Сетевая модель базы данных.
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
Иерархическая структура рис.4.2 преобразовывается в сетевую следующим образом (см. рис. 4.3):
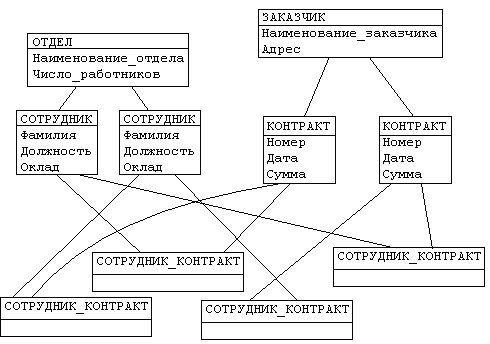
- деревья (a) и (b), показанные на рис. 4.2, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
- для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, см. рис. 4.3 (Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.)
Рисунок 4.3. Сетевая модель базы данных Каждый экземпляр группового отношения характеризуется следующими признаками: способ упорядочения подчиненных записей:
- произвольный,
- хронологический /очередь/,
- обратный хронологический /стек/,
- сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания. режим включения подчиненных записей: автоматический — невозможно занести в БД запись без того, чтобы она была сразу же закреплена за неким владельцем; ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем). режим исключения. Принято выделять три класса членства подчиненных записей в групповых отношениях:
- Фиксированное. Подчиненная запись жестко связана с записью владельцем и ее можно исключить из группового отношения только удалив. При удалении записи–владельца все подчиненные записи автоматически тоже удаляются. В рассмотренном выше примере фиксированное членство предполагает групповое отношение «ЗАКЛЮЧАЕТ» между записями «КОНТРАКТ» и «ЗАКАЗЧИК», поскольку контракт не может существовать без заказчика.
- Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи «СОТРУДНИК» и «ОТДЕЛ». Если отдел расформировывается, все его сотрудники должны быть либо переведены в другие отделы, либо уволены.
- Необязательное. Можно исключить запись из группового отношения, но сохранить ее в базе данных не прикрепляя к другому владельцу. При удалении записи-владельца ее подчиненные записи — необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить «ВЫПОЛНЯЕТ» между «СОТРУДНИКИ» и «КОНТРАКТ», поскольку в организации могут существовать работники, чья деятельность не связана с выполнением каких-либо договорных обязательств перед заказчиками.
Что можно назвать сетевой базой данных
Сетевая база данных — это тип модели базы данных, которая представляет данные в виде сетевой структуры, похожей на граф. В этой базе данные хранятся в виде узлов (или вершин) и связей (или ребер) между узлами. Такая структура позволяет моделировать более сложные отношения между объектами данных, чем в традиционной реляционной базе данных.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут.
В сетевой базе данных каждый узел может иметь несколько родительских или дочерних узлов, что позволяет создавать более гибкие связи между объектами данных. Это делает сетевые базы данных особенно полезными для моделирования сложных отношений между данными, например, в социальных сетях или цепочках поставок.
Однако они были популярны в 1970-х и 1980-х годах, сейчас используются все реже в связи с развитием реляционных баз данных, которые более эффективны для многих случаев использования и имеют более стандартизированную структуру. Тем не менее, все еще существуют некоторые специализированные приложения, в которых сетевые базы данных являются предпочтительными, например, в управлении геопространственными данными, анализе социальных сетей или в некоторых научных исследованиях.
Что относят к сетевым базам
Сетевая база данных организует данные в иерархической форме, с узлами, связанными отношениями. Данные хранятся в сети узлов и связей, причем каждый узел может иметь множество связей с другими узлами. Иерархическая структура сетевой базы данных определяется типами записей, которые определяют свойства узлов, и наборами, которые группируют узлы вместе на основе их свойств.
Она включает в себя несколько элементов:
- Узлы (Nodes) — представляют данные, которые хранятся в базе данных, и могут содержать информацию о свойствах сущностей или объектов.
- Связи (Edges) — отображают отношения между узлами и могут содержать информацию о характере связи между сущностями.
- Владельцы (Owners) — это узлы на вершине иерархии, и они могут владеть другими узлами в сети. Типы членов определяют типы узлов, которые могут принадлежать владельцам.
- Типы узлов и связей — могут использоваться для классификации узлов и связей по определенным категориям или классам.
- Ключи (Keys) — используются для связывания узлов и связей и для обеспечения ссылочной целостности.
