Символы регулярных выражений linux
Для того, чтобы полностью реализовать потенциал командной оболочки, вам придется овладеть Регулярными Выражениями. Многие команды и утилиты, обычно используемые в сценариях, такие как grep, expr, sed и awk, используют Регулярные Выражения.
- Звездочка — * — означает любое количество символов в строке, предшествующих «звездочке», в том числе и нулевое число символов . Выражение «1133*» — означает 11 + один или более символов «3» + любые другие символы: 113, 1133, 113312, и так далее. Точка — . — означает не менее одного любого символа, за исключением символа перевода строки (\n). [2] Выражение «13.» будет означать 13 + по меньшей мере один любой символ (включая пробел): 1133, 11333, но не 13 (отсутствуют дополнительные символы).
- Символ — ^ — означает начало строки, но иногда, в зависимости от контекста, означает отрицание в регулярных выражениях. Знак доллара — $ — в конце регулярного выражения соответствует концу строки. Выражение «^$» соответствует пустой строке.
| Символы ^ и $ иногда еще называют якорями , поскольку они означают, или закрепляют, позицию в регулярных выражениях. |
bash$ cat textfile This is line 1, of which there is only one instance. This is the only instance of line 2. This is line 3, another line. This is line 4. bash$ grep 'the' textfile This is line 1, of which there is only one instance. This is the only instance of line 2. This is line 3, another line. bash$ grep '\' textfile This is the only instance of line 2.
# GNU версии sed и awk допускают использование "+", # но его необходимо экранировать. echo a111b | sed -ne '/a1\+b/p' echo a111b | grep 'a1\+b' echo a111b | gawk '/a1+b/' # Все три варианта эквивалентны. # Спасибо S.C.
bash$ echo 2222 | gawk --re-interval '/2/' 2222
bash$ egrep 're(a|e)d' misc.txt People who read seem to be better informed than those who do not. The clarinet produces sound by the vibration of its reed.
Некоторые версии sed, ed и ex поддерживают экранированные версии регулярных выражений, описанных выше.
bash$ grep [[:digit:]] test.file abc=723
bash$ ls -l ?[[:digit:]][[:digit:]]? -rw-rw-r-- 1 bozo bozo 0 Aug 21 14:47 a33b
Sed, awk и Perl, используемые в сценариях в качестве фильтров, могут принимать регулярные выражения в качестве входных аргументов. См. Пример A-13 и Пример A-19.
Примечания
В качестве простейшего регулярного выражения можно привести строку, не содержащую никаких метасимволов.
Поскольку с помощью sed, awk и grep обрабатывают одиночные строки, то обычно символ перевода строки не принимается во внимание. В тех же случаях, когда производится разбор многострочного текста, метасимвол «точка» будет соответствовать символу перевода строки.


