Приручение черного дракона. Этичный хакинг с Kali Linux. Часть 8. Методы и средства внешней разведки
Полный список статей прилагается ниже, и будет дополняться по мере появления новых.
Приручение черного дракона. Этичный хакинг с Kali Linux:
В одной из прошлых частей мы затронули первую фазу любой атаки, именуемую футпринтингом (footprinting) и разобрали несколько простых примеров сбора информации об объекте расположенном в локальной сети. Однако, мы так и не рассмотрели подробно методы и средства для проведения внешней разведки, и сбора информации. Самое время это исправлять! Поэтому данная статья будет полностью посвящена именно этой теме.
Думаю, что тебе часто попадалась на глаза аббревиатура OSINT (open-source intelligence), являющая собой миру отдельное направление, посвященное сбору информации из открытых источников. В рамках данной статьи я попытаюсь наглядно продемонстрировать каким образом злоумышленник проводит первичный сбор информации из открытых источников о цели и какие инструменты в составе Kali нам в этом помогут. В качестве примера я буду проводить сбор информации о коммерческом Банке с которым у меня заключен договор.
Первое что нам нужно знать о цели это название организации, ее род деятельности и публичный домен к которому может быть привязан веб-сайт или любой другой публичный ресурс. Тут без комментариев. Яндекс, Google, DuckDuckGo… поисковыми системами учить пользоваться человека, читающего статью по OSINT думаю нет смысла.
И так на момент начала мы знаем о цели все вышеперечисленное, для манипуляций единственное, что нам доступно в работе это доменное имя веб-сайта организации (пусть будет blahblah.su). Инструменты которые нам в этом помогут, это WHOIS, TheHarvester, SpiderFoot, и recon-ng. Все они есть в составе Kali, а значит нам не придется ничего тянуть из репозиториев GitHub и заниматься прочей ахинеей. Немного нудного отступления ради лучшего знакомства с каждым из вышеперечисленных инструментов.
WHOIS — простой и в тоже время очень мощный инструмент, позволяющий по доменному имени либо публичному IP адресу получить подробную информацию как о владении доменами, так и о владельцах. Запись whois содержит всю контактную информацию, связанную с человеком, компанией или другим лицом, зарегистрировавшим доменное имя.
TheHarvester — представляющий из себя мощный фреймворк для сбора e-mail адресов, имён субдоменов, виртуальных хостов, открытых портов/банеров и имён сотрудников компании из различных открытых источников.
SpiderFoot — инструмент с открытым исходным кодом для автоматизированной разведки. Его цель — автоматизировать процесс сбора информации о заданной цели.
Есть три главных сферы, где может быть полезен SpiderFoot:
1) Если вы тестировщик на проникновение, SpiderFoot автоматизирует стадию сбора информации по цели, даст вам богатый набор данных чтобы помочь вам определить направления деятельности для теста.
2) Для понимания, что ваша сеть/организация открыта на показ для внешнего мира. Эта информация в плохих руках может представлять значительный риск.
3) SpiderFoot также может быть использован для сбора информации о подозрительных вредоносных IP, которые вы могли видеть в ваших логах или получили через каналы разведки угроз.
Recon-ng — это полнофункциональный фреймвок веб-разведки, написанный на Python. В комплекте независимые модули, взаимодействие с базой данных, удобные встроенные функции, интерактивная помощь и завершение команд. Recon-ng обеспечивает мощное окружение, в котором разведка на основе открытых веб-источников может быть проведена быстро и тщательно.
После краткой информации о нашем сегодняшнем инструментарии, мы можем продолжать и первым нашим инструментом будет whois в который мы просто передадим параметр доменного имени (blahblah.su) и посмотрим, что он нам выдаст.

Поиск данных связанных с доменным именем выдал нам следующие результаты: Полное наименование организации, контактный телефон сотрудника, на которого зарегистрировано доменное имя (администратора домена), его email (что в корне неверно, обычно указывается рабочий номер техотдела, и email типа info@mail.blahblah.su). Так же тут есть информация о хостинге (jino.ru) и регистраторе домена верхнего уровня (.su)
Не так уж и мало для начала. Двигаемся дальше и попробуем в деле следующий инструмент theHarvester. Для того, чтобы запустить проверку, помимо параметра домена, необходимо указать параметр системы, через которую будет осуществляться сбор данных. Для части из них нужны API ключи, но мы рассмотрим лишь те, что работают без API.
Для получения подробной информации можно ввести команду theHarvester -h

Для получения информации об IP адресах и связанных доменах используем dnsdumpster, rapiddns и urlscan. Введем поочередно команды:
theHarvester –d blahblah.su –b dnsdumpster
theHarvester –d blahblah.su –b rapiddns
theHarvester –d blahblah.su –b urlscan



И тут картина становится гораздо интереснее. TheHarvester вытаскивает нам все связанные с данным доменом ресурсы компании: почтовый сервер, iBank клиент, и гейт vmware horizon, а так же публичные IP адреса. Двинемся дальше и посмотрим, что еще нам удастся найти при помощи следующего инструмента SpiderFoot. В отличие от всех инструментов которые будут обозреваться в данной статье, SpiderFoot дает возможность работать через веб-интерфейс, что возможно будет поприятнее любителям графических оболочек.
Для начала запустим SpiderFoot как веб-сервер на адресе нашей машины с Kali следующей командой:

Теперь перейдем по ссылке в поле browse to http://127.0.0.1:8080/
Перед нами откроется следующее окно:

Для того, чтобы начать новое сканирование, необходимо перейти во вкладку New Scan

