- How to delete from a text file, all lines that contain a specific string?
- AWK
- Ruby (1.9+)
- Perl
- Shell (bash 3.2 and later)
- GNU grep
- Sed Command to Delete a Line
- Sed on Linux
- Deleting line using sed
- Delete single line
- Delete a range of line
- Delete multiple lines
- Delete all lines except specified range
- Delete empty lines
- Delete lines based on pattern
- Delete lines starting with a specific character
- Delete lines ending with specific character
- Deleting lines that match the pattern and the next line
- Deleting line from the pattern match to the end
- Final thought
- About the author
- Sidratul Muntaha
- Remove line of text from multiple files in Linux
- 5 Answers 5
- Linked
- Related
- Hot Network Questions
- Subscribe to RSS
How to delete from a text file, all lines that contain a specific string?
To remove the line and print the output to standard out:
sed '/pattern to match/d' ./infile To directly modify the file – does not work with BSD sed:
sed -i '/pattern to match/d' ./infile Same, but for BSD sed (Mac OS X and FreeBSD) – does not work with GNU sed:
sed -i '' '/pattern to match/d' ./infile To directly modify the file (and create a backup) – works with BSD and GNU sed:
sed -i.bak '/pattern to match/d' ./infile With GNU sed 4,2,2, the -i » doesn’t work at all. It then treats the pattern to match as the filename. Just remove the ».
Note that if your pattern will contain forward slashes, you can use an alternate pattern delimiter but must then escape the first one, e.g.: sed -i.bak «\#$pattern_variable_containing_slashes#d» ./infile
There are many other ways to delete lines with specific string besides sed :
AWK
awk '!/pattern/' file > temp && mv temp file Ruby (1.9+)
ruby -i.bak -ne 'print if not /test/' file Perl
perl -ni.bak -e "print unless /pattern/" file Shell (bash 3.2 and later)
while read -r line do [[ ! $line =~ pattern ]] && echo "$line" done o mv o file GNU grep
grep -v "pattern" file > temp && mv temp file And of course sed (printing the inverse is faster than actual deletion):
how to delete a particular line with a pattern and also the line immediately above it? I have a fine with thousands of such lines in between different data.
On OS/X, the shell variation doesn’t preserve leading spaces, but the grep -v variation worked well for me.
the sed example have a different behaviour, it only greps! it should be something like sed -n -i ‘/pattern/!p’ file .
The grep version does not work when every line matches the pattern. Better do: grep -v «pattern» file > temp; mv temp file This might apply to some of the other examples depending on the return value.
«printing the inverse is faster than actual deletion» — Not on my machine (2012 MacBook Air, OS X 10.13.2). Create file: seq -f %f 10000000 >foo.txt . sed d: time sed -i » ‘/6543210/d’ foo.txt real 0m9.294s. sed !p: time sed -i » -n ‘/6543210/!p’ foo.txt real 0m13.671s. (For smaller files, the difference is larger.)
You can use sed to replace lines in place in a file. However, it seems to be much slower than using grep for the inverse into a second file and then moving the second file over the original.
grep -v "pattern" filename > filename2; mv filename2 filename The first command takes 3 times longer on my machine anyway.
I’m curious what the performance difference would be if it were sed ‘/pattern/d’ filename > filename2; mv filename2 filename
(using ubuntu’s /usr/share/dict/words) grep and mv: 0.010s | sed in place: 0.197s | sed and mv: 0.031s
The easy way to do it, with GNU sed :
sed --in-place '/some string here/d' yourfile A handy tip for others who stumble on this Q&A thread and are new to shell scripting: Short options are fine for one-time uses on the command line, but long options should be preferred in scripts since they’re more readable.
+1 for the —in-place flag. I need to test that out on permissions protected files. (have to do some user scrubbing.)
Note that the long option is only available on GNU sed. Mac and BSD users will need to install gsed to do it this way.
Another tip: if your regex doesn’t appear to match, try the -r option (or -E , depending on your version). This enables the use of regex metacharacters + , ? , <. >and (. ) .
This is the correct answer when your disk no have more space and you can’t copy the text to another file. This command do what was questioned?
