- Сетевая модель данных
- Вопрос13! Сетевая модель данных. Одна из первых сетевых моделей данных, разработанная группой codasyl (Conference of Data System Languages), была предложена в 1969 г. И развивалась до 80-х годов.
- 2.2.2 Сетевая модель данных
- 2.2.3 Объектно-ориентированная модель данных
- 2.2.4 Реляционная модель данных
Сетевая модель данных
Вопрос13! Сетевая модель данных. Одна из первых сетевых моделей данных, разработанная группой codasyl (Conference of Data System Languages), была предложена в 1969 г. И развивалась до 80-х годов.
(Оригинал смотри здесь http://coronet.iicm.tugraz.at/wbtmaster/allcoursescontent/netlib/library.htm)
Первоначально сетевая модель замышлялась как инструмент для программистов. В качестве базового языка программирования был выбран Cobol.
К известным сетевым системам управления базами данных относятся: DBMS, IDMS, TOTAL, VISTA, СЕТЬ, СЕТОР, КОМПАС и др.
Основное достоинство сетевой модели – это высокая эффективность затрат памяти и оперативность.
Недостаток – сложность и жесткость схемы базы, а также сложность понимания. Кроме того, в этой модели ослаблен контроль целостности, так как в ней допускается устанавливать произвольные связи между записями.
Сравнивая иерархические и сетевые базы данных, можно сказать следующее. В целом иерархические и сетевые модели обеспечивают достаточно быстрый доступ к данным. Но поскольку в сетевых базах основная структура представления информации имеет форму сети, в которой каждая вершина (узел) может иметь связь с любой другой, то данные в сетевой базе более равноправны, чем в иерархической, так как доступ к информации может быть осуществлен, начиная с любого узла.
Однако следует отметить жесткость организации данных в иерархических и сетевых моделях. Доступ к информации осуществляется только в соответствии со связями, определенными при проектировании структуры конкретной базы данных. Базы данных с такими моделями сложно реорганизовывать.
Недостатком этих моделей является и сложность механизма доступа к данным, а также необходимость на физическом уровне четко определять связи данных. А поскольку каждый элемент данных должен содержать ссылки на некоторые другие элементы, то для этого требуются значительные ресурсы памяти ЭВМ. Кроме того, для таких моделей характерна сложность реализации систем управления базами данных.
Сетевая модель – это структура, у которой любой элемент может быть связан с любым другим элементом (рис. 18). Реальный пример иерархической модели представлен на рис. 19.

Рис. 18. Представление связей в сетевой модели данных

Рис. 19. Пример сетевой модели данных
Сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей. Тем самым наборы записей образуют сеть. Связи между записями могут быть произвольными, и эти связи явно присутствуют и хранятся в базе данных.
Над данными в сетевой базе могут выполняться следующие операции:
- Добавить – внести запись в базу данных.
- Извлечь – извлечь запись из базы данных.
- Обновить – изменить значение элементов предварительно извлеченной записи.
- Удалить – убрать запись из базы данных.
- Включить в групповое отношение – связать существующую подчиненную запись с записью-владельцем.
- Исключить из группового отношения – разорвать связь между записью-владельцем и записью-членом.
- Переключить – связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении.
________________________________________________________________________________ Базовыми объектами сетевой модели являются:
- элемент данных;
- агрегат данных;
- запись;
- набор данных.
Элемент данных — то же, что и в иерархической модели, то есть минимальная информационная единица, доступная пользователю с использованием СУБД. Агрегат данных соответствует следующему уровню обобщения в модели. В модели определены агрегаты двух типов:
- агрегат типа вектор и
- агрегат типа повторяющаяся группа.
