1.3.5. Пример построения и расчета сетевой модели
Исходные данные варианта лабораторной работы включают название и продолжительность каждой работы (табл. 1.1), а также описание упорядочения работ.
- Работы C, I, Gявляются исходными работами проекта, которые могут выполняться одновременно.
- Работы E иAследуют за работойC.
- Работа Hследует за работойI.
- Работы D иJследуют за работойG.
- Работа Bследует за работойE.
- Работа Kследует за работамиAиD, но не может начаться прежде, чем не завершится работаH.
- Работа Fследует за работойJ.
На рис.1.4 представлена сетевая модель, соответствующая данному упорядочению работ. Каждому событию присвоен номер, что позволяет в дальнейшем использовать не названия работ, а их коды (см. табл. 1.2). Численные значения временных параметров событий сети вписаны в соответствующие секторы вершин сетевого графика, а временные параметры работ сети представлены в табл. 1.3. Таблица 1.2 Описание сетевой модели с помощью кодирования работ
| Номера событий | Код работы | Продолжительность | |
| начального | конечного | работы | |
| 1 | 2 | (1,2) | 4 |
| 1 | 3 | (1,3) | 3 |
| 1 | 4 | (1,4) | 5 |
| 2 | 5 | (2,5) | 7 |
| 2 | 6 | (2,6) | 10 |
| 3 | 6 | (3,6) | 8 |
| 4 | 6 | (4,6) | 12 |
| 4 | 7 | (4,7) | 9 |
| 5 | 8 | (5,8) | 8 |
| 6 | 8 | (6,8) | 10 |
| 7 | 8 | (7,8) | 11 |
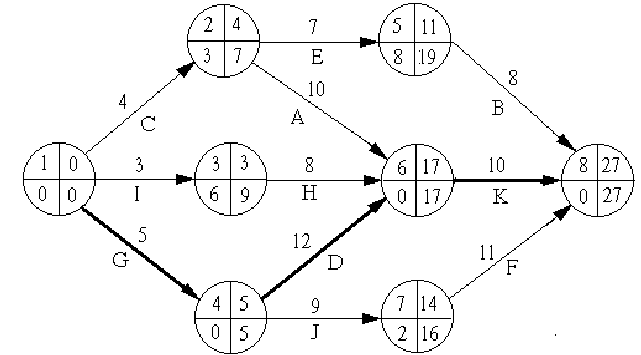 Рис.1.4. Сетевая модель Таблица 1.3 Временные параметры работ
Рис.1.4. Сетевая модель Таблица 1.3 Временные параметры работ
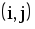 | 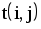 | 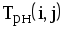 | 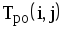 | 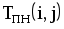 | 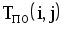 | 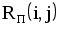 | 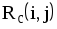 |
| 1,2 | 4 | 0 | 4 | 3 | 7 | 3 | 0 |
| 1,3 | 3 | 0 | 3 | 6 | 9 | 6 | 0 |
| 1,4 | 5 | 0 | 5 | 0 | 5 | 0 | 0 |
| 2,5 | 7 | 4 | 11 | 12 | 19 | 8 | 0 |
| 2,6 | 10 | 4 | 14 | 7 | 17 | 3 | 3 |
| 3,6 | 8 | 3 | 11 | 9 | 17 | 6 | 6 |
| 4,6 | 12 | 5 | 17 | 5 | 17 | 0 | 0 |
| 4,7 | 9 | 5 | 14 | 7 | 16 | 2 | 0 |
| 5,8 | 8 | 11 | 19 | 19 | 27 | 8 | 8 |
| 6,8 | 10 | 17 | 27 | 17 | 27 | 0 | 0 |
| 7,8 | 11 | 14 | 25 | 16 | 27 | 2 | 2 |
1.4. Контрольные вопросы
1.4.1. Зачетный минимум
- Определение события, виды событий, практические примеры событий, обозначение событий на графике, временные параметры событий.
- Определение работы, классификация работ с приведением соответствующих практических примеров, обозначение работ на графике, временные параметры работ.
- Правила построения сетевых графиков.
