- How to display certain lines from a text file in Linux?
- 10 Answers 10
- How to Read/Print a Particular Line from a File in Linux
- Example Reference File
- 1. Using Linux Head and Tail Commands
- 2. Using the Linux sed Command
- Using print with sed Command
- Using delete with sed Command
- Using the awk Linux Command
- How to Display Specific Lines of a File in Linux Command Line
- Display specific lines using head and tail commands
- Print a single specific line
- Print specific range of lines
- Use SED to display specific lines
- Use AWK to print specific lines from a file
- Get specific line from text file using just shell script
- 13 Answers 13
How to display certain lines from a text file in Linux?
I guess everyone knows the useful Linux cmd line utilities head and tail . head allows you to print the first X lines of a file, tail does the same but prints the end of the file. What is a good command to print the middle of a file? something like middle —start 10000000 —count 20 (print the 10’000’000th till th 10’000’010th lines). I’m looking for something that will deal with large files efficiently. I tried tail -n 10000000 | head 10 and it’s horrifically slow.
10 Answers 10
sed -n '10000000,10000020p' filename You might be able to speed that up a little like this:
sed -n '10000000,10000020p; 10000021q' filename In those commands, the option -n causes sed to «suppress automatic printing of pattern space». The p command «print[s] the current pattern space» and the q command «Immediately quit[s] the sed script without processing any more input. » The quotes are from the sed man page.
tail -n 10000000 filename | head -n 10 starts at the ten millionth line from the end of the file, while your «middle» command would seem to start at the ten millionth from the beginning which would be equivalent to:
head -n 10000010 filename | tail -n 10 The problem is that for unsorted files with variable length lines any process is going to have to go through the file counting newlines. There’s no way to shortcut that.
If, however, the file is sorted (a log file with timestamps, for example) or has fixed length lines, then you can seek into the file based on a byte position. In the log file example, you could do a binary search for a range of times as my Python script here* does. In the case of the fixed record length file, it’s really easy. You just seek linelength * linecount characters into the file.
* I keep meaning to post yet another update to that script. Maybe I’ll get around to it one of these days.
How to Read/Print a Particular Line from a File in Linux
File management is an important aspect of Linux administration. You get to access and manipulate different user and system files based on availed access right privileges.
This article seeks to boost your Linux file management prowess by walking us through the steps needed to read/print a particular line from a file in Linux.
There is more than one approach to achieving this article’s objective. We are going to break down these approaches one by one.
Example Reference File
We will be referencing the following sample text file throughout this tutorial. Proceed to create the file with the following command:
Populate the file with some lines of text from which we will be selecting random lines and printing them via relevant Linux commands.
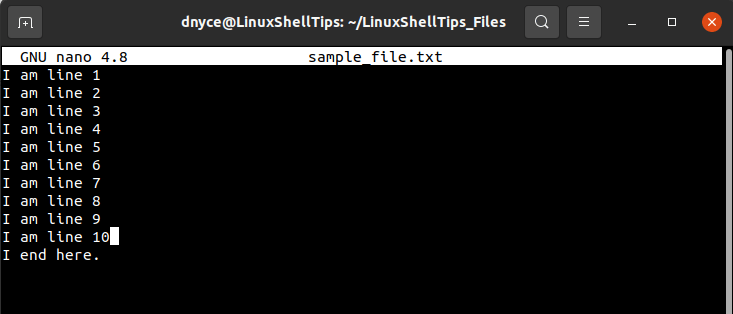
Let us use the cat command to view this file in a numbered view.
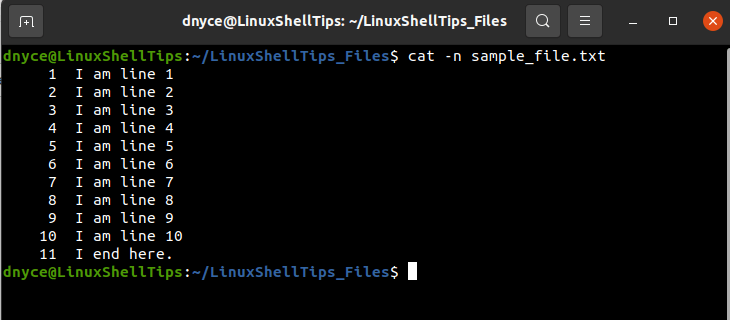
As per the above command output, we are dealing with a file that has 11 lines. We can now proceed and look at the available methods for printing/reading any of the above lines from the created sample_file.txt file.