You may consider using ex (which is a standard Unix command-based editor):
- + executes given Ex command ( man ex ), same as -c which executes wq (write and quit)
- g/match/d — Ex command to delete lines with given match , see: Power of g
The above example is a POSIX-compliant method for in-place editing a file as per this post at Unix.SE and POSIX specifications for ex .
The difference with sed is that:
sed is a Stream EDitor, not a file editor. BashFAQ
Unless you enjoy unportable code, I/O overhead and some other bad side effects. So basically some parameters (such as in-place/ -i ) are non-standard FreeBSD extensions and may not be available on other operating systems.
that’s great. when I do man ex it gives me the man for vim , it seems ex is part of vim. if I understood right that means the pattern syntax for match is vimregex.com which is similar but different to POSIX and PCRE flavours?
@kenorb «I/O overhead and some other bad side effects» could you elaborate? AFAIK ex is using a temp file, just like every other sane tool, besides idk using dd
I was struggling with this on Mac. Plus, I needed to do it using variable replacement.
where $file is the file where deletion is needed and $pattern is the pattern to be matched for deletion.
The thing to note here is use of double quotes in «/$pattern/d» . Variable won’t work when we use single quotes.
Mac sed requires a parameter after -i , so if you don’t want a backup, you still have to add an empty string: -i »
Here -v will print only other than your pattern (that means invert match).
To get a inplace like result with grep you can do this:
echo "$(grep -v "pattern" filename)" >filename I have made a small benchmark with a file which contains approximately 345 000 lines. The way with grep seems to be around 15 times faster than the sed method in this case.
I have tried both with and without the setting LC_ALL=C, it does not seem change the timings significantly. The search string (CDGA_00004.pdbqt.gz.tar) is somewhere in the middle of the file.
Here are the commands and the timings:
time sed -i "/CDGA_00004.pdbqt.gz.tar/d" /tmp/input.txt real 0m0.711s user 0m0.179s sys 0m0.530s time perl -ni -e 'print unless /CDGA_00004.pdbqt.gz.tar/' /tmp/input.txt real 0m0.105s user 0m0.088s sys 0m0.016s time (grep -v CDGA_00004.pdbqt.gz.tar /tmp/input.txt > /tmp/input.tmp; mv /tmp/input.tmp /tmp/input.txt ) real 0m0.046s user 0m0.014s sys 0m0.019s Sed Command to Delete a Line
![]()
Sed is a built-in Linux tool for text manipulation. The term sed stands for stream editor. Despite the name, sed isn’t a text editor by itself. Rather, it takes text as input, performs various text modifications according to instructions, and prints the output.
This guide will demonstrate how to use sed to delete a line from a text.
Sed on Linux
The full name of sed gives us a hint at its working method. Sed takes the input text as a stream. The text can come from anywhere – a text file or standard output (STDOUT). After taking the input, sed operates on it line by line.
For demonstration, here’s a simple text file I’ve generated.
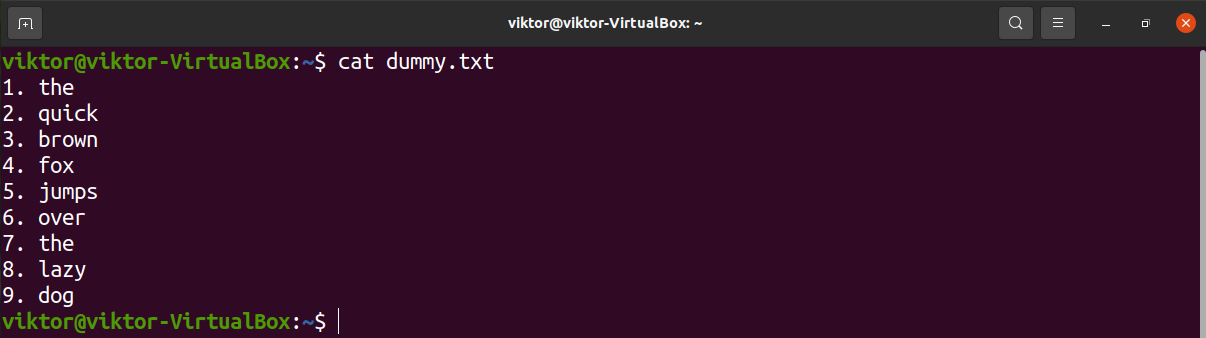
Deleting line using sed
To delete a line, we’ll use the sed “d” command. Note that you have to declare which line to delete. Otherwise, sed will delete all the lines.