Агрегат данных имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типавектор соответствует линейному набору элементов данных. Например, агрегат Адрес может быть представлен следующим образом:
| Адрес | |||
| Город | Улица | дом | квартира |
Агрегат типа повторяющаясягруппа соответствует совокупности векторов данных. Например, агрегат Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
| Зарплата | |
| Месяц | Сумма |
| . | . |
Записью называется совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов реального мира. Понятие записи соответствует понятию «сегмент» в иерархической модели. Для записи, так же как и для сегмента, вводятся понятия типа записи и экземпляра записи. Следующим базовым понятием в сетевой модели является понятие «Набор». Набором называется двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.  Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора. Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение «многие-ко-многим» между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора. Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора. В качестве примера рассмотрим таблицу, на основе которой организуем два набора и определим связь между ними:
Набор фактически отражает иерархическую связь между двумя типами записей. Родительский тип записи в данном наборе называется владельцем набора, а дочерний тип записи — членом того же набора. Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Фактически наличие подобных возможностей позволяет промоделировать отношение «многие-ко-многим» между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. В рамках набора возможен последовательный просмотр экземпляров членов набора, связанных с одним экземпляром владельца набора. Между двумя типами записей может быть определено любое количество наборов: например, можно построить два взаимосвязанных набора. Существенным ограничением набора является то, что один и тот же тип записи не может быть одновременно владельцем и членом набора. В качестве примера рассмотрим таблицу, на основе которой организуем два набора и определим связь между ними:
| Преподаватель | Группа | День недели | № пары | Аудитория | Дисциплина |
| Иванов | 4306 | Понедельник | 1 | 22-13 | КИД |
| Иванов | 4307 | Понедельник | 2 | 22-13 | КИД |
| Карпова | 4307 | Вторник | 2 | 22-14 | БЗ и ЭС |
| Карпова | 4309 | Вторник | 4 | 22-14 | БЗ и ЭС |
| Карпова | 4305 | Вторник | 1 | 22-14 | БД |
| Смирнов | 4306 | Вторник | 3 | 23-07 | ГВП |
| Смирнов | 4309 | Вторник | 4 | 23-07 | ГВП |
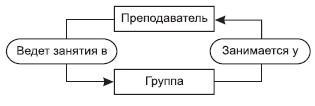 Экземпляров набора Ведет занятия будет 3 (по числу преподавателей), экземпляров набора Занимается у будет 4 (по числу групп). На рис.20представлены взаимосвязи экземпляров данных наборов.
Экземпляров набора Ведет занятия будет 3 (по числу преподавателей), экземпляров набора Занимается у будет 4 (по числу групп). На рис.20представлены взаимосвязи экземпляров данных наборов. 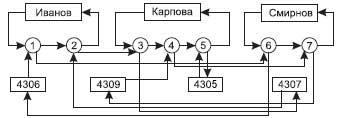 Рис. 20. Пример взаимосвязи экземпляров двух наборов Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого формально определена вся система. Сингулярный набор изображается в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора, но у которой не определен тип записи «Владелец набора». Например, сингулярный набор М.
Рис. 20. Пример взаимосвязи экземпляров двух наборов Среди всех наборов выделяют специальный тип набора, называемый «Сингулярным набором», владельцем которого формально определена вся система. Сингулярный набор изображается в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора, но у которой не определен тип записи «Владелец набора». Например, сингулярный набор М. 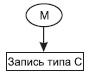 Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому если в задаче алгоритм обработки информации предполагает обеспечение произвольного доступа к некоторому типу записи, то для поддержки этой возможности необходимо ввести соответствующий сингулярный набор. В общем случае сетевая база данных представляет совокупность взаимосвязанных наборов, которые образуют на концептуальном уровне некоторый граф.
Сингулярные наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому если в задаче алгоритм обработки информации предполагает обеспечение произвольного доступа к некоторому типу записи, то для поддержки этой возможности необходимо ввести соответствующий сингулярный набор. В общем случае сетевая база данных представляет совокупность взаимосвязанных наборов, которые образуют на концептуальном уровне некоторый граф.