1. Using Linux Head and Tail Commands
The head command on its own prints or outputs the first portion (usually the first 10 or so printable lines) of a text file to standard output.
The tail command on the other hand will output or print the last bit (usually the last 10 or so printable lines) of a text file to standard output.
Combining these two commands makes it possible to read/print a targeted text file line as demonstrated below:
$ cat sample_file.txt | head -5 | tail -1
The above command will read/print the 5th line (“I am line 5”) on the sample_file.txt file and print the output on our Linux terminal.

The cat command makes it possible to directly/interactively print the output of the above command execution of the terminal window.
2. Using the Linux sed Command
The default functionality of sed as described on its man page is to filter and transform text as a stream editor. It will take an input stream, filter, and transform it, before yielding the anticipated output.
There are two effective sed command approaches to reading/printing a particular line from a text file. The first approach utilizes the p (print) command while the second approach utilizes the d (delete) command.
A primary difference between these two commands is that the print command is associated with the -n option for indicating the text file line to print.
Using print with sed Command
We will print/read the third line (“I am line 3”) of the text file.
$ cat sample_file.txt | sed -n '3p'

Using delete with sed Command
We will print/read the seventh line (“I am line 7”) of the text file.
$ cat sample_file.txt | sed '7!d'

Using the awk Linux Command
The NR variable of the awk command keeps track of associated stream/file row numbers.
We can implement the awk command in three ways.
$ cat sample_file.txt | awk 'NR==9' [Prints 9th line] $ cat sample_file.txt | awk 'NR==10' [Prints 10th line] $ cat sample_file.txt | awk '' [Prints 11th line]
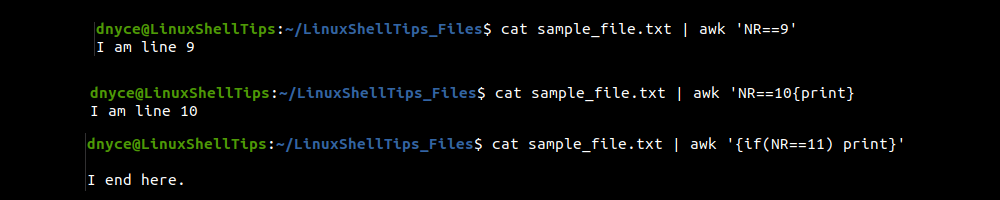
This article has effectively familiarized us with practical approaches to reading/printing specific lines (texts or characters) from files in a Linux OS environment.
How to Display Specific Lines of a File in Linux Command Line
Here are several ways to display specific lines of a file in Linux command line.
How do I find the nth line in a file in Linux command line? How do I display line number x to line number y?
In Linux, there are several ways to achieve the same result. Printing specific lines from a file is no exception.
To display the 13th line, you can use a combination of head and tail:
head -13 file_name | tail +13Or, you can use the sed command:
To display line numbers from 20 to 25, you can combine head and tail commands like this:
head -25 file_name | tail +20Or, you can use the sed command like this:
A detailed explanation of each command follows next. I’ll also show the use of the awk command for this purpose.
Display specific lines using head and tail commands
This is my favorite way of displaying lines of choice. I find it easier to remember and use.
Print a single specific line
Both head and tails commands are used to display the contents of a file in the terminal.
Use a combination of head and tail command in the following function the line number x:
You can replace x with the line number you want to display. So, let’s say you want to display the 13th line of the file.
[email protected]:~$ head -13 lines.txt | tail +13 This is line number 13Explanation: You probably already know that the head command gets the lines of a file from the start while the tail command gets the lines from the end.
The “head -x” part of the command will get the first x lines of the files. It will then redirect this output to the tail command. The tail command will display all the lines starting from line number x.
Quite obviously, if you take 13 lines from the top, the lines starting from number 13 to the end will be the 13th line. That’s the logic behind this command.
Print specific range of lines
Now let’s take our combination of head and tail commands to display more than one line.
Say you want to display all the lines from x to y. This includes the xth and yth lines also:
Let’s take a practical example. Suppose you want to print all the the lines from line number 20 to 25:
[email protected]:~$ head -25 lines.txt | tail +20 This is line number 20 This is line number 21 This is line number 22 This is line number 23 This is line number 24 This is line number 25Use SED to display specific lines
The powerful sed command provides several ways of printing specific lines.