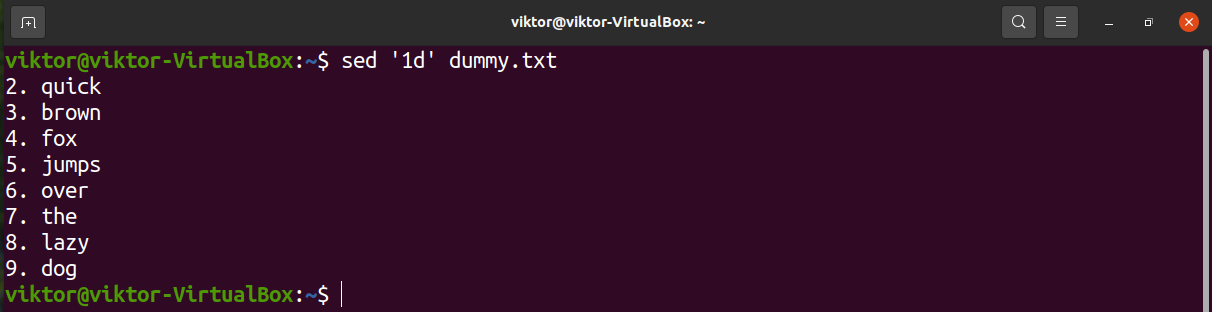
Delete single line
The following sed command will delete the first line of the text.
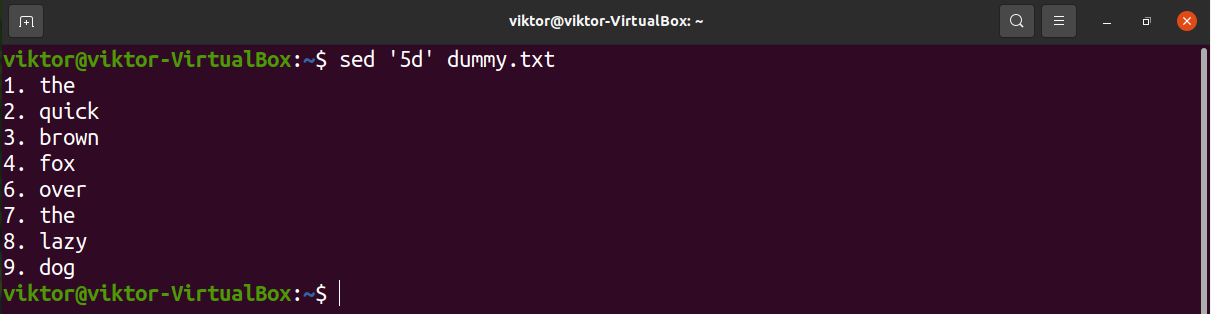
Basically, to delete a line, you need the line number of the target line. Let’s remove line 5.
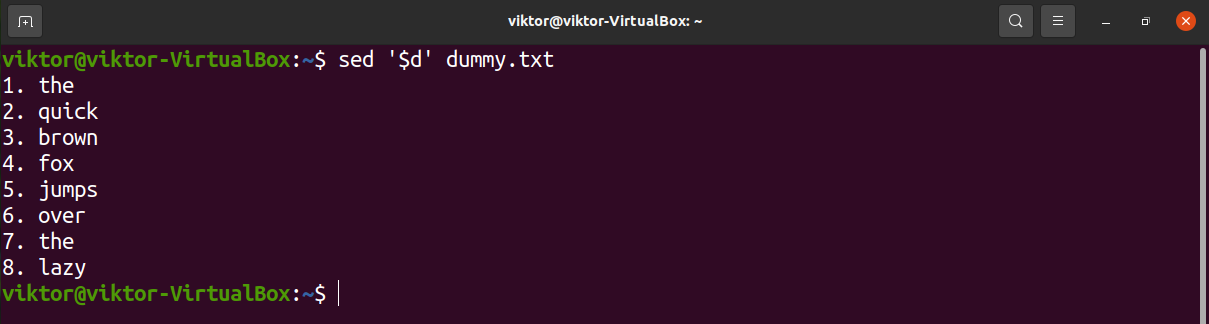
To delete the last line of the text file, instead of manually calculating the line number, use “$” instead.
