2.2.2 Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L
Плюсы сетевой модели данных:
Минусы сетевой модели данных:
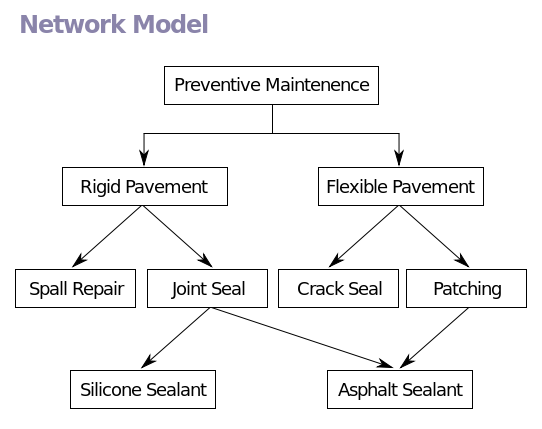
П ример сетевой модели приведен на рисунке 6:
Рисунок 6 – Сетевая модель данных
2.2.3 Объектно-ориентированная модель данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма.
Плюсы объектно-ориентированной модели:
- Возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Минусы объектно-ориентированной модели:
- Высокая понятийная сложность
- Неудобство обработки данных
- Низкая скорость выполнения запросов
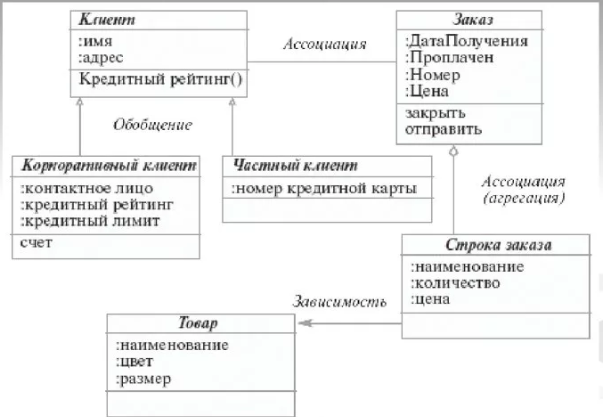
Пример объектно-ориентированной модели приведен на рисунке 7:
Рисунок 7 – Объектно-ориентированная модель данных
2.2.4 Реляционная модель данных
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation — «отношение»).
Реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Ограничения реляционной модели:
- Должны отсутствовать записи-дубликаты
- Столбцы реляционной таблицы поименованы, поэтому их порядок не важен.
- Порядок записей может быть произвольным
- Каждая запись уникальна и однозначно определяется значением ключа.
- Каждый элемент таблицы называется полем, может быть однозначно определен.
- В столбце записываются данные одного типа
Недостатки традиционных реляционных моделей:
- Избыточность по полям (из-за создания связей)
- В качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
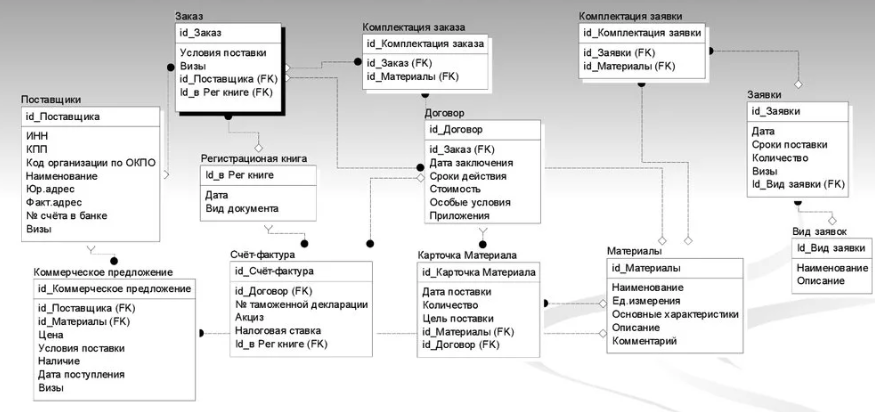
П ример реляционной модели приведен на рисунке 8:
Рисунок 8 – Реляционная модель данных
2.2. Сетевая модель данных
СМД позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым ИМД (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).

Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка,то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей).
Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД
В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т. д. (см. п. 1.1.3).
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
переход от предка к первому потомку;
переход от потомка к предку;
обновление текущей записи;
исключение записи из связи;
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность ижесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контрольцелостности связей вследствие допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
2.3. Реляционная модель данных
Реляционная модель данных предложена сотрудником фирмы IBMЭдгаром Коддом и основывается на понятии «отношение» (relation).
Отношение представляет собой множество наборов элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка (запись) таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения (имена полей).
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество под объектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуруили свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицыне удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются:отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IV (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) иOracle(Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН Украины), а также система HyTech (МИФИ, РФ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются «чисто» реляционными.