3.2.2 Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
В сетевой структуре при тех же понятиях уровень, узел, связь, каждый элемент может быть связан с любым другим элементом.
Сетевая модель СУБД во многом подобна иерархической: если в иерархической модели для каждого сегмента записи допускается только один входной сегмент при N выходных, то в сетевой модели для сегментов допускается несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры.
Графическое изображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД.
Таким образом, под сетевой БД понимается система, поддерживающая сетевую организацию: любая запись, называемая записью старшего уровня, может содержать данные, которые относятся к набору других записей, называемых записями подчиненного уровня. Возможно обращение ко всем записям в наборе, начиная с записи старшего уровня. Обращение к набору записей реализуется по указателям.
Сетевые БД поддерживают сложные соотношения между типами данных, что делает их пригодными во многих различных приложениях. Однако пользователи таких БД ограничены связями, определенными для них разработчиками БД-приложений. Среди недостатков сетевых СУБД следует особо выделить проблему обеспечения сохранности информации в БД, решению которой уделяется повышенное внимание при проектировании сетевых БД.
Достоинства сетевой модели данных:
1)эффективное использование памяти;
Недостатки сетевой модели данных:
1) сложность доступа к элементам (навигационный принцип доступа);
2) сложно отследить смысл такой модели данных.
Сетевая модель данных изображена на рисунке 3.4.
Рисунок 3.4 – Сетевая модель данных
3.2.3 Реляционная модель данных
Реляционная модель данных — логическая модель данных, прикладная теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в реляционных базах данных. Понятие реляционный связано с разработками известного американского специалиста в области систем баз данных, сотрудника фирмы IBM Е. Кодда, которым впервые был применен термин «реляционная модель данных».
Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). В качестве неформального синонима термину «отношение» часто встречается слово таблица
В течение долгого времени реляционный подход рассматривался как удобный формальный аппарат анализа баз данных, не имеющий практических перспектив, так как его реализация требовала слишком больших машинных ресурсов. Только с появлением персональных ЭВМ реляционные и близкие к ним системы стали распространяться, практически не оставив места другим моделям.
Эти модели характеризуются простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами:
- каждый элемент таблицы — один элемент данных; повторяющиеся группы отсутствуют;
- все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип (числовой, символьный и т.д.) и длину;
- каждый столбец имеет уникальное имя;
- одинаковые строки в таблице отсутствуют;
- порядок следования строк и столбцов может быть произвольным.
Таблица такого рода называется отношением.
База данных, построенная с помощью отношений, называется реляционной базой данных.
Отношения представлены в виде таблиц, строки которых соответствуют записям, а столбцы – полям.
Поле, каждое значение которого однозначно определяет соответствующую запись, называется ключевым. Если записи однозначно определяются значениями нескольких полей, то такая таблица базы данных имеет составной ключ.
Достоинства реляционной модели:
1) простота и доступность понимания конечным пользователем — единственной информационной конструкцией является таблица;
2) при проектировании реляционной БД применяются строгие правила, базирующие на математическом аппарате;
3) полная независимость данных. При изменении структуры реляционной изменения, которые требуют произвести в прикладных программах, минимальны.
Недостатки реляционной модели:
1) относительно низкая скорость доступа и большой объем внешней памяти;
2) трудность понимания структуры данных из-за появления большого кол-ва таблиц в результате логического проектирования;
3) далеко не всегда предметную область можно представить в виде совокупности таблиц.
В последнее время всё большее количество БД основываются на РМ в виду её простоты и удобства, а также большого количества программных продуктов для разработки этой СУБД. И даже недостатки реляционной модели компенсируются ростом быстродействия и ресурсов памяти современных ЭВМ.
Для курсового проекта была выбрана реляционная модель данных. Для данной предметной области она является оптимальной, поскольку обладает такими свойствами, как удобство реализации, простота. Сетевая модель не подходит из-за сложного доступа к элементам и является довольно громоздкой, что затрудняет отслеживание смысла связей между объектами. В реляционной модели связи легко определимы. В иерархической модели данных отсутствует механизм, поддерживающий связи между элементами различных поддеревьев, что также может затруднить работу.
Реляционная модель данных представлена на рисунке 3.5. Таблица Аптека содержит название аптеки, № аптеки, адрес, телефон, лицензию. Таблица Изготовитель содержит название изготовителя, телефон, адрес. В таблице Тип хранится информация о названии типа медикамента. Таблица Препараты хранит названия препаратов дату изготовления, рецепт. Таблица Медикамент хранит информацию о названии медикамента и цену. Таблица Владелец хранит Ф.И.О. владельца, дату рождения, страховку. Таблица Поступает хранит информацию о дате поступления медикамента и количестве.
