- Remove duplicate files in multiple folders [closed]
- 4 Answers 4
- 5 Best Tools to Find and Remove Duplicate Files in Linux
- 1. Rdfind – Find Duplicate Files in Linux
- Install Rdfind on Linux
- 2. Fdupes – Scan for Duplicate Files in Linux
- Install Fdupes in Linux
- 3. Rmlint – Remove Duplicate Files
- Install Rmlint on Linux
- 4. dupeGuru – Find Duplicate Files in a Linux
- Install dupeGuru on Linux
- 5. FSlint – Duplicate File Finder for Linux
- Install FSlint on Linux
Remove duplicate files in multiple folders [closed]
Want to improve this question? Update the question so it focuses on one problem only by editing this post.
I have a directory which have many sub-directories, and sub-sub-directories and so on possibly. I would like to select a particular folder say A and delete all the files from directory other than A if such files occur in both A and directory other than A . Basically I would like to remove duplication (only with reference to A ) by keeping the files in A intact. Furthermore, for all files that do not occur in A , I would like to keep only one copy in any one of the directories (possibly based on lexicographically first directory name or any other selection criteria). Please help me write the script for the same.
Are there only duplicates? No changed versions? No older/newer versions? So if a file exists in A if a file with the same name is found in B/sub1 , the files are guaranteed to be the same? Also, does A have subdirectories?
files with same name are to be reared same regardless of their location in directories. A has subdirectories, and A and other directories from which files are to be deleted can be in same depth level.
4 Answers 4
See Usage: below for examples of running this script. Note: this script has the actual delete of files commented out. To enable actually removing files, you will need to uncomment # rm «$rmfn» in the script.
Note2: to actually delete files, you must give this script a 3rd argument: -d to cause the files to be removed. If you just provide argument 1: A (path to files to save) and argument 2: pathB (path with subdirs to look for dupes in), then this script just prints duplicates found so you can verify everything is as you want before preforming the removal.
Linux application fdupes I would be remiss not to tell you that there is a common application fdupes that is designed to do just what you are wanting to do (much more flexible and thoroughly tested).
#!/bin/bash ## check input dirs both exist [ -e "$1" ] && [ -e "$2" ] || < printf "\nError: invalid path. Usage %s dirA pathB\n\n" "$" exit 1 > tmp="tmp_$(date +%s).txt" # unique temp file name [ -f "$tmp" ] && rm "$tmp" # test if already exists and del find "$2" -type f > "$tmp" # fill tmp file with possible dups for i in $(find "$1" -type f); do # check each file in A ($1) against tmp fn="$" # remove path from A/filename if grep -q "$fn" "$tmp"; then # test if A/file found in pathB ($2) if [ "$3" = -d ]; then # if 3rd arg is '-d', really delete for rmfn in $(grep "$fn" "$tmp"); do # get list of matching filenames printf " deleting: %s\n" "$rmfn" >&2 # print record of file deleted # rm "$rmfn" # the delete command (commented) done else # if no '-d', just print duplicates found printf "\n Duplicate(s) found for: %s\n\n" "$fn" grep "$fn" "$tmp" # output duplicate files found fi fi done rm "$tmp" # delete tmp file exit 0 The script requires 2 directories as input to scan for duplicates and it requires a third argument ‘-d’ to actually delete duplicates found. Example:
$ bash fdupes.sh ~/scr/utl ~/scr/rmtmp/ Duplicate found for: bay.sh /home/david/scr/rmtmp/bay.sh Duplicate found for: rsthemes.sh /home/david/scr/rmtmp/rsthemes.sh Duplicate found for: nocomment /home/david/scr/rmtmp/nocomment.sh Duplicate found for: show-rdtcli.sh /home/david/scr/rmtmp/show-rdtcli.sh /home/david/scr/rmtmp/subdir1/show-rdtcli.sh
Actually deleting duplicates (after uncommenting rm ):
$ bash fdupes.sh ~/scr/utl ~/scr/rmtmp/ -d deleting: /home/david/scr/rmtmp/bay.sh deleting: /home/david/scr/rmtmp/rsthemes.sh deleting: /home/david/scr/rmtmp/nocomment.sh deleting: /home/david/scr/rmtmp/show-rdtcli.sh deleting: /home/david/scr/rmtmp/subdir1/show-rdtcli.sh 5 Best Tools to Find and Remove Duplicate Files in Linux
Organizing your home directory or even system can be particularly hard if you have the habit of downloading all kinds of stuff from the internet using your download managers.