- Запросы (Queries) — позволяют извлекать данные из базы данных на основе заданных условий и отношений между узлами и связями.
- Графическое представление (Graphical representation) — может использоваться для визуализации данных и отношений между узлами и связями.
- Индексы (Indexes) — используются для ускорения доступа к данным и оптимизации запросов.
Это не полный список компонентов, которые могут входить в сетевую базу данных, и некоторые из них могут зависеть от конкретной реализации.
Преимущества и недостатки
Преимущества сетевой базы данных:
- Гибкость: моделируют сложные отношения и порядок между объектами данных с несколькими родительскими или дочерними узлами, что делает их более гибкими, чем реляционные базы данных.
- Эффективность: извлекают данные более эффективно, чем иерархические базы данных, поскольку они могут обращаться к данным из нескольких родительских или дочерних узлов.
- Масштабируемость: обрабатывают большие объемы данных и сложные отношения между объектами данных, что делает их масштабируемыми для больших и более сложных систем.
- Производительность: работают быстрее, чем иерархические базы данных, поскольку они могут получать доступ к данным из нескольких путей в сети.
Недостатки сетевой базы данных:
- Сложность: более сложные в разработке и обслуживании, чем реляционные базы данных, особенно для больших и сложных систем.
- Отсутствие стандартизации: в отличие от реляционных баз данных, для проектирования сетевых баз данных не существует стандартизированных методов или правил. Это может затруднить поддержание согласованности в модели данных и интеграцию с другими системами.
- Ограниченное внедрение: сегодня используются реже, чем реляционные базы данных, что означает, что разработчикам доступно меньше ресурсов и инструментов.
- Стоимость: сложность и специализированный характер сетевых баз данных может сделать их более дорогими в реализации и поддержке по сравнению с реляционными базами данных.
Особенности
Вот некоторые особенности сетевых баз данных:
- Узлы: сетевая база данных хранит данные в виде узлов, которые представляют собой сущности или объекты. Узлы могут иметь атрибуты, которые описывают свойства сущности, а также могут иметь связи с другими узлами.
- Отношения: отношения между узлами представлены в виде ребер. Грани могут иметь атрибуты, которые описывают характер связи, например, силу или направление связи.
- Множественные родители/дочери: позволяют узлам иметь несколько родительских и дочерних узлов. Это облегчает представление сложных отношений между объектами данных.
- Гибкость схемы: с точки зрения разработки схемы. Узлы могут быть легко добавлены или удалены, а связи могут быть изменены или обновлены без изменения всей модели данных.
- Запрос: обычно предоставляют эффективные возможности запросов, которые позволяют пользователям перемещаться по сети и извлекать данные из нескольких узлов и отношений.
- Целостность данных: обеспечивают ограничения целостности данных, такие как уникальность или ссылочная целостность, чтобы гарантировать, что данные остаются последовательными и надежными.
- Графическое представление: предоставляют графическое представление модели данных, что облегчает визуализацию связей между узлами и понимание структуры данных.
Примеры
Вот несколько примеров сетевых баз данных:
- База данных CODASYL (Конференция по языкам систем данных) — одна из самых ранних моделей сетевых баз данных. Она была представлена в 1960-х годах и широко использовалась до появления реляционных баз данных. CODASYL хранят данные в записях, которые могут быть связаны с другими записями через наборы.
- Neo4j — это популярная графовая база данных, которая хранит данные в узлах и отношениях. Она широко используется для анализа социальных сетей, рекомендательных систем и других приложений, которые предполагают моделирование сложных отношений между объектами данных.
- ArangoDB — это многомодельная база данных, поддерживающая модели сетей, документов и ключей-значений. Она обеспечивает гибкую схему, эффективные возможности запросов и высокую доступность.
- OrientDB — это еще одна многомодельная база данных, поддерживающая сетевые, документальные и графовые модели. Она предоставляет SQL-подобный язык запросов и поддерживает распределенные транзакции и кластеризацию.
- Microsoft SQL Server Network Model — это реляционная система управления базами данных, которая включает поддержку сетевых баз данных. Она использует иерархическую структуру для организации данных и поддерживает множественные отношения «родитель-ребенок».
- Raima Database Manager — это система управления базами данных, которая поддерживает как сетевую, так и иерархическую модели. Она обеспечивает эффективный поиск данных и поддерживает распределенные транзакции.
Это лишь несколько примеров сетевых баз данных, существует множество других, каждая из которых имеет свои достоинства и недостатки.
Насколько полезной была для вас статья?