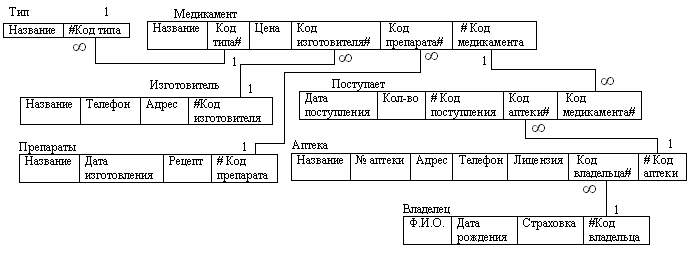
Рисунок 3.5 – Реляционная модель данных
Проанализировав типы моделей данных, я пришла к выводам, что удобнее реализовывать базу данных на основе реляционной модели.
Реляционная модель данных проста и удобна для понимания, в отличии от сетевой, где очень легко запутаться в связях между объектами и не так громоздка, как иерархическая модель.
Данные в реляционной модели не зависимы и при изменении структуры не требуется переделывать всю базу, как в иерархической и сетевой моделях. Также реляционная модель рассчитана на разнообразные типы запросов, в отличии от иерархической, ориентированной на конкретные запросы.
В настоящее время для разработки реляционной СУБД существует множество программных продуктов и систем поддержки. Все это делает разработку именно такой модели данных наиболее удобной.
Модели данных
Процесс проектирования БД начинается с создания инфологической модели.
Инфологическая модель данных — обобщенное неформальное описание создаваемой базы данных, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных..
Инфологическая модель данных — обобщенное, непривязанное к каким-либо СУБД описание предметной области.
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель «сущность-связь» и др.
Семантические сети
Семантическая сеть (СС) – это граф, дуги которого есть отношения между вершинами (значениями). Семантические сети появились при решении задач разбора и понимания смысла естественного языка. Пример семантической сети для предложения типа «Поставщик осуществил поставку изделий по заказу клиента до 1 июня 2004 года в количестве 1000 штук» приведен на рис. 1.
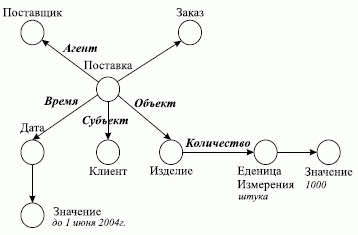
Рис. 1. Пример семантической сети
На этом примере видно, что между объектами Поставщик и Поставка определено отношение «агент», между объектами Изделие и Поставка определено отношение «объект» и т.д.
Число отношений, используемых в конкретных семантических сетях, может быть самое разное. Неполный список возможных отношений, используемых в семантических сетях для разбора предложений, выглядит следующим образом.
Агент — это то, что (тот, кто) вызывает действие. Агент часто является подлежащим в предложении, например, «Робби ударил мяч».
Объект — это то, на что (на кого) направлено действие. В предложении объект часто выполняет роль прямого дополнения, например, «Робби взял желтую пирамиду «.
Инструмент — то средство, которое используется агентом для выполнения действия, например, «Робби открыл дверь с помощью ключа».
Соагент служит как подчиненный партнер главному агенту, например, «Робби собрал кубики с помощью Суззи».
Пункт отправления и пункт назначения — это отправная и конечная позиции при перемещении агента или объекта: «Робби перешел из комнаты в библиотеку».
Траектория — перемещение от пункта отправления к пункту назначения: «Они прошли через дверь по ступенькам на лестницу».
Средство доставки — то в чем или на чем происходит перемещение: «Он всегда едет домой на метро».
Местоположение — то место, где произошло (происходит, будет происходить) действие, например, «Он работал за столом».
Потребитель — то лицо, для которого выполняется действие: «Робби собрал кубики для Суззи».
Сырье — это, как правило, материал, из которого что-то сделано или состоит. Обычно сырье вводится предлогом из, например, «Робби собрал Суззи из интегральных схем».
Время — указывает на момент совершения действия: «Он закончил свою работу поздно вечером».
Наиболее типичный способ вывода в семантических сетях (СС) — это способ сопоставления частей сетевой структуры. Это видно на следующем простом примере, представленном на рис. 2.
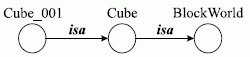
Рис. 2. Процедура сопоставления в СС
Куб Cube принадлежит миру BlockWorld.
Куб Cube_001 есть разновидность куба Cube.
Куб Cube_001 есть часть мира BlockWorld.
Еще один пример поиска в СС. Представим вопрос «какой объект находится на желтом блоке?» в виде подсети, изображенной на рис. 3. Произведем сопоставление вопроса с сетью, представленной на рис. 4. В результате сопоставления получается ответ — «Пирамида».
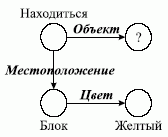
Рис. 3. Вопрос в виде CC
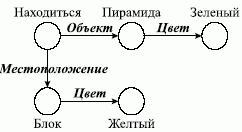
Рис. 4. Процедура сопоставления в СС