- Remove duplicate files in multiple folders [closed]
- 4 Answers 4
- How to Find Duplicate Files in Linux and Remove Them
- FSlint: GUI tool to find and remove duplicate files
- FDUPES: CLI tool to find and remove duplicate files
- Installation on Debian / Ubuntu
- Installation on Fedora
- Final Words
- How to compare text files and delete duplicates (Linux terminal commands)
- 3 Answers 3
Remove duplicate files in multiple folders [closed]
Want to improve this question? Update the question so it focuses on one problem only by editing this post.
I have a directory which have many sub-directories, and sub-sub-directories and so on possibly. I would like to select a particular folder say A and delete all the files from directory other than A if such files occur in both A and directory other than A . Basically I would like to remove duplication (only with reference to A ) by keeping the files in A intact. Furthermore, for all files that do not occur in A , I would like to keep only one copy in any one of the directories (possibly based on lexicographically first directory name or any other selection criteria). Please help me write the script for the same.
Are there only duplicates? No changed versions? No older/newer versions? So if a file exists in A if a file with the same name is found in B/sub1 , the files are guaranteed to be the same? Also, does A have subdirectories?
files with same name are to be reared same regardless of their location in directories. A has subdirectories, and A and other directories from which files are to be deleted can be in same depth level.
4 Answers 4
See Usage: below for examples of running this script. Note: this script has the actual delete of files commented out. To enable actually removing files, you will need to uncomment # rm «$rmfn» in the script.
Note2: to actually delete files, you must give this script a 3rd argument: -d to cause the files to be removed. If you just provide argument 1: A (path to files to save) and argument 2: pathB (path with subdirs to look for dupes in), then this script just prints duplicates found so you can verify everything is as you want before preforming the removal.
Linux application fdupes I would be remiss not to tell you that there is a common application fdupes that is designed to do just what you are wanting to do (much more flexible and thoroughly tested).
#!/bin/bash ## check input dirs both exist [ -e "$1" ] && [ -e "$2" ] || < printf "\nError: invalid path. Usage %s dirA pathB\n\n" "$" exit 1 > tmp="tmp_$(date +%s).txt" # unique temp file name [ -f "$tmp" ] && rm "$tmp" # test if already exists and del find "$2" -type f > "$tmp" # fill tmp file with possible dups for i in $(find "$1" -type f); do # check each file in A ($1) against tmp fn="$" # remove path from A/filename if grep -q "$fn" "$tmp"; then # test if A/file found in pathB ($2) if [ "$3" = -d ]; then # if 3rd arg is '-d', really delete for rmfn in $(grep "$fn" "$tmp"); do # get list of matching filenames printf " deleting: %s\n" "$rmfn" >&2 # print record of file deleted # rm "$rmfn" # the delete command (commented) done else # if no '-d', just print duplicates found printf "\n Duplicate(s) found for: %s\n\n" "$fn" grep "$fn" "$tmp" # output duplicate files found fi fi done rm "$tmp" # delete tmp file exit 0 The script requires 2 directories as input to scan for duplicates and it requires a third argument ‘-d’ to actually delete duplicates found. Example:
$ bash fdupes.sh ~/scr/utl ~/scr/rmtmp/ Duplicate found for: bay.sh /home/david/scr/rmtmp/bay.sh Duplicate found for: rsthemes.sh /home/david/scr/rmtmp/rsthemes.sh Duplicate found for: nocomment /home/david/scr/rmtmp/nocomment.sh Duplicate found for: show-rdtcli.sh /home/david/scr/rmtmp/show-rdtcli.sh /home/david/scr/rmtmp/subdir1/show-rdtcli.sh
Actually deleting duplicates (after uncommenting rm ):
$ bash fdupes.sh ~/scr/utl ~/scr/rmtmp/ -d deleting: /home/david/scr/rmtmp/bay.sh deleting: /home/david/scr/rmtmp/rsthemes.sh deleting: /home/david/scr/rmtmp/nocomment.sh deleting: /home/david/scr/rmtmp/show-rdtcli.sh deleting: /home/david/scr/rmtmp/subdir1/show-rdtcli.sh How to Find Duplicate Files in Linux and Remove Them

If you have this habit of downloading everything from the web like me, you will end up having multiple duplicate files. Most often, I can find the same songs or a bunch of images in different directories or end up backing up some files at two different places. It’s a pain locating these duplicate files manually and deleting them to recover the disk space.
If you want to save yourself from this pain, there are various Linux applications that will help you in locating these duplicate files and removing them. In this article, we will cover how you can find and remove these files in Ubuntu.
Note: You should know what you are doing. If you are using a new tool, it’s always better to try it in a virtual directory structure to figure out what it does before taking it to root or home folder. Also, it’s always better to backup your Linux system!
FSlint: GUI tool to find and remove duplicate files
FSlint helps you search and remove duplicate files, empty directories or files with incorrect names. It has a command-line as well as GUI mode with a set of tools to perform a variety of tasks.