Здесь нам необходимо задать имя цели (наименование организации либо ее доменное имя), а также публичный IP адрес либо целевой домен. Ниже у нас есть выбор типа сбора данных:
All – режим включающий в работу все модули spiderfoot для того, чтобы получить все возможные данные о цели (тот самый вариант «однокнопачного» приложения по принципу «сделай все возможное»). Ввиду того, что данный режим очень медленно работает и несет с собой порой кучу лишнего мусора, редко когда им приходится пользоваться.
Footprint – режим который подойдет для классической разведки и сбора данных о периметре сети, связанных идентификаторах и прочей информации. В данном способе задействуется большое количество различных веб-сканеров и поисковых систем.
Investigate — данный режим больше подходит в случаях расследования инцидента, когда есть подозрение на то, что целевой адрес/домен является вредоносным, но вам нужна дополнительная информация о нем. Преимуществом данного режима сканирования является его работа с запросами черных списков и других источников которые могут содержать информацию о злонамеренности целевого ресурса.
Passive – пассивный сбор информации о цели из открытых источников, применяемый в том случае, когда есть необходимость собрать минимально полезные данные не применяя режима агрессивного сканирования.
Тут список весьма внушительный, так что перечислю лишь некоторые параметры: IP адреса, доменные имена, почтовые адреса, данные о компании (физический адрес, номера телефонов и т.д.).

Стоит обратить внимание на то, что некоторая часть модулей для работы требуют API ключа сервиса (например, такие как shodan, emailrep, focsec и пр.), но тем не менее, большая часть из них готовы к работе без необходимости выполнения дополнительных действий. При желании можно зарегистрироваться на таких сервисах как shodan.io и получить API бесплатно.

Что ж, не будем долго задерживаться на знакомстве с интерфейсом SpiderFoot, и перейдем от слов к делу. Выберем режим сканирования Footprint зададим имя цели и в качестве целевого источника укажем домен (blahblah.su), жмем Run Scan Now и идем варить себе кофе, пока наш «паук» будет плести свои нити…

В итоге, вернувшись к компьютеру с дымящейся кружкой горячего кофе, мы обнаружим примерно следующую картину

Все красиво, с графиками и разложено по полочкам, только кликни дважды по нужному пункту (например, перейдем в Linked URL — Internal)

И тут у нас спалилась CMS 1С Битрикс, на базе которой работает сайт компании. Причем, путь к стандартной админке www.blahblah.su/bitrix/ оказался открыт

Для большего удобства работы мы можем сменить режимы отображения на Browse


Следующим нашим инструментом с которым мы познакомимся в рамках данной темы будет фреймворк recon-ng. Из всех рассмотренных инструментов, recon-ng единственный который не содержит изначально никаких модулей в составе. Так что первым долгом мы установим все модули необходимые для полноценной работы фреймворка и создадим рабочую область.
Для запуска самого фреймворка достаточно прописать в консоли recon-ng, а для получения информации о доступных опциях help.

Далее обновим базу marketplace командой marketplace refresh и установим все доступные компоненты командой

После завершения установки создадим новую рабочую область и БД для хранения данных по конкретному домену. Введем help для отображения доступных команд создадим новую область командой
workspaces create blahblah

и добавим базу доменов blahblah.su

Теперь мы готовы начинать работать. И для начала загрузим список доступных модулей для работы с доменами командой
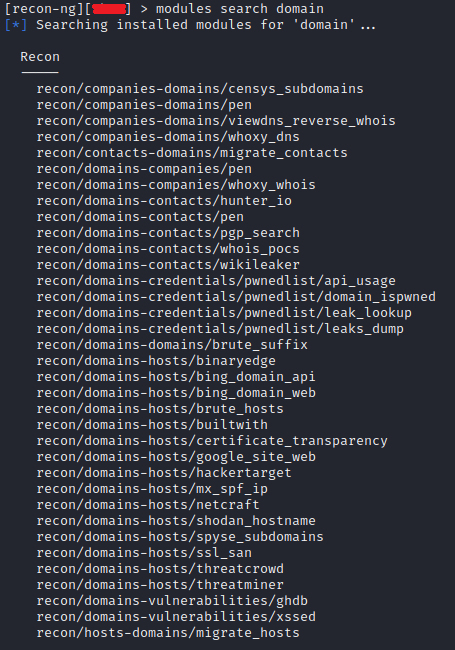
Из доступного списка загрузим модуль
modules load recon/domains-hosts/brute_hosts
и запустим его командой run
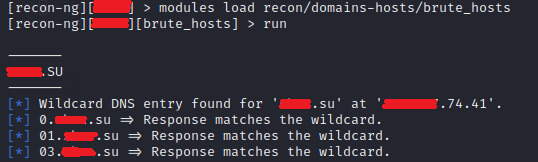


Тут мы видим те же данные ресурсов и их публичные адреса, что и при работе с theHarvester. Для примера перейдем по одному из публичных адресов и попадем на страницу приложения iBank.

Попробуем другой модуль вернувшись в предыдущее меню командой back

Загрузим модуль recon/domains-hosts/hackertarget и посмотрим, что ему удастся вытащить интересного

И так, подведем итоги. Начиналось все с того, что мы знали лишь наименование организации, ее род деятельности и доменное имя адреса веб-сайта. На данный момент у нас есть информация обо всех публичных ресурсах организации (почтовик, веб-сайт, приложение iBank, адрес гейта vmware horizon), есть информация об именах некоторых сотрудников, их адреса корпоративной почты, номера рабочих телефонов. В руках опытных злоумышленников этого уже достаточно для проведения успешных сценариев социальной инженерии, не говоря об остальных способах. Именно поэтому, очень важно стараться минимизировать публикацию подобного рода информации в сети Интернет. На этой ноте я прощаюсь с тобой, дорогой читатель, до встречи в новых статьях серии «Приручение черного дракона. Этичный хакинг с Kali Linux.