Сетевая подсистема ядра linux
Библиотека сайта rus-linux.net
Сеть
Сетевая подсистема является гораздо разветвлённее итерфейса устройств Linux. Но, несмотря на обилие возможностей (например, если судить по числу обслуживающих сетевых утилит: ifconfig, ip, netstat, route . и до нескольких десятков иных) — сетевая подсистема Linux, с позиции разработчика ядра, логичнее и прозрачнее, чем, например, тот же интерфейс устройств. Сетевая подсистема Linux ориентирована в большей степени на обслуживание протоколов Ethernet на канальном уровне и TCP/IP на уровне транспортном, но эта модель расширяется с равным успехом и на другие типы протоколов, таким образом покрывая весь спектр возможностей. Сеть TCP/IP, как известно, весьма условно вписывается в 7-уровневую модель OSI взаимодействия открытых систем (она и разработана раньше модели OSI, и, естественно, они не соответствуют друг другу). В Linux сложилась такая терминология разделения на подуровни, что:
- всё, что относится к поддержке оборудования и канальному уровню — описывается как сетевые интерфейсы;
- протоколы сетевого уровня OSI ( IP/IPv4/IPv6, IPX, ICMP, RIP, OSPF, ARP , . ) — как сетевой уровень стека протоколов (или L2);
- всё, что выше (UDP, TCP, SCTP . ) — как протоколы транспортного уровня (или L3);
- всё же то, что относится к выше лежащим уровням (сеансовый, представительский, прикладной) модели OSI (например: SSH, SIP, RTP, . ) — никаким образом не проявляется в ядре, и относится уже только к области клиентских и серверных утилит пространства пользователя.
Сетевая реализация построена так, чтобы не зависеть от конкретики протоколов. Основной структурой данных описывающей сетевой интерфейс (устройство) является struct net_device , к ней мы вернёмся позже, описывая устройство.
здесь Рис. 4: сетевые уровни и уровни стека протоколов.
А вот основной структурой обмениваемых данных (между сетевыми уровнями), на движении которой построена работа всех сетевых уровней — есть буферы сокетов (определения в ). Буфер сокетов состоит их двух частей: данные управления struct sk_buff , и данные пакета (указываемые в struct sk_buff указателями head и data ). Буферы сокетов всегда увязываются в очереди (struct sk_queue_head) посредством своих двух первых полей next и prev . Вот некоторые поля структуры, которые позволяют представить её структуру:
typedef unsigned char *sk_buff_data_t; struct sk_buff < struct sk_buff *next; /* These two members must be first. */ struct sk_buff *prev; . sk_buff_data_t transport_header; sk_buff_data_t network_header; sk_buff_data_t mac_header; . unsigned char *head, *data; . >;
Структура вложенности заголовков в точности соответствует структуре инкапсуляции сетевых протоколов протоколов внутри друг друга, это позволяет обрабатывающему слою доступаться до информации, относящейся только к данному слою.
| Предыдущий раздел: | Оглавление | Следующий раздел: |
| Интерфейс /sys | Драйверы: сетевой интерфейс |
NAPI в сетевых драйверах Linux
Поговорим о драйверах сетевых устройств Linux, механизме NAPI и его изменениях в ядре 5.12.
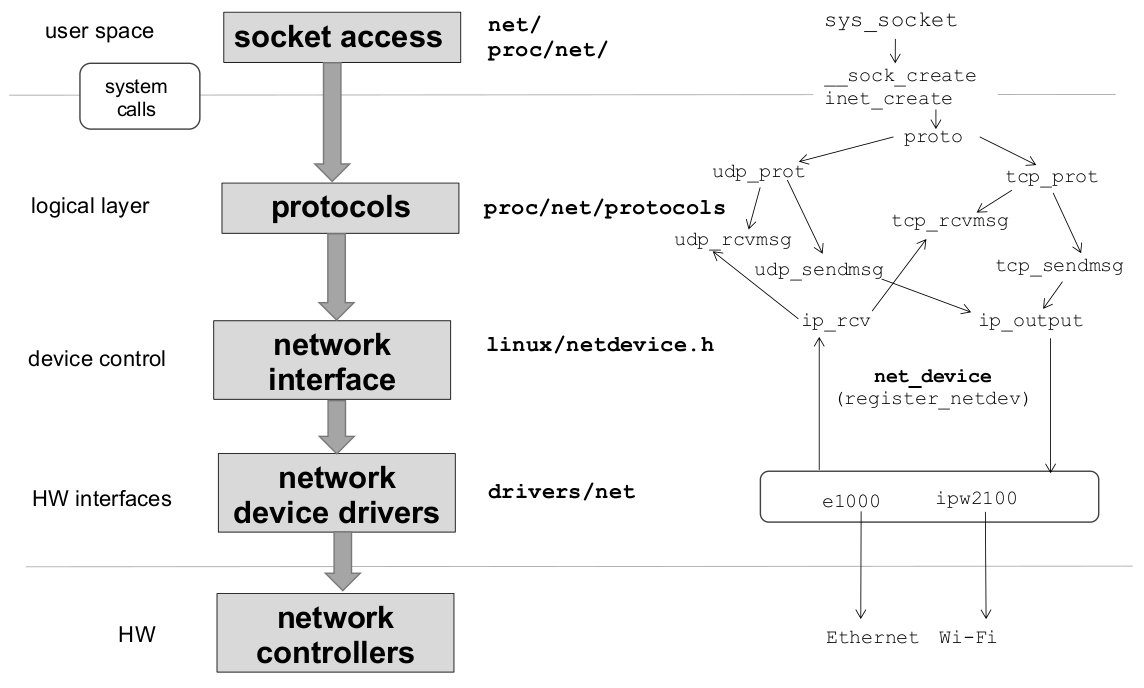
Сетевая подсистема Linux (рисунок) построена по примеру стека BSD, в ней прием и передача данных на транспортном и сетевом уровнях происходит с помощью интерфейса сокетов. В отличие от unix-сокетов для межпроцессного взаимодействия, TCP/IP сокеты используют для работы сетевой протокол и при создании (sys_socket) принимают параметры домен, тип, локальные и удаленные IP-адрес и порт. Буфер сокета (sk_buff) — фактически, пакет. Связный список экземпляров таких структур составляет очередь сетевого интерфейса (tx_queue, rx_queue).