Delete a range of line
Sed can delete a range of lines. Here, the minimum line value is 1, and the maximum line value is 5. To declare range, we’re using comma (,).

Delete multiple lines
What if the lines you desire to remove are not in a fixed range? Have a look at the following sed command. Note that we’re using a semicolon (;) as the delimiter. Essentially, each delimited option is a separate sed command.

Delete all lines except specified range
In the next example, sed will only keep the lines described by the range. Here, “!” is the negation operator, telling sed to keep the specific lines.

Delete empty lines
If there are multiple empty or blank lines in the text, the following sed command will remove all of them.
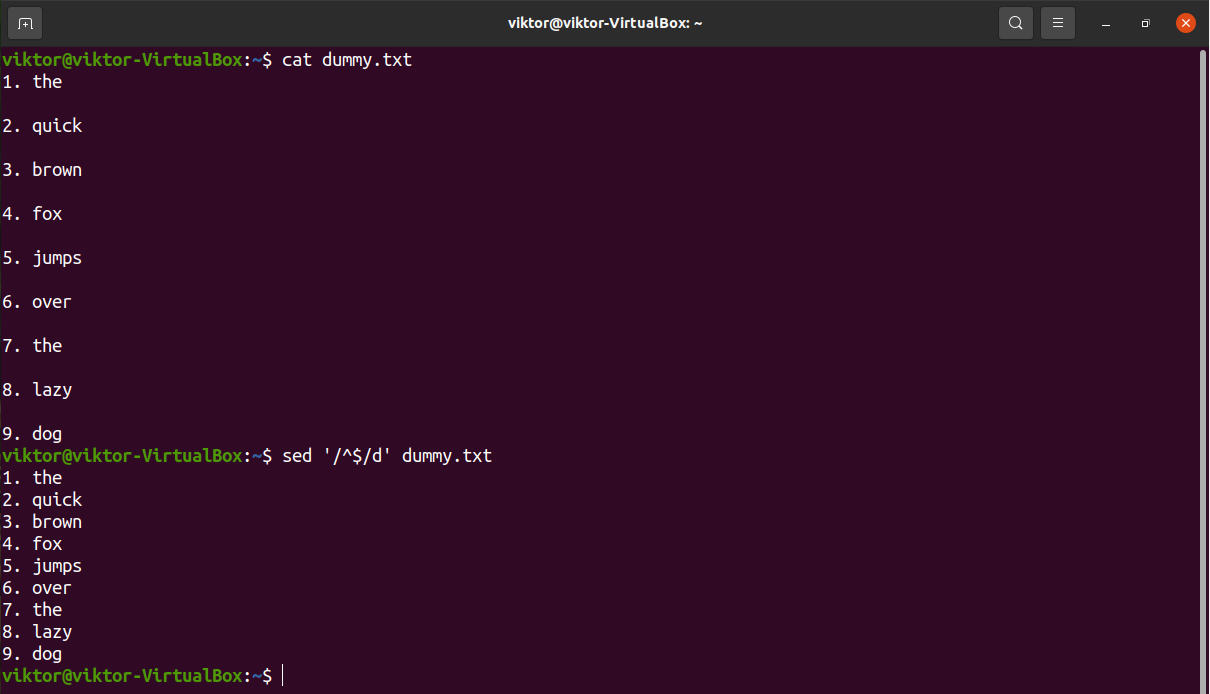
Delete lines based on pattern
Sed can search for a particular pattern and perform the specified actions on the line. We can use this feature to delete specific lines that match a pattern.
