename Spaces Using For Loop and mv Command
This approach is effective in getting rid of filename spaces on different file name formats existing on a specific/targeted folder/directory. The for loop function queries for filename spaces inside a targeted directory/folder and afterward replaces those filename spaces with an underscore notation.
Consider the following implementation of this approach:
$ for f in *; do mv "$f" `echo $f | tr ' ' '_'`; done

Before the start of this article, filename spaces were a nuisance especially when you need to copy and move files from the Linux terminal or process them via a web-based program. This tutorial has provided a viable solution that works against such inconveniences.
How to remove space from string? [duplicate]
trimming everything, at start, at the end and all in the midle: echo ' aaa bb c'|xargs -L1 echo it is all. of course you can change -L1 into -n1 , then all strings will be converted into separate lines.
5 Answers 5
The tools sed or tr will do this for you by swapping the whitespace for nothing
$ echo " 3918912k " | sed 's/ //g' 3918912k
How can I use it to save the result in a variable? Does it only work in echo ? I'm having some trouble. Is it supposed to work like: RESULT="$STR" | set "s/ //g" ?
Try doing this in a shell:
That uses parameter expansion (it's a non posix feature)
Substitution inside parameter expansion isn't POSIX. It will work in Bash (and maybe other shells I don't know), but not in Dash for example.
Since you're using bash, the fastest way would be:
shopt -s extglob # Allow extended globbing var=" lakdjsf lkadsjf " echo "$"
It's fastest because it uses built-in functions instead of firing up extra processes.
However, if you want to do it in a POSIX-compliant way, use sed :
var=" lakdjsf lkadsjf " echo "$var" | sed 's/[[:space:]]//g'
You can also use echo to remove blank spaces, either at the beginning or at the end of the string, but also repeating spaces inside the string.
$ myVar=" kokor iiij ook " $ echo "$myVar" kokor iiij ook $ myVar=`echo $myVar` $ $ # myVar is not set to "kokor iiij ook" $ echo "$myVar" kokor iiij ook
This is not reliable : if myVar contains special characters like * , the shell will expand it with the files of the current directory.
@bobpaul, it prevents expansion of globs, etc, but also includes the leading and trailing whitespaces Mickaël intended to get rid of 🙁
A funny way to remove all spaces from a variable is to use printf:
$ myvar='a cool variable with lots of spaces in it' $ printf -v myvar '%s' $myvar $ echo "$myvar" acoolvariablewithlotsofspacesinit
It turns out it's slightly more efficient than myvar="$" , but not safe regarding globs ( * ) that can appear in the string. So don't use it in production code.
If you really really want to use this method and are really worried about the globbing thing (and you really should), you can use set -f (which disables globbing altogether):
$ ls file1 file2 $ myvar=' a cool variable with spaces and oh! no! there is a glob * in it' $ echo "$myvar" a cool variable with spaces and oh! no! there is a glob * in it $ printf '%s' $myvar ; echo acoolvariablewithspacesandoh!no!thereisaglobfile1file2init $ # See the trouble? Let's fix it with set -f: $ set -f $ printf '%s' $myvar ; echo acoolvariablewithspacesandoh!no!thereisaglob*init $ # Since we like globbing, we unset the f option: $ set +f
I posted this answer just because it's funny, not to use it in practice.
Removing all spaces from the beginning of lines
Hello. I have file in this format with many spaces at the beginning of every line and i wold like to remove those spaces from beginning and printed all fields using awk or sed. RESULT:
1 147.31.124.135 1 147.32.123.135 1 147.32.123.136 1 147.32.124.135 1 77.236.192.69 1 86.49.86.108 1 86.49.86.109
6 Answers 6
You can use this sed command to remove leading whitespace (spaces or tabs)
Use sed -i to modify the file in-place.
Worked for me. Just wanted to add that for running on macOS you need to use this sed -i'.bak' 's/^[ \t]*//' file
You can even use POSIX character class [:space:] which will handle all whitespaces ( \t , \r , \n , \v etc):
Explanation: ^ indicates the start of a line, and * indicates zero or more spaces. These are replaced by nothing.
bash-3.2$ cat input 1 147.31.124.135 1 147.31.9.135 1 147.32.123.135 1 147.32.123.136 1 147.32.124.135 1 77.236.192.69 1 86.49.86.108 1 86.49.86.109 bash-3.2$ awk 'sub(/^ */, "")' input 1 147.31.124.135 1 147.31.9.135 1 147.32.123.135 1 147.32.123.136 1 147.32.124.135 1 77.236.192.69 1 86.49.86.108 1 86.49.86.109
The following command can be used to remove all leading white spaces from each line of an input file:
This command uses sed to perform a search-and-replace operation on each line of the input file. The search pattern ^ * matches zero or more spaces (indicated by *) at the start of each line (indicated by ^). The replace pattern, an empty string '', removes the matched spaces. The result is written to an output file, or to the terminal if no output file is specified.