Упрощенно – некоторые важные поля sk_buff:
struct sk_buff < union < struct < /* Двусвязный список */ struct sk_buff *next; struct sk_buff *prev; struct net_device *dev; >; struct list_head list; >; struct sock *sk; unsigned int len, data_len; __u16 mac_len, hdr_len; /* Часть NAPI-интерфейса */ #if defined(CONFIG_NET_RX_BUSY_POLL) || defined(CONFIG_XPS) union < unsigned int napi_id; unsigned int sender_cpu; >; #endif __u8 inner_ipproto; __u16 inner_transport_header; __u16 inner_network_header; __u16 inner_mac_header; __be16 protocol; __u16 transport_header; __u16 network_header; __u16 mac_header; sk_buff_data_t tail; sk_buff_data_t end; unsigned char *head, *data; unsigned int truesize; >;Драйвера отвечают за реализацию канального уровня (разрешение MAC-адресов) и предоставление интерфейса между системными вызовами ядра и сетевой картой. Обработка входящих и исходящих пакетов происходят с помощью функций xmit и rx, от одновременного доступа они защищены спин блокировками, как и обновление статистики stats и изменение параметров передачи. Сам интерфейс определяется структурой net_device, для создания и регистрации вызываются функции alloc_netdev и register_netdev.
Сетевой драйвер похож на блочный: передает и получает данные по запросу, но блочные драйверы отвечают только на запросы ядра, а сетевые получают пакеты асинхронно извне. Долгое время в Linux, когда сетевое устройство “просило” поместить входящие пакеты в ядро, действовал механизм обработки аппаратных прерываний.
Схематичные действия в обработчике прерываний для очистки очереди входящих пакетов: (драйвер intel Ethernet e1000):
static bool e1000_clean_rx_irq(struct e1000_adapter *adapter, // Сетевое устройство struct e1000_rx_ring *rx_ring, // Очередь входящих пакетов int *work_done, int work_to_do) < while (rx_desc->status & E1000_RXD_STAT_DD) < struct sk_buff *skb; u8 *data; u8 status; if (netdev->features & NETIF_F_RXALL) < total_rx_bytes += (length - 4); total_rx_packets++; e1000_receive_skb(adapter, status, rx_desc->special, skb); > > if (cleaned_count) // Создание нового буфера adapter->alloc_rx_buf(adapter, rx_ring, cleaned_count); // Обновление статистики adapter->total_rx_packets += total_rx_packets; adapter->total_rx_bytes += total_rx_bytes; netdev->stats.rx_bytes += total_rx_bytes; netdev->stats.rx_packets += total_rx_packets; return cleaned; >До ядер версии 2.3 после самого обработчика прерывания (top half) для выполнения основных задач использовались нижние половины (bottom half) и очереди задач (task queue). Начиная с версии 2.3 на замену интерфейсу BH пришли отложенные прерывания (softirq), тасклеты (tasklet) и очереди отложенных действий (work queue). Преимущество softirq в том, что они могут одновременно выполняться на разных процессорах. Они напрямую используются в сетевой подсистеме.
Немного о NAPI
Пока сетевой трафик был умеренным, механизм прерываний при получении пакета эффективно справлялся со своей задачей. С ростом трафика и появлением высоконагруженных систем постоянная обработка прерываний стала приводить к нехватке процессорного времени для пользовательских программ и потере пакетов. Решение проблемы было предложено в 2001 году и появилось в виде интерфейса New API в ядрах серии 2.4. (В оригинальной статье – результаты тестирования для SMP-системы, генератор трафика наподобие pktgen).
Основная цель NAPI — сократить количество прерываний, генерируемых при получении пакетов. В NAPI механизм прерываний сочетается с механизмом опроса. Чаще всего в разработке избегают использования поллинга, так как могут тратиться лишние ресурсы, когда оборудование молчит. У выоконагруженных интерфейсов такой проблемы не возникает.