Often you may find you have downloaded the same mp3, pdf, and epub (and all kinds of other file extensions) and copied it to different directories. This may cause your directories to become cluttered with all kinds of useless duplicated stuff.
In this tutorial, you are going to learn how to find and delete duplicate files in Linux using rdfind, fdupes, and rmlint command-line tools, as well as using GUI tools called DupeGuru and FSlint.
A note of caution – always be careful what you delete on your system as this may lead to unwanted data loss. If you are using a new tool, first try it in a test directory where deleting files will not be a problem.
1. Rdfind – Find Duplicate Files in Linux
Rdfind comes from redundant data find, which is a free command-line tool used to find duplicate files across or within multiple directories. It recursively scans directories and identifies files that have identical content, allowing you to take appropriate actions such as deleting or moving the duplicates.
Rdfind uses an algorithm to classify the files and detects which of the duplicates is the original file and considers the rest as duplicates.
- If A was found while scanning an input argument earlier than B, A is higher ranked.
- If A was found at a depth lower than B, A is higher ranked.
- If A was found earlier than B, A is higher ranked.
The last rule is used particularly when two files are found in the same directory.
Install Rdfind on Linux
To install rdfind in Linux, use the following command as per your Linux distribution.
$ sudo apt install rdfind [On Debian, Ubuntu and Mint] $ sudo yum install rdfind [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/rdfind [On Gentoo Linux] $ sudo apk add rdfind [On Alpine Linux] $ sudo pacman -S rdfind [On Arch Linux] $ sudo zypper install rdfind [On OpenSUSE]
To run rdfind on a directory simply type rdfind and the target directory.
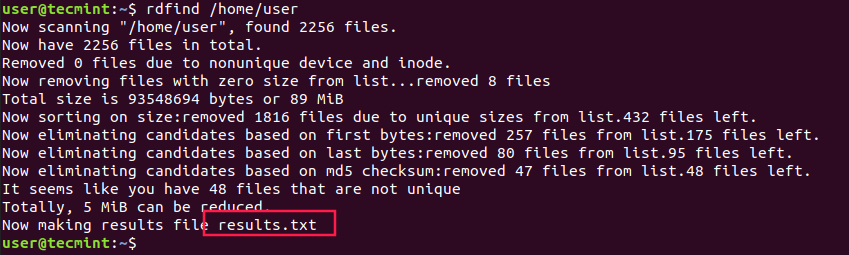
As you can see rdfind will save the results in a file called results.txt located in the same directory from where you ran the program. The file contains all the duplicate files that rdfind has found. You can review the file and remove the duplicate files manually if you want to.
Another thing you can do is to use the -dryrun an option that will provide a list of duplicates without taking any actions:
$ rdfind -dryrun true /home/user
When you find the duplicates, you can choose to replace them with hard links.
$ rdfind -makehardlinks true /home/user
And if you wish to delete the duplicates you can run.
$ rdfind -deleteduplicates true /home/user
To check other useful options of rdfind you can use the rdfind manual.
2. Fdupes – Scan for Duplicate Files in Linux
Fdupes is another command-line program that allows you to identify duplicate files on your system. It searches directories recursively, comparing file sizes and content to identify duplicates.
It uses the following methods to determine duplicate files:
- Comparing partial md5sum signatures
- Comparing full md5sum signatures
- byte-by-byte comparison verification
Just like rdfind, it has similar options:
- Search recursively
- Exclude empty files
- Shows the size of duplicate files
- Delete duplicates immediately
- Exclude files with a different owner
Install Fdupes in Linux
To install fdupes in Linux, use the following command as per your Linux distribution.
