Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Сетевая модель представляет собой структуру, у которой любой элемент может быть связан с любым другим элементом.Сетевая база данных состоит из наборов записей, которые связаны между собой так, что записи могут содержать явные ссылки на другие наборы записей. Тем самым наборы записей образуют сеть. Связи между записями могут быть произвольными, и эти связи явно присутствуют и хранятся в базе данных.
Особенности сетевой модели данных.
- Связи в сетевой модели данных осуществляются наборами, которые реализуются с помощью указателей. Сетевая модель данных являются особым витком в развитии иерархической модели данных, их основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию.
- Сетевая модель данных предполагает наличие в ней произвольного количества записей и наборов в том числе их различных типов.
- Связь между двумя записями может выражаться произвольным количеством наборов.
- В любом наборе может быть только один владелец.
- Тип записи может быть владельцем в одних типах наборов и членом в других типах наборов, а также не входить ни в какой тип наборов.
- Допускается добавление новой записи в качестве экземпляра владельца, если экземпляр-член отсутствует.
- При удалении записи-владельца удаляются соответствующие указатели на экземпляры-члены, но сами записи-члены не уничтожаются (сингулярный набор).
Управление сетевыми данными.
Операции с сетевыми данными можно разделить на две группы: навигационные операции с данными и операции модификации данных.
Навигационные операции с данными
Навигационные операции сетевых баз данных осуществляют переход по связям, определенных в схеме баз данных, в результате таких переходов определяется запись, которую называют текущей.
- Найти конкретную запись в наборе однотипных записей и сделать ее текущей;
- Перейти от записи-владельца к записи-члену в некотором наборе;
- Перейти к следующей записи в некоторой связи;
- Перейти от записи-члена к владельцу по некоторой связи.
Операции модификации данных
Операций модификации сетевых баз данных осуществляют добавление новых записей данных, добавление новых наборов данных, удаление записей данных и наборов записей, модификация агрегатов и элементов данных.
- извлечь текущую запись в буфер прикладной программы для обработки;
- заменить в извлеченной записи значения указанных элементов данных на заданные новые их значения;
- запомнить запись из буфера в БД;
- создать новую запись;
- уничтожить запись;
- включить текущую запись в текущий экземпляр набора;
- исключить текущую запись из текущего экземпляра набора.
Реляционная модель данных
Реляционная модель — совокупность данных, состоящая из набора двумерных таблиц. В теории множеств таблице соответствует термин отношение (relation), физическим представлением которого является таблица, отсюда и название модели – реляционная. Соответственно теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка. В сравнении с иерархической и сетевой моделью данных, реляционная модель отличается более высоким уровнем абстракции данных. Реляционная модель является удобной и наиболее привычной формой представления данных, так в настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. На реляционной модели данных строятся реляционные базы данных.
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствована соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формируя дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
- Изложение информации в простой и понятной для пользователя форме (таблица).
- Реляционная модель данных основана на строгом математическом аппарате, что позволяет лаконично описывать необходимые операции над данными.
- Независимость данных от изменения в прикладной программе при изменении.
- Позволяет создавать языки манипулирования данными не процедурного типа.
- Для работы с моделью данных нет необходимости полностью знать организацию БД.
- Относительно медленный доступ к данным.
- Трудность в создании БД основанной на реляционной модели.
- Трудность в переводе в таблицу сложных отношений.
- Требуется относительно большой объем памяти.
8.2 Сетевая модель базы данных
2. Сетевая модель данных является более общей структурой по сравнению с иерархической. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Каждый отдельный сегмент (ячейка) может иметь произвольное число непосредственных исходных (старших) сегментов, а также и произвольное число порожденных (младших) ( рис. 8). Это обеспечиваетпредставление отношения «многие к многим».
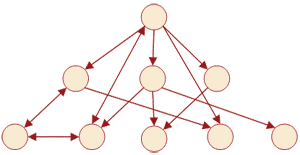
Рис. 8. Сетевая модель данных
Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе. Поскольку логика процедуры выборки данных зависит от их физической организации, то сетевая модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно поменять и приложение.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
8.3. Достоинства и недостатки ранних субд
Достоинства ранних СУБД:
- развитые средства управления данными во внешней памяти на низком уровне;
- возможность построения вручную эффективных прикладных систем;
- возможность экономии памяти за счет разделения подобъектов (в сетевых системах)
- сложность использования;
- высокий уровень требований к знаниям о физической организации БД;
- зависимость прикладных систем от физической организации БД;
- перегруженность логики прикладных систем деталями организации доступа к БД.
8.4. Реляционная модель данных

Понятие реляционный (англ. relation — отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эта модель характеризуется простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель — единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково — таблицами. Таблица является наиболее удобным инженерным представлением для пользователя ( рис. 9,а). Каждый столбец ее соответствует атрибуту объекта, и ему присваивается соответствующее имя. В столбцах таблицы (отношения) вводятся значения атрибутов. Используя отношения связи и язык реляционной алгебры, можно осуществлять выбор любого подмножества информации: по строкам, столбцам или другим признакам. Применяя операции «разрезания» и «склеивания» отношений, можно получить разнообразные файлы в нужной форме ( рис. 9,б). При использовании реляционной модели атрибут объекта может сам выступать как объект другой предметной области, т.е. задействуется относительность (отсюда – отношение) понятий объекта и его атрибутов. Рис. 9 Пример (а) и общий вид (б) реляционной модели данных