Классификация сетевого трафика
Артемов, В. В. Классификация сетевого трафика / В. В. Артемов. — Текст : непосредственный // Молодой ученый. — 2022. — № 26 (421). — С. 7-9. — URL: https://moluch.ru/archive/421/93580/ (дата обращения: 13.07.2023).
Приведены классификация сетевого трафика, а также методы на основе порта, полезной нагрузки и статистики трафика.
Ключевые слова: сетевой трафик, TCP, HTTP, администрирование.
Важную роль при построении компьютерной сети любого масштаба играет возможность сетевого администратора получать информацию о сетевом трафике.
Классификация трафика — это процесс идентификации различных приложений и протоколов, существующих в сети. Классификация имеет решающее значение для сети, управления и безопасности. В частности, хорошо спроектированная сеть должна обеспечивать наличие модуля классификации трафика для определения приоритетов различных приложений в ограниченной полосе пропускания для обеспечения QoS — эффективного качества обслуживания. Системному администратору также важно правильно понимать приложения и протоколы, относящиеся к сетевому трафику, чтобы надлежащим образом разработать и внедрить эффективную политику безопасности.
В последние годы знание того, какая информация проходит через сети, становится все более и более сложной из-за постоянно растущего количества приложений, формирующих современный Интернет-трафик. Следовательно, мониторинг и анализ трафика стали критически важными для решения самых разных задач, от обнаружения вторжений, управления трафиком до планирования пропускной способности.
Классификация сетевого трафика — это процесс анализа характера потоков трафика в сетях, и он классифицирует эти уровни в основном на основе протоколов (например, TCP, UDP и IMAP) или по различным классам приложений (например, HTTP, одноранговые (P2P), игры).
Точная классификация трафика необходима для решения вопросов QoS (включая выделение ресурсов, ценообразование в Интернете и законный перехват (LI)), а также для задач мониторинга безопасности.
В настоящее время, например, сети Интернет-провайдеров в большинстве стран обязаны предоставлять возможность законного перехвата (L1) трафика. Категоризация трафика является основным решением этого юридического требования. Для идентификации сетевых потоков используются три типа методов классификации трафика, в том числе методы на основе порта, полезной нагрузки и статистики трафика.
Метод на основе портов зависит от тщательного изучения стандартных портов, используемых популярными приложениями. Однако на такой метод нельзя полагаться постоянно, поскольку не все существующие приложения используют стандартные порты.
Метод на основе полезной нагрузки в основном ищет запись приложения в полезной нагрузке IP-пакетов. В результате этот метод решает проблему динамических портов и, следовательно, широко используется во многих промышленных продуктах. Несмотря на свою популярность, этот метод на основе полезной нагрузки не работает с зашифрованным трафиком и требует значительного объёма ресурсов процессора и памяти.
В проводимых на сегодняшний день научных исследованиях метод, основанный на статистике потока, классифицирует трафик, создавая дополнительные новые функции из статистики потока (TLS), например, длину пакета и время прибытия пакета без необходимости глубокой проверки пакетов, а затем применяя контролируемую или неконтролируемую машину — алгоритмы обучения на данных TLS для классификации сетевого трафика по предопределённым категориям в зависимости от идентифицированных приложений.
На рис. 1 можно видеть поиск Microsoft Academic для подсчёта количества статей, соответствующих фразе «классификация трафика», «потоки трафика» или «идентификация трафика».
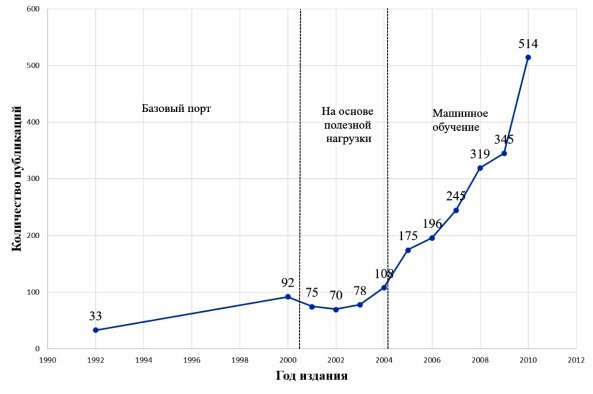
Рис. 1. Эволюция подходов к классификации сетевого трафика
Для идентификации Интернет-трафика использовались хорошо известные номера портов [1]. Такой подход оказался успешным, потому что традиционные приложения использовали фиксированные номера портов; однако существующие исследования показывают, что нынешнее поколение приложений P2P пытается скрыть свой трафик, используя динамические номера портов. Кроме того, приложения, номера портов которых неизвестны, не могут быть идентифицированы заранее.
Другой метод основан на проверке содержимого пакетов [2] и анализе полезной нагрузки пакетов, чтобы определить, содержат ли они сигнатуры известных или аномальных приложений. Функции извлекаются из данных о трафике, а затем сравниваются с известными сигнатурами приложений, предоставленными экспертами-людьми. Эти подходы очень хорошо работают для Интернет-трафика; однако исследования показывают, что эти подходы имеют ряд недостатков и противоречий. Во-первых, они не могут идентифицировать новые или неизвестные атаки и приложения, для которых недоступны сигнатуры, поэтому эти методы должны поддерживать актуальный список сигнатур. Это проблема, потому что каждый день появляются новые приложения и атаки; следовательно, нецелесообразно, а иногда и невозможно следить за последними подписями. Во-вторых, глубокая проверка пакетов — сложная задача, поскольку она требует значительного времени обработки и памяти. Наконец, если приложение использует шифрование, этот подход больше не работает.
Многообещающие подходы [3], которые в последнее время привлекли некоторое внимание, основаны на данных статистики транспортного уровня (TLS) и эффективном машинном обучении (ML). Это предполагает, что приложения обычно отправляют данные по некоторому шаблону, который можно использовать как средство классификации соединений по разным классам трафика. Для извлечения таких шаблонов необходимы только заголовки TCP/IP для наблюдения за статистикой потока, такой как средний размер пакета, длина потока и общее количество пакетов. Это позволяет методам классификации [3] иметь достаточно информации для работы.
- Ethan Bueno de Mesquita, Anthony Fowler. Thinking Clearly with Data: A Guide to Quantitative Reasoning and Analysis [Text]. — Princeton University Press, 2021. 400 с.
- Estan C., Savage S., Varghese G. Automatically inferring patterns of resource consumption in network traffic [Text] // SIGCOMM ’03: Proceedings of the 2003 conference on Applications, technologies, architectures, and protocols for computer communications. — 2003. — PP. 137–148.
- Nazarovs J., Stokes J. W., Turcotte M. J., Carroll J., & Grady I. (2022). Radial Spike and Slab Bayesian Neural Networks for Sparse Data in Ransomware Attacks [Electronic resource]. — URL: https://arxiv.org/abs/2205.14759 (дата обращения: 03.06.2022).
Основные термины (генерируются автоматически): сетевой трафик, TCP, TLS, приложение, HTTP, полезная нагрузка, IMAP, UDP, глубокая проверка пакетов, законный перехват.
Исследование сетевого трафика
Специально для будущих студентов курса «Network engineer. Basic» наш эксперт — Александр Колесников подготовил интересный авторский материал.
Также приглашаем принять участие в открытом онлайн-уроке на тему «STP. Что? Зачем? Почему?». Участники урока вместе с экспертом рассмотрят протокол STP, разберут логику его работы, разберут его преимущества и недостатки.