To install FSlint, type the below command in Terminal.
Open FSlint from the Dash search.
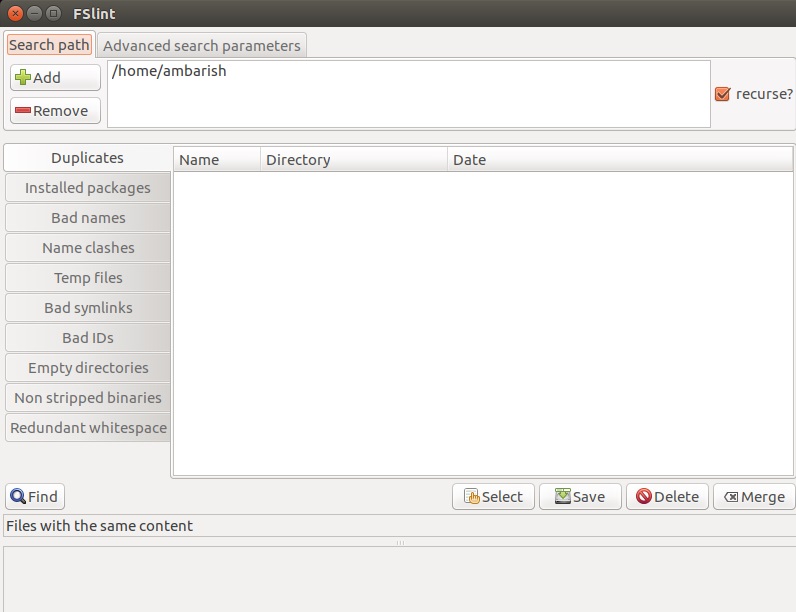
FSlint includes a number of options to choose from. There are options to find duplicate files, installed packages, bad names, name clashes, temp files, empty directories etc. Choose the Search Path and the task which you want to perform from the left panel and click on Find to locate the files. Once done, you can select the files you want to remove and Delete it.
You can click on any file directory from the search result to open it if you are not sure and want to double check it before deleting it.
You can select Advanced search parameters where you can define rules to exclude certain file types or exclude directories which you don’t want to search.
FDUPES: CLI tool to find and remove duplicate files
FDUPES is a command line utility to find and remove duplicate files in Linux. It can list out the duplicate files in a particular folder or recursively within a folder. It asks which file to preserve before deletion and the noprompt option lets you delete all the duplicate files keeping the first one without asking you.
Installation on Debian / Ubuntu
Installation on Fedora
Once installed, you can search duplicate files using the below command:
For recursively searching within a folder, use -r option
This will only list the duplicate files and do not delete them by itself. You can manually delete the duplicate files or use -d option to delete them.
This won’t delete anything on its own but will display all the duplicate files and gives you an option to either delete files one by one or select a range to delete it. If you want to delete all files without asking and preserving the first one, you can use the noprompt -N option.
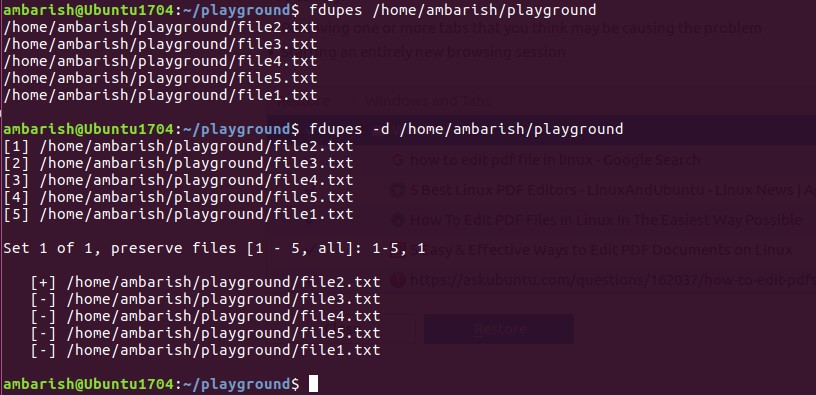
In the above screenshot, you can see the -d command showing all the duplicate files within the folder and asking you to select the file which you want to preserve.
Final Words
There are many other ways and tools to find and delete duplicate files in Linux. Personally, I prefer the FDUPES command line tool; it’s simple and takes no resources.
How do you deal with the finding and removing duplicate files in your Linux system? Do tell us in the comment section.
How to compare text files and delete duplicates (Linux terminal commands)
I have entered the following at the command terminal:
diff -qrs ./dir_one/data.txt ./dir_two/data.txt and I receive the following message:
Files ./dir_one/data.txt ./dir_two/data.txt are identical. Now that I know that the two text files are identical, I can use the rm command to remove one of them. So far, so good. However.
The problem is that I want to automate the deletion process. I do not want to have to enter the rm at the command line. Is there any possible way to do this — in a script, for example?
I would also like to know how to compare a large set of text files in one directory against a large set of text files in another directory. Again, for any files found to be identical, one of the duplicates should be deleted. Is this possible too?