Let’s have a look at the following demonstration. Sed will remove any line that contains the string “the”.
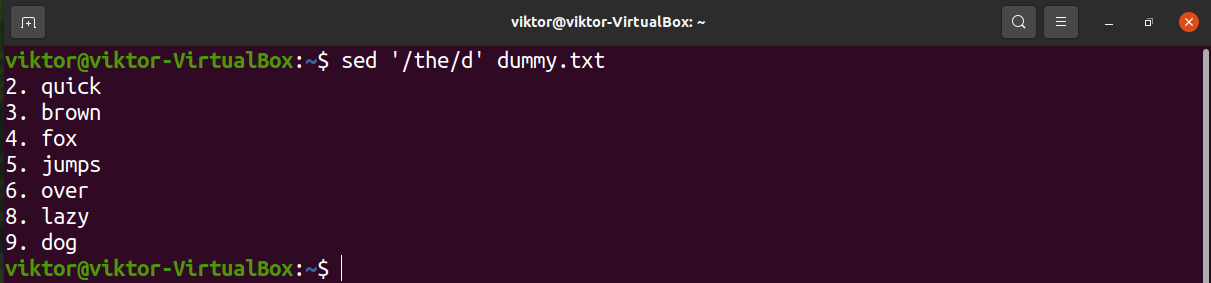
We can also describe multiple strings to search for. Each string is delimited using the symbol “\|”.

Delete lines starting with a specific character
To denote the starting of a line, we’ll use the caret (^) symbol.
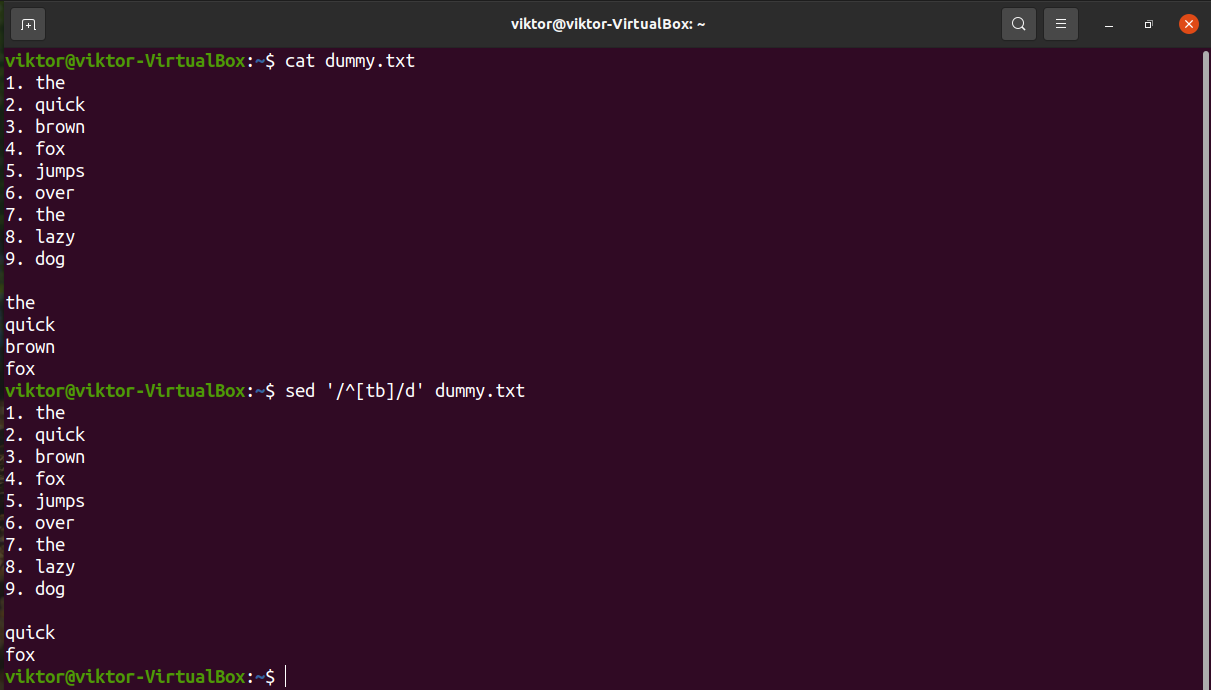
The following sed command will remove all the lines starting with a digit. Here, the character group “[:digit:]” describes all digits (0-9).