For example, to display the 10th line, you can use sed in the following manner:
The -n suppresses the output while the p command prints specific lines. Read this detailed SED guide to learn and understand it in detail.
To display all the lines from line number x to line number y, use this:
[email protected]:~$ sed -n '3,7p' lines.txt This is line number 3 This is line number 4 This is line number 5 This is line number 6 This is line number 7Use AWK to print specific lines from a file
The awk command could seem complicated and there is surely a learning curve involved. But like sed, awk is also quite powerful when it comes to editing and manipulating file contents.
[email protected]:~$ awk 'NR==5' lines.txt This is line number 5NR denotes the ‘current record number’. Please read our detailed AWK command guide for more information.
To display all the lines from x to y, you can use awk command in the following manner:
It follows a syntax that is similar to most programming languages.
I hope this quick article helped you in displaying specific lines of a file in Linux command line. If you know some other trick for this purpose, do share it with the rest of us in the comment section.
Get specific line from text file using just shell script
I am trying to get a specific line from a text file. So far, online I have only seen stuff like sed, (I can only use the sh -not bash or sed or anything like that). I need to do this only using a basic shell script.
cat file | while read line do #do something done I know how to iterate through lines, as shown above, but what if I just need to get the contents of a particular line
13 Answers 13
What about with the sh command, I cannot use sed, awk. I should make this more clear in the question.
@GangstaGraham you said you know how to iterate through lines, how about adding a counter? if the counter reaches your target line number, get the line and break the loop. does it help?
@KanagaveluSugumar read sed’s info page. 5!d means delete all lines except 5. shell var is possible, you need double quotes.
I would suggest adding another variant: sed -n 5p This seems more logical to remember for newbies, because -n means «no output by default» and p stands for «print», and there’s no potentially confusing mention of deleting (when people talk of files, deleting lines tends to mean something different).
@JosipRodin you are right, -n ‘5p’ works for this problem too. The difference here is, with 5!d you can add -i to write the change back to the file. however, with -n 5p you have to sed -n ‘5p’ f > f2&& mv f2 f again, for this question, I am agree with your opinion.
Assuming line is a variable which holds your required line number, if you can use head and tail , then it is quite simple:
x=0 want=5 cat lines | while read line; do x=$(( x+1 )) if [ $x -eq "$want" ]; then echo $line break fi done This -eq comparison is for integers, so it wants a line number, not line content ( $line ). This has to be fixed by defining e.g. want=5 prior to the loop, and then using the -eq comparison on $want . [moved from a rejected edit]
@JosipRodin I made an independent edit suggestion based on your comment, as I agree with it. Hopefully this time it won’t be rejected.
@AntonOfTheWoods while using sed is obviously faster, it does not provide an answer to the question. If you missed it, the question explicitly states that sed is not usable, and sh is the only tool available.
You could use sed -n 5p file .
You can also get a range, e.g., sed -n 5,10p file .
Best performance method
Because sed stops reading any lines after the 5th one
I installed wcanadian-insane (6.6MB) and compared sed -n 1p /usr/share/dict/words and sed ‘1q;d’ /usr/share/dict/words using the time command; the first took 0.043s, the second only 0.002s, so using ‘q’ is definitely a performance improvement!
I installed wcanadian-insane (6.6MB) and compared sed -n 1p /usr/share/dict/words and sed ‘1q;d’ /usr/share/dict/words using the time command; the first took 0.043s, the second only 0.002s, so using ‘q’ is definitely a performance improvement!
Warning: using q in a sed command from a pipe will result in broken pipe . In that case, have to resort to sed -n 5p
@WilliamPursell sed -n 5q prints nothing for me. I think the answer is the best variant, but sed -n ‘5
If for example you want to get the lines 10 to 20 of a file you can use each of these two methods:
head -n 20 york.txt | tail -11 p in above command stands for printing.
The standard way to do this sort of thing is to use external tools. Disallowing the use of external tools while writing a shell script is absurd. However, if you really don’t want to use external tools, you can print line 5 with:
i=0; while read line; do test $((++i)) = 5 && echo "$line"; done < input-file Note that this will print logical line 5. That is, if input-file contains line continuations, they will be counted as a single line. You can change this behavior by adding -r to the read command. (Which is probably the desired behavior.)