I’ve found similar questions, but none about automating the deletion of the one of the duplicate files. Note that I’m using ubuntu 12.04.
3 Answers 3
fdupes -r /some/directory/path > /some/directory/path/fdupes.log diff returns exit status 0 if the files are the same, 1 if they’re different, and 2 if there is an error. You can use that to decide to execute the rm command
diff file1 file2 && rm file2 Thanks, @Jim Garrison. This looks like what I’m after. Could you tell me if this would work in the situation of recursively comparing files in subdirectories, i.e. when specifying the option: -r? Cheers.
You would need to run each comparison in its own process. I suspect if you run it with -r the result will be zero if all the files are equal, and non-zero if any are different.
Here’s a script I initially wrote some time ago and polished recently. You should run it from the directory you want to deduplicate. It will place all duplicates in a directory outside of the «cleaned» directory:
#!/bin/bash # this script walks through all files in the current directory, # checks if there are duplicates (it compares only files with # the same size) and moves duplicates to $duplicates_dir. # # options: # -H remove hidden files (and files in hidden folders) # -n dry-run: show duplicates, but don't remove them # -z deduplicate empty files as well while getopts "Hnz" opts; do case $opts in H) remove_hidden="yes";; n) dry_run="yes";; z) remove_empty="yes";; esac done # support filenames with spaces: IFS=$(echo -en "\n\b") working_dir="$PWD" working_dir_name=$(echo $working_dir | sed 's|.*/||') # prepare some temp directories: filelist_dir="$working_dir/../$working_dir_name-filelist/" duplicates_dir="$working_dir/../$working_dir_name-duplicates/" if [[ -d $filelist_dir || -d $duplicates_dir ]]; then echo "ERROR! Directories:" echo " $filelist_dir" echo "and/or" echo " $duplicates_dir" echo "already exist! Aborting." exit 1 fi mkdir $filelist_dir mkdir $duplicates_dir # get information about files: find -type f -print0 | xargs -0 stat -c "%s %n" | \ sort -nr > $filelist_dir/filelist.txt if [[ "$remove_hidden" != "yes" ]]; then grep -v "/\." $filelist_dir/filelist.txt > $filelist_dir/no-hidden.txt mv $filelist_dir/no-hidden.txt $filelist_dir/filelist.txt fi echo "$(cat $filelist_dir/filelist.txt | wc -l)" \ "files to compare in directory $working_dir" echo "Creating file list. " # divide the list of files into sublists with files of the same size while read string; do number=$(echo $string | sed 's/\..*$//' | sed 's/ //') filename=$(echo $string | sed 's/.[^.]*\./\./') echo $filename >> $filelist_dir/size-$number.txt done < "$filelist_dir/filelist.txt" # plough through the files for filesize in $(find $filelist_dir -type f | grep "size-"); do if [[ -z $remove_empty && $filesize == *"size-0.txt" ]]; then continue fi filecount=$(cat $filesize | wc -l) # there are more than 1 file of particular size -># these may be duplicates if [ $filecount -gt 1 ]; then if [ $filecount -gt 200 ]; then echo "" echo "Warning: more than 200 files with filesize" \ $(echo $filesize | sed 's|.*/||' | \ sed 's/size-//' | sed 's/\.txt//') \ "bytes." echo "Since every file needs to be compared with" echo "every other file, this may take a long time." fi for fileA in $(cat $filesize); do if [ -f "$fileA" ]; then for fileB in $(cat $filesize); do if [ -f "$fileB" ] && [ "$fileB" != "$fileA" ]; then # diff will exit with 0 iff files are the same. diff -q "$fileA" "$fileB" 2> /dev/null > /dev/null if [[ $? == 0 ]]; then # detect if one filename is a substring of another # so that in case of foo.txt and foo(copy).txt # the script will remove foo(copy).txt # supports filenames with no extension. fileA_name=$(echo $fileA | sed 's|.*/||') fileB_name=$(echo $fileB | sed 's|.*/||') fileA_ext=$(echo $fileA_name | sed 's/.[^.]*//' | sed 's/.*\./\./') fileB_ext=$(echo $fileB_name | sed 's/.[^.]*//' | sed 's/.*\./\./') fileA_name="$" fileB_name="$" if [[ $fileB_name == *$fileA_name* ]]; then echo " $(echo $fileB | sed 's|\./||')" \ "is a duplicate of" \ "$(echo $fileA | sed 's|\./||')" if [ "$dry_run" != "yes" ]; then mv --backup=t "$fileB" $duplicates_dir fi else echo " $(echo $fileA | sed 's|\./||')" \ "is a duplicate of" \ "$(echo $fileB | sed 's|\./||')" if [ "$dry_run" != "yes" ]; then mv --backup=t "$fileA" $duplicates_dir fi fi fi fi done fi done fi done rm -r $filelist_dir if [ "$dry_run" != "yes" ]; then echo "Duplicates moved to $duplicates_dir." fi