2.2. Сетевая модель данных
СМД позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым ИМД (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).

Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка,то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей).
Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД
В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т. д. (см. п. 1.1.3).
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
переход от предка к первому потомку;
переход от потомка к предку;
обновление текущей записи;
исключение записи из связи;
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность ижесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контрольцелостности связей вследствие допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
2.3. Реляционная модель данных
Реляционная модель данных предложена сотрудником фирмы IBMЭдгаром Коддом и основывается на понятии «отношение» (relation).
Отношение представляет собой множество наборов элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка (запись) таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения (имена полей).
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество под объектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуруили свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицыне удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются:отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IV (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) иOracle(Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН Украины), а также система HyTech (МИФИ, РФ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются «чисто» реляционными.
8.2 Сетевая модель базы данных
2. Сетевая модель данных является более общей структурой по сравнению с иерархической. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
В сетевых БД наряду с вертикальными реализованы и горизонтальные связи. Каждый отдельный сегмент (ячейка) может иметь произвольное число непосредственных исходных (старших) сегментов, а также и произвольное число порожденных (младших) ( рис. 8). Это обеспечиваетпредставление отношения «многие к многим».
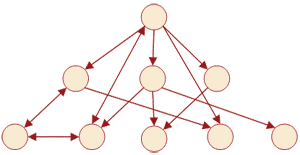
Рис. 8. Сетевая модель данных
Однако унаследованы многие недостатки иерархической и главный из них, необходимость четко определять на физическом уровне связи данных и столь же четко следовать этой структуре связей при запросах к базе. Поскольку логика процедуры выборки данных зависит от их физической организации, то сетевая модель не является полностью независимой от приложения. Другими словами, если необходимо изменить структуру данных, то нужно поменять и приложение.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
8.3. Достоинства и недостатки ранних субд
Достоинства ранних СУБД:
- развитые средства управления данными во внешней памяти на низком уровне;
- возможность построения вручную эффективных прикладных систем;
- возможность экономии памяти за счет разделения подобъектов (в сетевых системах)
- сложность использования;
- высокий уровень требований к знаниям о физической организации БД;
- зависимость прикладных систем от физической организации БД;
- перегруженность логики прикладных систем деталями организации доступа к БД.
8.4. Реляционная модель данных

Понятие реляционный (англ. relation — отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда. Эта модель характеризуется простотой структуры данных, удобным для пользователя табличным представлением и возможностью использования формального аппарата алгебры отношений и реляционного исчисления для обработки данных. Все данные в модели представляются в виде таблиц и только таблиц. Реляционная модель — единственная из всех обеспечивает единообразие представления данных. И сущности, и связи этих самых сущностей представляются в модели совершенно одинаково — таблицами. Таблица является наиболее удобным инженерным представлением для пользователя ( рис. 9,а). Каждый столбец ее соответствует атрибуту объекта, и ему присваивается соответствующее имя. В столбцах таблицы (отношения) вводятся значения атрибутов. Используя отношения связи и язык реляционной алгебры, можно осуществлять выбор любого подмножества информации: по строкам, столбцам или другим признакам. Применяя операции «разрезания» и «склеивания» отношений, можно получить разнообразные файлы в нужной форме ( рис. 9,б). При использовании реляционной модели атрибут объекта может сам выступать как объект другой предметной области, т.е. задействуется относительность (отсюда – отношение) понятий объекта и его атрибутов. Рис. 9 Пример (а) и общий вид (б) реляционной модели данных