В NAPI-совместимых драйверах прерывания отключаются, когда на интерфейс приходит пакет. Обработчик в этом случае только вызывает rx_schedule, гарантирующий, что обработка пакетов произойдет в дальнейшем. Когда приходящие пакеты заполняют буфер (предельное количество – budget), для обработки вызывается метод dev->poll. Метод poll будет вызываться одновременно не более, чем на одном процессоре, что упрощает синхронизацию. Если нагрузка падает, снова разрешаются прерывания. Это позволяет динамически регулировать производительность в зависимости от нагрузки интерфейса. Метод poll может использоваться также и для передачи пакетов.
Пример poll из драйвера e1000:
static void e1000_netpoll(struct net_device *netdev) < struct e1000_adapter *adapter = netdev_priv(netdev); if (disable_hardirq(adapter->pdev->irq)) e1000_intr(adapter->pdev->irq, netdev); enable_irq(adapter->pdev->irq); >При реализации NAPI-совместимого драйвера должны быть выполнены некоторые требования:
- Возможность хранения входящих пакетов в кольце DMA или буфере в самой карте
- Возможность отключить прерывания
- В методе poll должна быть реализована возможность забрать несколько пакетов за раз
- Так как метод poll работает в контексте softirq и управляется демоном ksoftirqd, в системах с высокой загрузкой нужно менять приоритет поллинга для обеспечения баланса ресурсов между обработчиком прерываний и пользовательскими программами.
- В некоторых случаях в системе могуть быть задержки, если весь обработчик прерываний помещен в dev->poll
- Маскировка прерываний может быть медленной
- Возможно состояние IRQ-гонки, если пакет приходит во время проверки бита наличия новых пакетов и включения прерываний.
Что нового у NAPI в 5.12?
В серии патчей в ядре 5.12 метод poll из softirq контекста перенесен в поток ядра.
Wei Wang в комментарии к патчу рассказывает, что причина такого решения – отсутствие возможности отследить программные прерывания в системе. Планировщик не может измерить время, затрачиваемое на обработку softirq. Поток ядра же видим для планировщика задач CPU, это позволит избежать перегрузки процессора, на котором он работает, и сделать планирование userspace-процессов более детерминированным. Его проще контролировать системному администратору. Kthread можно связать с определенной группой CPU, чтобы явно отделить пользовательские потоки от процессоров, опрашивающих сетевые интерфейсы.
Изменения затронули в основном net/core/dev.c. Обновлен метод __napi_poll, вызываемый из контекста napi_poll. Появился новый sysfs атрибут в net_device для включения/выключения поточного режима опроса для всех экземпляров napi данного сетевого устройства без необходимости вызова up/down.
В napi_struct добавлено поле threaded для реализации опроса внутри потока, причем для включения поддержки потоков после создания kthread нужно вызвать napi_set_threaded (флаг NAPI_STATE_THREADED).
Обновленная структура napi_struct:
static int napi_kthread_create(struct napi_struct *n) < int err = 0; /* Create and wake up the kthread once to put it in * TASK_INTERRUPTIBLE mode to avoid the blocked task * warning and work with loadavg. */ n->thread = kthread_run(napi_threaded_poll, n, "napi/%s-%d", n->dev->name, n->napi_id); if (IS_ERR(n->thread)) < err = PTR_ERR(n->thread); pr_err("kthread_run failed with err %d\n", err); n->thread = NULL; > return err; >В связи с добавлением поточности появился новый метод napi_thread_wait.
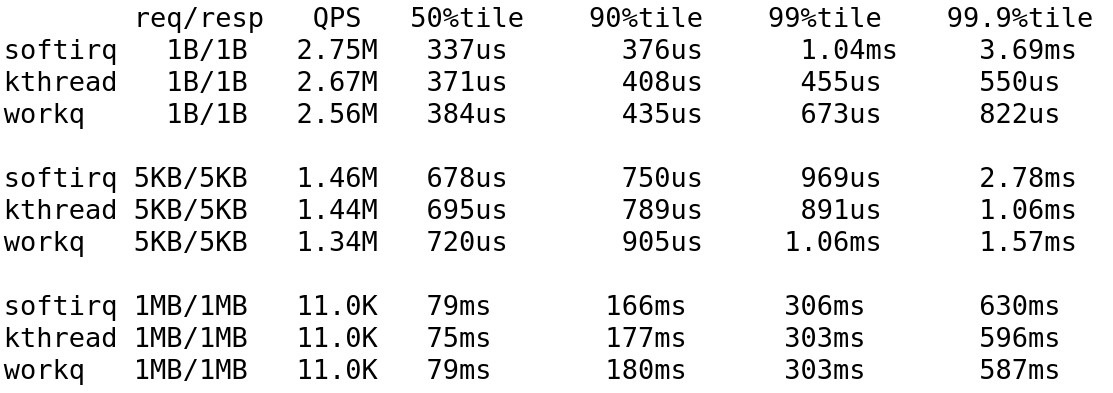
Wei Wang получил следующие результаты сравнения эффективности softirq, kthread и очередей отложенных действий:
Основные источники — LDD3 и статьи:
Заранее спасибо за уточнения и указания на ошибки!