We can also describe multiple characters for a valid match. The following example will match all the lines that start with “t” and “b”.
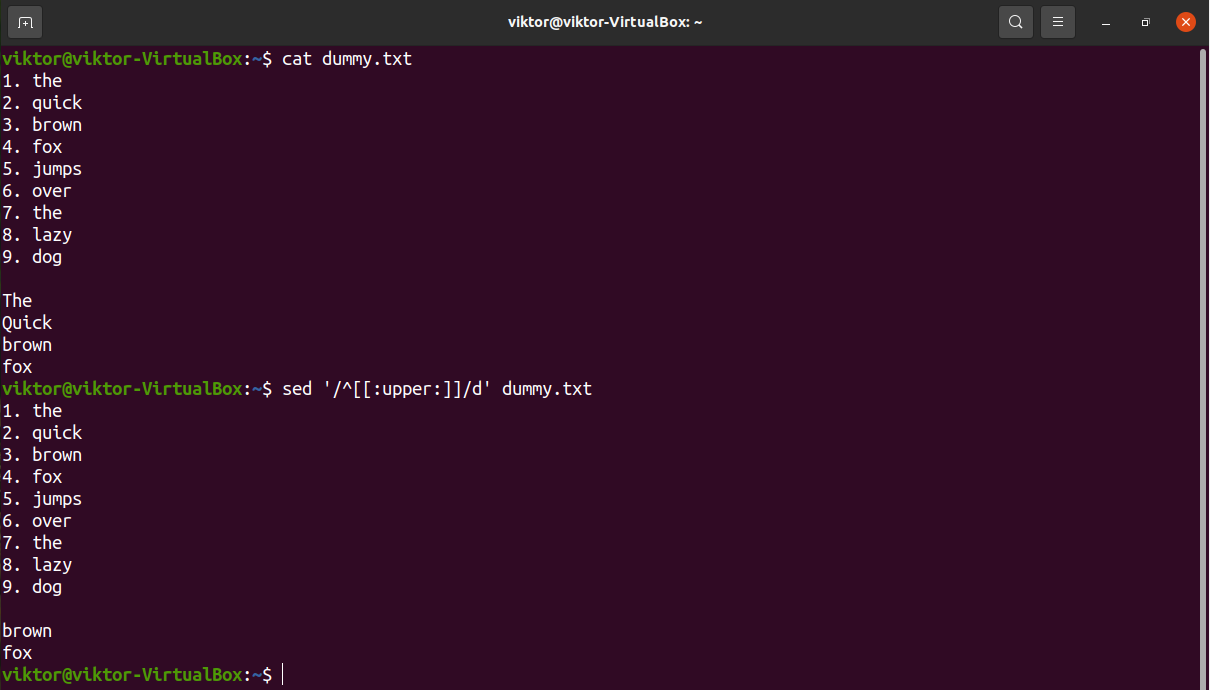
In the next example, check out how to remove all the lines that start with an uppercase character. Here, we’re using the uppercase character group “[:upper:]”.
If the target lines have lowercase characters at the start, use the lowercase character group “[:lower:]”.