Статья расскажет, как можно работать с сетевым трафиком. На примере нескольких дампов сетевого трафика будет разобрана работа нескольких полезных инструментов, показаны подходы к извлечению и сборке информации из трафика.
Инструментарий и методика исследования
Для разбора трафиков будем использовать следующее программное обеспечение:
Все инструменты не нуждаются в особенно развернутом представлении, так как являются единственными в своем роде бесплатными решениями для работы с трафиком. Первые два tshark и wireshark вообще предоставляются в составе одного и того же решения. Оба инструмента позволяют выполнять запись и разбор трафика с точки зрения статистики, передаваемых данных и структурах протокола.
Попробуем использовать эти инструменты на записанных сетевых трафиках. Все трафики взяты из различных ресурсов и собраны вот здесь, поэтому читатель при желании может самостоятельно провести их анализ по инструкциям из статьи.
Disclamer: Все файлы трафиков взяты из различных соревнований CTF, все права на задания принадлежат их авторам.
Для исследования трафиков будем придерживаться минимальной стратегии:
- Определить количество участников сети;
- Определить стек используемых протоколов;
- На основании пункта 2 принять решение искать данные по убыванию популярности использования трафика;
- Если выясняется, что данные, которые передаются в трафике, не были обработаны дополнительным кодированием, то применять фильтр по тексту.
Примеры разбора трафика
Первое задание для разбора:
1.pcap(9cd84b46fee506dae818ecdca76607d1) . Задача — найти данные, которые будут содержать информацию вида FLAG-. . Приступим к разбору. Пройдемся по методике, которую описали в прошлом пункте:
Количество участников в сети очень просто определить при помощи WireShark (Всё, что описано для этого инструмента, можно повторить и на tshark . Автор использует WireShark для наглядности). В опциях WireShrak выбираем «Statistics->Endpoints»:
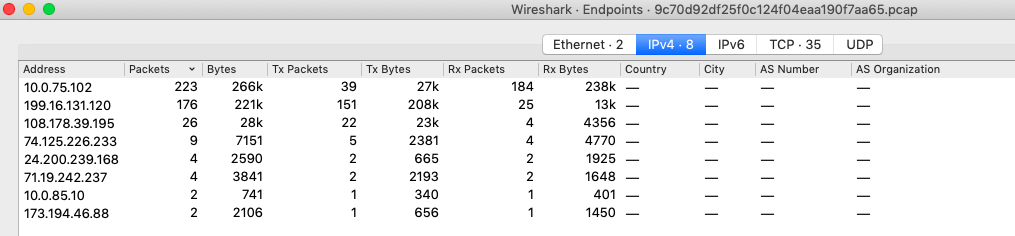
Итого у нас 8 уникальных IP адресов, которые участвовали во взаимодействии. Определим стек протоколов. Сделать это можно в том же самом меню «Statistics->Protocol Hierarchy»:
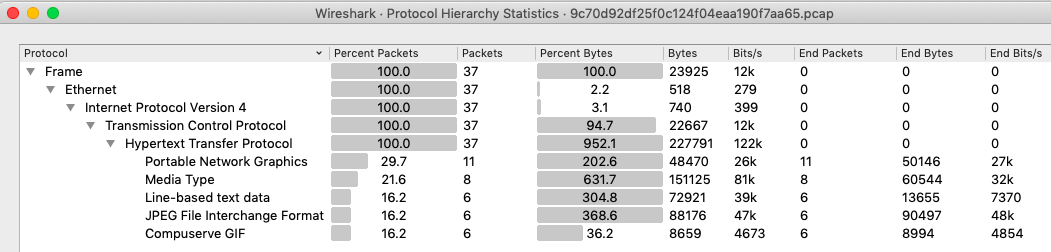
Итак, самый популярный протокол взаимодействия — http. Этот протокол внутри файла pcap хранится в текстовом представлении поэтому можно попробовать показать все данные из body пересылаемых данных и отфильтровать данные по формату искомой строки. Попробуем это сделать с помощью tshark . Команда для фильтра будет выглядеть так:
tshark -r ./1.pcap -Y http -Tfields -e http.file_data | grep "FLAG" В результате получаем результат:

Второй файл для исследования — 2.pcap (9a67e1fb9e529b7acfc6e91db6e1b092) . Проведем этапы исследования. Количество участников взаимодействия:
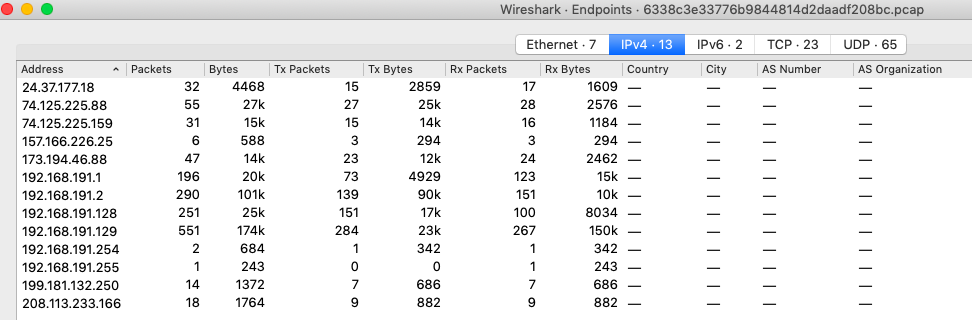
В этом случае участников 13 — задание усложняется. Какие протоколы используются:

К сожалению, в этот раз всё не так просто с используемыми протоколами для передачи данных. Среди информации пересылаемой через tcp протокол ничего интересного для нашего задания не встретилось. В udp же попалось кое-что интересное:
Однако, если обратить внимание на резолв локальных адресов через dns, то мы можем обнаружить вот такую картину:

Странная часть ip адреса, которая очень похожа на какие-то кодированные шестнадцатеричные символы. Попробуем их провести через кодировку:
tshark -r ./2.pcap -Y '!icmp.code && dns.qry.name contains 192.168' -Tfields -e dns.qry.name | tr '.' ' ' |awk '' |xxd -r
Полученная строка очень похожа на base64 кодировку, раскодируем:

В качестве целевого сетевого трафика будем использовать 3.pcap(0e66830db52ad51971d40c77fa5b02c0) . Проанализируем количество участников взаимодействия и статистику используемых протоколов:

Похоже, что в этот раз протоколов меньше, но вариантов куда спрятать данные — больше. Попробуем отфильтровать данные по протоколу http.

Самые интересные строки находятся в конце записанного трафика, это запросы http к файлам «flag.zip» и «secret.txt». Сдампим их через Wireshark и попробуем открыть:

Попробуем сдампить файл, который называется flag.zip через WireShark. Стандартным интерфейсом это сделать не получится, поэтому придется сделать небольшой хак — сохранить данные в Raw формате:

Открываем с уже найденным паролем:

Похоже, что файл поврежден в нем нет части, которая содержит необходимую нам информацию. Спустя время, если отфильтровать по потокам, которые есть в tcp, можно натолкнуться на части фрагменты архивов:
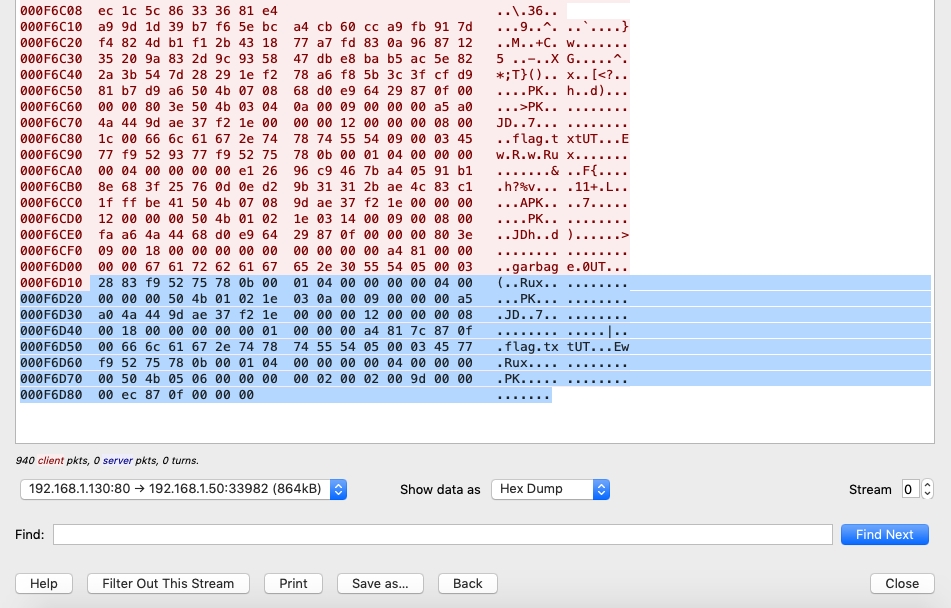
Сохраним дамп этого потока и вырежем с помощью простой программы фрагмент архива:
python data = [] with open('dump') as f: data = f.read() with open('tesst.zip','w') as w: w.write(data[1010788:])
Похоже, что часть данных недоступна, но мы смогли восстановить файл flag.txt
Описанная методика может позволить извлекать информацию из записанных сетевых данных. В качестве закрепления материала, предлагаем читателю найти данные в трафике 4.pcap(604bbac867a6e197972230019fb34b2e) .
Читать ещё:
- Сокеты в ОС Linux