$ sudo apt install fdupes [On Debian, Ubuntu and Mint] $ sudo yum install fdupes [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/fdupes [On Gentoo Linux] $ sudo apk add fdupes [On Alpine Linux] $ sudo pacman -S fdupes [On Arch Linux] $ sudo zypper install fdupes [On OpenSUSE]
Fdupes syntax is similar to rdfind. Simply type the command followed by the directory you wish to scan.
To search files recursively, you will have to specify the -r an option like this.
You can also specify multiple directories and specify a dir to be searched recursively.
To have fdupes calculate the size of the duplicate files use the -S option.
To gather summarized information about the found files use the -m option.

Finally, if you want to delete all duplicates use the -d an option like this.
Fdupes will ask which of the found files to delete. You will need to enter the file number:
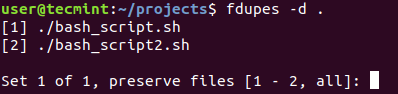
A solution that is definitely not recommended is to use the -N option which will result in preserving the first file only.
To get a list of available options to use with fdupes review the help page by running.
3. Rmlint – Remove Duplicate Files
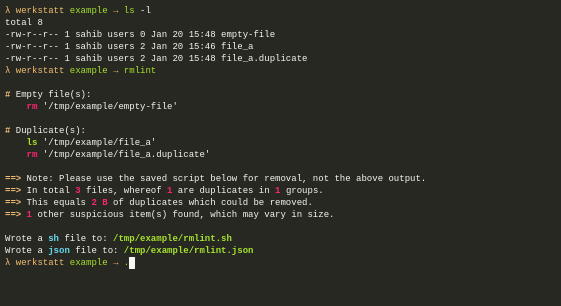
Rmlint is a command-line tool that is used for finding and removing duplicate and lint-like files in Linux systems. It helps identify files with identical content, as well as various forms of redundancy or lint, such as empty files, broken symbolic links, and orphaned files.
Install Rmlint on Linux
To install Rmlint in Linux, use the following command as per your Linux distribution.
$ sudo apt install rmlint [On Debian, Ubuntu and Mint] $ sudo yum install rmlint [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/rmlint [On Gentoo Linux] $ sudo apk add rmlint [On Alpine Linux] $ sudo pacman -S rmlint [On Arch Linux] $ sudo zypper install rmlint [On OpenSUSE]
4. dupeGuru – Find Duplicate Files in a Linux
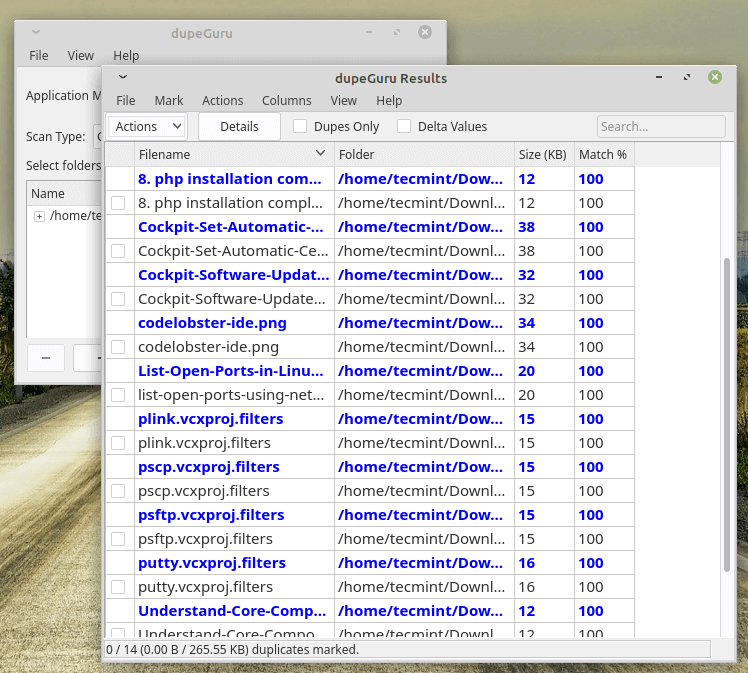
dupeGuru is an open-source and cross-platform tool that can be used to find duplicate files in a Linux system. The tool can either scan filenames or content in one or more folders. It also allows you to find the filename that is similar to the files you are searching for.