2.2.2 Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L
Плюсы сетевой модели данных:
Минусы сетевой модели данных:
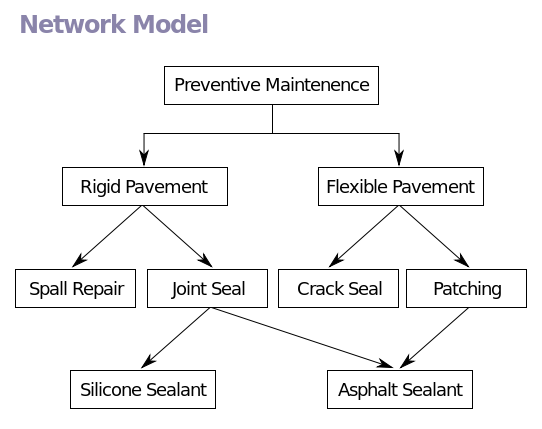
П ример сетевой модели приведен на рисунке 6:
Рисунок 6 – Сетевая модель данных
2.2.3 Объектно-ориентированная модель данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма.
Плюсы объектно-ориентированной модели:
- Возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Минусы объектно-ориентированной модели:
- Высокая понятийная сложность
- Неудобство обработки данных
- Низкая скорость выполнения запросов
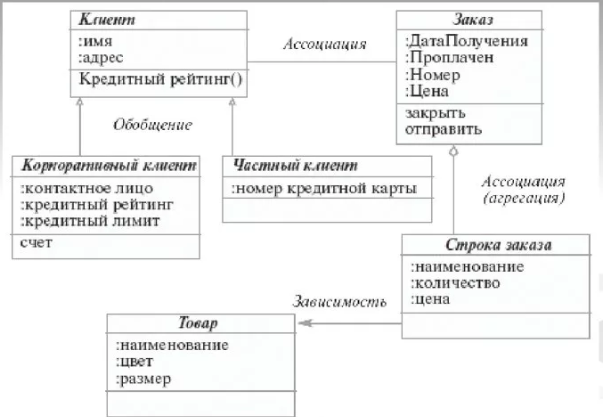
Пример объектно-ориентированной модели приведен на рисунке 7:
Рисунок 7 – Объектно-ориентированная модель данных
2.2.4 Реляционная модель данных
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation — «отношение»).
Реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Ограничения реляционной модели:
- Должны отсутствовать записи-дубликаты
- Столбцы реляционной таблицы поименованы, поэтому их порядок не важен.
- Порядок записей может быть произвольным
- Каждая запись уникальна и однозначно определяется значением ключа.
- Каждый элемент таблицы называется полем, может быть однозначно определен.
- В столбце записываются данные одного типа
Недостатки традиционных реляционных моделей:
- Избыточность по полям (из-за создания связей)
- В качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
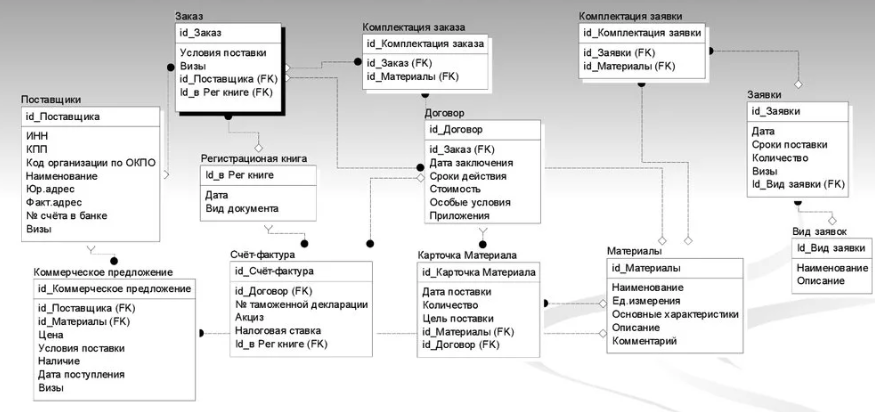
П ример реляционной модели приведен на рисунке 8:
Рисунок 8 – Реляционная модель данных