- Определение пути в сетевом графике, виды путей, важность определения критического пути.
- Умение вычислять временные параметры событий и работ.
1.4.2. Дополнительные вопросы
- Почему при расчете раннего срока свершения события iвыбираютмаксимальнуюиз сумм
 ?
? - Почему при расчете позднего срока свершения события iвыбираютминимальнуюиз разностей ?
- Какова взаимосвязь полного и свободного резервов работы?
- Как можно найти критических путь в сетевой модели, без непосредственного суммирования длительностей работ?
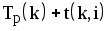 ?
?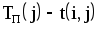 ?
? Часть 2. ОПТИМИЗАЦИЯ СЕТЕВЫХ МОДЕЛЕЙ ПО КРИТЕРИЮ «МИНИМУМ ИСПОЛНИТЕЛЕЙ» 2.1. ЦЕЛЬ РАБОТЫ Знакомство с методикой и приобретение навыков проведения оптимизации сетевых моделей по критерию «Минимум исполнителей». 2.2. ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ 1. Согласно номеру своего варианта получите данные о количество исполнителей, занятых на каждой работе сетевой модели, и ограничение по численности Nодновременно занятых в работе исполнителей. 2. Постройте в отчете графики привязки и загрузки, используя нормальные длительности работ сети —  (см. п.2.3.1), и покажите их преподавателю. 3. Проверьте правильность построения графиков привязки и загрузки с помощью компьютера, в случае необходимости выявите и устраните ошибки. 4. Используя компьютерную программу, проведите уменьшение численности исполнителей, одновременно занятых на работах сети, до требуемого уровня N. 5. Отчет по лабораторной работе должен содержать:
(см. п.2.3.1), и покажите их преподавателю. 3. Проверьте правильность построения графиков привязки и загрузки с помощью компьютера, в случае необходимости выявите и устраните ошибки. 4. Используя компьютерную программу, проведите уменьшение численности исполнителей, одновременно занятых на работах сети, до требуемого уровня N. 5. Отчет по лабораторной работе должен содержать:
- номер варианта;
- исходные данные варианта;
- графики привязки и загрузки до проведения оптимизации загрузки;
- графики привязки и загрузки после проведения оптимизации загрузки (возможно использование пунктирных линий на первоначально построенных графиках для отображение изменений в привязке работ и загрузке сети, вызванных сдвигами работ);
- коды работ, сдвинутых в процессе оптимизации, и время их сдвига.
2.2. Сетевая модель данных
СМД позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым ИМД (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).

Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка,то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей).
Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД
В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т. д. (см. п. 1.1.3).
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
переход от предка к первому потомку;
переход от потомка к предку;
обновление текущей записи;
исключение записи из связи;
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность ижесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контрольцелостности связей вследствие допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
2.3. Реляционная модель данных
Реляционная модель данных предложена сотрудником фирмы IBMЭдгаром Коддом и основывается на понятии «отношение» (relation).
Отношение представляет собой множество наборов элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка (запись) таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения (имена полей).
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество под объектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуруили свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицыне удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются:отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IV (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) иOracle(Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН Украины), а также система HyTech (МИФИ, РФ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются «чисто» реляционными.
Сетевая модель данных и ее характеристики. Понятие набора
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).
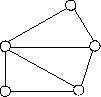
Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД

Рис. 2.5. Пример схемы сетевой БДВ различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие, как элементы и агрегаты данных, записи, наборы, области и т. д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных. К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие: поиск записи в БД; переход от предка к первому потомку; переход от потомка к предку; создание новой записи; удаление текущей записи; обновление текущей записи; включение записи в связь; исключение записи из связи; изменение связей и т. д. Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Набор –это структура данных, которая отображает связи меду объектами в предметной области. Каждый набор содержит единственную запись, называемую владельцем набора, и множество записей, называемых членами набора. Наборы, имеющие одинаковый тип владельца и одинаковый тип члена, а также обладающие одинаковой семантикой (смыслом), объединяются в тип набора, который имеет уникальное имя.