dupeGuru comes in different versions for Windows, Mac, and Linux platforms. Its quick fuzzy matching algorithm feature helps you to find duplicate files within a minute. It is customizable, you can pull the exact duplicate files you want to, and Wipeout unwanted files from the system.
Install dupeGuru on Linux
To install dupeGuru in Linux, use the following command as per your Linux distribution.
$ sudo apt install dupeguru [On Debian, Ubuntu and Mint] $ sudo yum install dupeguru [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/dupeguru [On Gentoo Linux] $ sudo apk add dupeguru [On Alpine Linux] $ sudo pacman -S dupeguru [On Arch Linux] $ sudo zypper install dupeguru [On OpenSUSE]
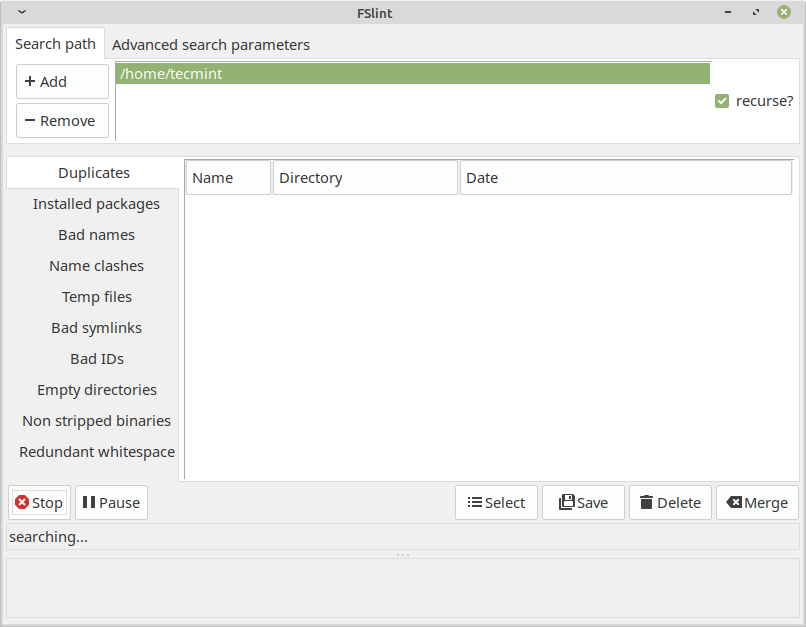
5. FSlint – Duplicate File Finder for Linux
FSlint is a free utility that is used to find and clean various forms of lint on a filesystem. It also reports duplicate files, empty directories, temporary files, duplicate/conflicting (binary) names, bad symbolic links, and many more. It has both command-line and GUI modes.
However, it’s important to note that as of my knowledge cutoff in September 2022, FSlint was last updated in 2013 and may not be actively maintained or compatible with newer Linux distributions.
Install FSlint on Linux
To install FSlint in Linux, use the following command as per your Linux distribution.
$ sudo apt install fslint [On Debian, Ubuntu and Mint] $ sudo yum install fslint [On RHEL/CentOS/Fedora and Rocky/AlmaLinux] $ sudo emerge -a sys-apps/fslint [On Gentoo Linux] $ sudo apk add fslint [On Alpine Linux] $ sudo pacman -S fslint [On Arch Linux] $ sudo zypper install fslint [On OpenSUSE]
Conclusion
These are very useful tools to find duplicated files on your Linux system, but you should be very careful when deleting such files.
If you are unsure if you need a file or not, it would be better to create a backup of that file and remember its directory prior to deleting it. If you have any questions or comments, please submit them in the comment section below.