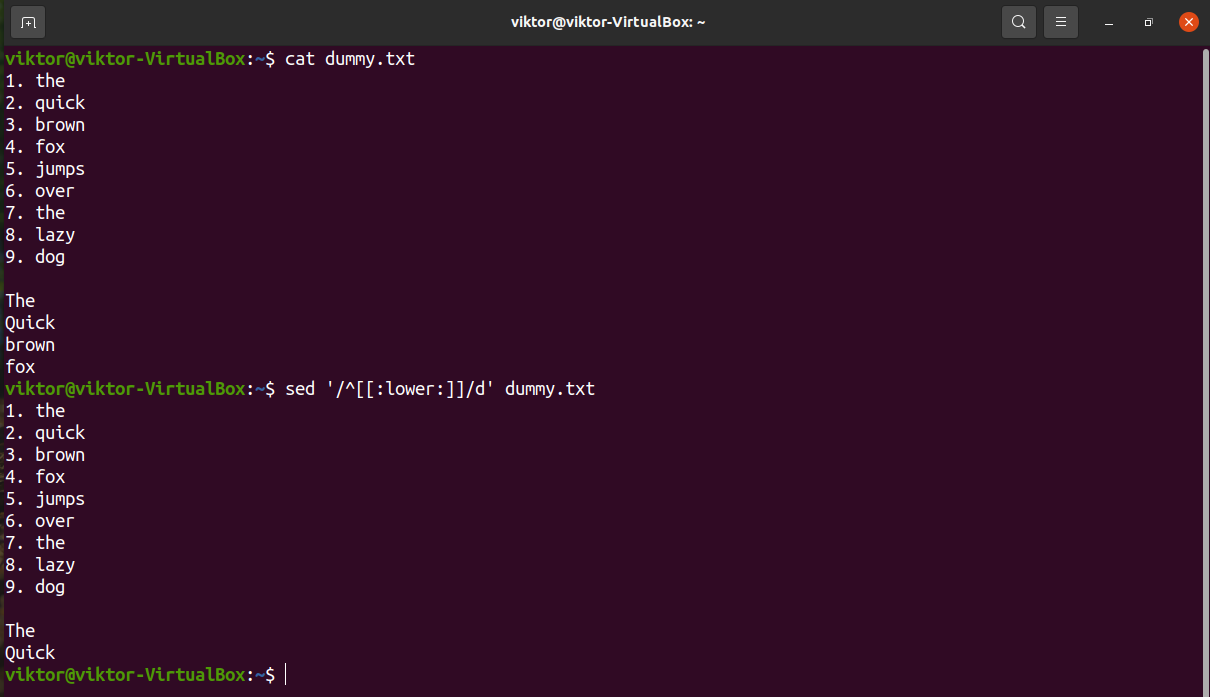
Delete lines ending with specific character
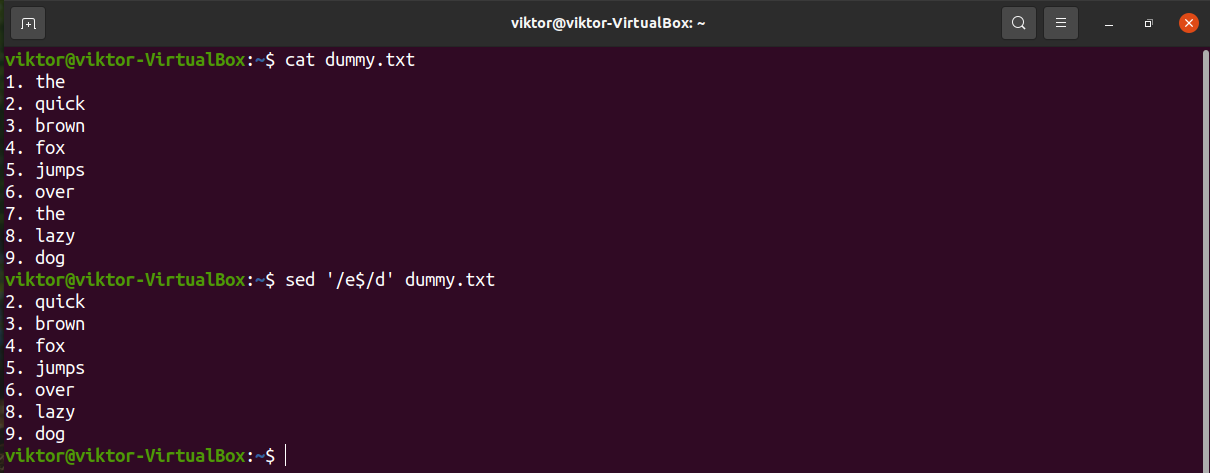
To denote the end of a line, we can use the symbol “$”. It describes the match with the last occurrence of the pattern.
In the next example, sed will delete lines ending with “e”.
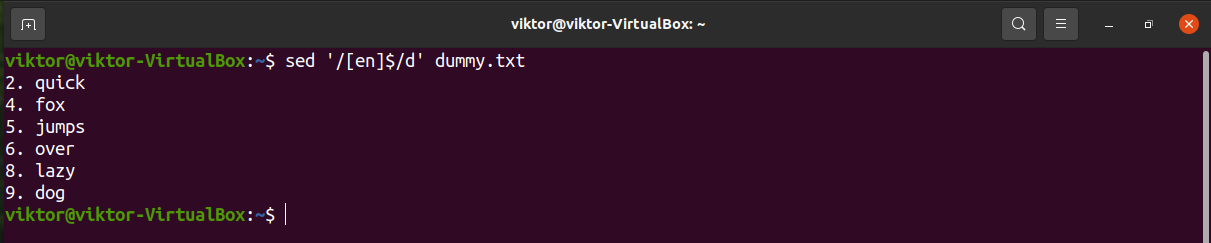
Let’s try with a multiple-character search.
Deleting lines that match the pattern and the next line
We’ve already demonstrated how to delete a line if a pattern matches. We can further extend and delete the subsequent line as well.
Check out the following sed command.

Sed will match the line that contains “the” and delete the subsequent line as well.
Deleting line from the pattern match to the end
We can further extend the previous example to order sed to delete all the lines, starting from the first match of the pattern.

Here, sed will delete the line that matches the pattern “the” first and all lines afterward.
Final thought
Sed is a simple tool. However, it can do wonders, thanks to the support for regular expression. Sed also integrates seamlessly in various scripts.
This was just a short guide demonstrating one of the sed functions – deleting lines. There are tons of other things you can do with sed. For example, check out this mega guide on 50 sed examples. It’s a fantastic guide covering all the basics and many advanced sed implementations.
About the author
Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Remove line of text from multiple files in Linux
Is there a simple way to remove the same line of text from a folder full of text documents at the command line?
5 Answers 5
If your version of sed allows the -i.bak flag (edit in place):
If not, simply put it in a bash loop:
for file in *.txt do sed '/line of text/d' "$file" > "$file".new_file.txt done $(ls *.txt) is stupid (forks extra process, can’t handle spaces in filenames). try for file in *.txt instead
To find a pattern and remove the line containing the pattern below command can be used
find . -name "*" -type f | xargs sed -i -e '//d' Example : if you want to remove the line containing word sleep in all the xml files
find . -name "*.xml" -type f | xargs sed -i -e '/sleep/d' NOTE : Be careful before choosing a pattern as it will delete the line recursively in all the files in the current directory hierarchy 🙂
for thefile in *.txt ; do grep -v "text to remove" $thefile > $thefile.$$.tmp mv $thefile.$$.tmp $thefile done Grep -v shows all lines except those that match, they go into a temp file, and then the tmpfile is moved back to the old file name.
perl -ni -e 'print if not /mystring/' * This tells perl to loop over your file (-n), edit in place (-i), and print the line if it does not match your regular expression.
Somewhat related, here’s a handy way to perform a substitution over several files.
perl -pi -e 's/something/other/' * From this link: both perl and sed are traditional NFA engines, so theoretically they shouldn’t differ to greatly in their performance, but in reality perl has a large number of optimisations applied that make it perform well in common cases.
I wrote a Perl script for this:
#!/usr/bin/perl use IO::Handle; my $pat = shift(@ARGV) or die("Usage: $0 pattern files\n"); die("Usage $0 pattern files\n") unless @ARGV; foreach my $file (@ARGV) < my $io = new IO::Handle; open($io, $file) or die("Cannot read $file: $!\n"); my @file = ; close($io); foreach my $line (@file) < if($line =~ /$pat/o) < $line = ''; $found = 1; last; >> if($found) < open($io, ">$file") or die("Cannot write $file: $!\n"); print $io @file; close($io); > > Note that it removes lines based on a regex. If you wanted to do exact match, the inner foreach would look like:
Linked
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.7.12.43529
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.