Регулярные выражения в Linux
![]()
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Для работы в основном используются следующие символы:
- » ext» — слова начинающиеся с text
- «text/» — слова, заканчивающиеся на text
- «^» — начало строки
- «$» — конец строки
- «a-z» — диапазон от a до z
- «[^t]» — не буква t
- «[« — воспринять символ [ буквально
- «.» — любой символ
- «a|z» — а или z
Регулярные выражения в основном используются со следующими командами:
- egrep — расширенный grep
- fgrep — быстрый grep
- rgrep — рекурсивный grep
- sed — потоковый текстовый редактор.
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.
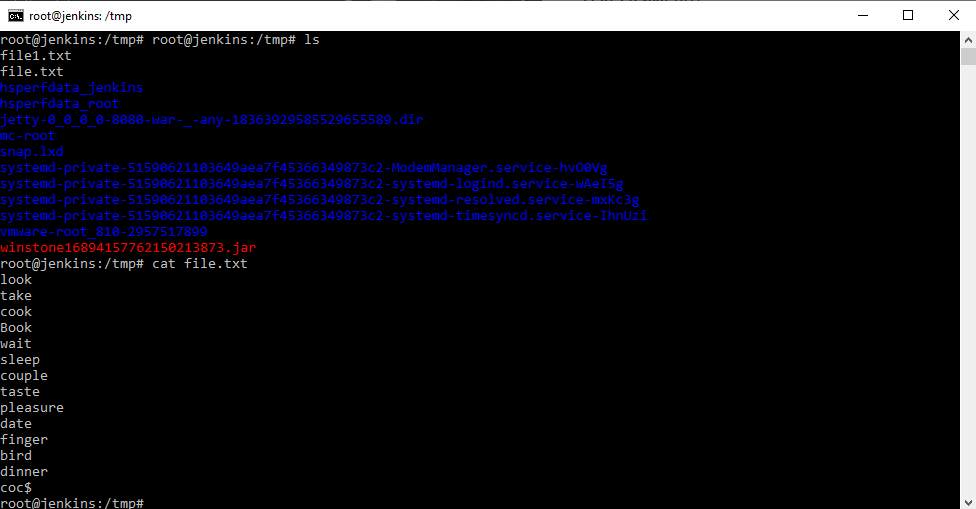
Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.
Первая команда — grep
Получаем справку по данной команде. Как можно понять из справки команда grep и ее производные — это печать линий совпадающих шаблонов. Проще говоря, команда grep помогает сортировать те данные, что мы даем команде, через знак конвейера на ввод. Причем в мануале мы можем видеть egrep, fgrep и т.д. данные команды мы можем не использовать. Использовать можно только grep с ключами различными, т.е. ключи просто заменяют эти команды. Можно на примере посмотреть, как работает данная команда. Например, grep oo file.txt
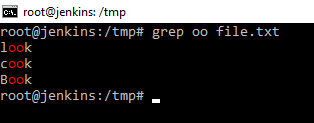
На картинке видно, что команда из указанного файла выбрала по определенному шаблону «oo». Причем даже делает красным цветом подсветку. Можно добавить еще ключик -n, тогда данная команда еще и выведет номер строки в которой находится то, что ищется по шаблону. Это полезно, когда работаем с каким-нибудь кодом или сценарием. Когда необходимо, что-то найти. Сразу видим, где находится объект поиска или что-то ищем по логам.
При использовании шаблона очень важно понимать, что команда grep, чувствительна к регистрам в шаблонах. Это означает, что Boo и boo это разные шаблоны. В одном случае команда найдет слово, а в другом нет. Можно команде сказать, чтобы она не учитывала регистр. Это делается с помощью ключа -i.
Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.
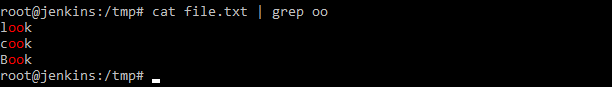
Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.
Давайте найдем файлы в которых содержится сочетание «ple«. grep ple file.txt в данном случае команда нашла оба слова содержащие шаблон. Давайте найдем слово, которое будет начинаться с «ple«. Команда будет выглядеть следующим образом: grep ^ple file.txt . Значок «^» указывает на начало строки. Противоположная задача найти слова, заканчивающиеся на «ple«. Команда будет выглядеть следующим образом grep ple$ file.txt . Т.е. применять к концу строки, говорит значок «$» в шаблоне.

Можно дать команду grep .o file.txt. В данном выражении знак «.» , заменяет любую букву.

Как вы видите вывод шаблона «.ple» вывел только одно слово т.к только слово couple удовлетворяло шаблону , т.к перед «ple» должен был содержаться еще один символ любой.
Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
man egrep — отошлет к справке по grep.
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.
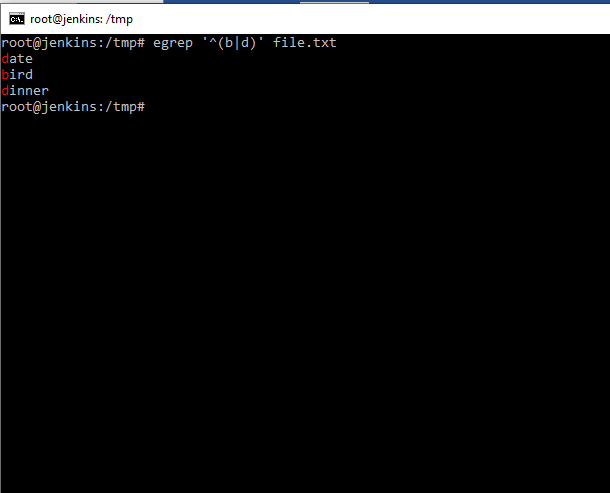
Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:
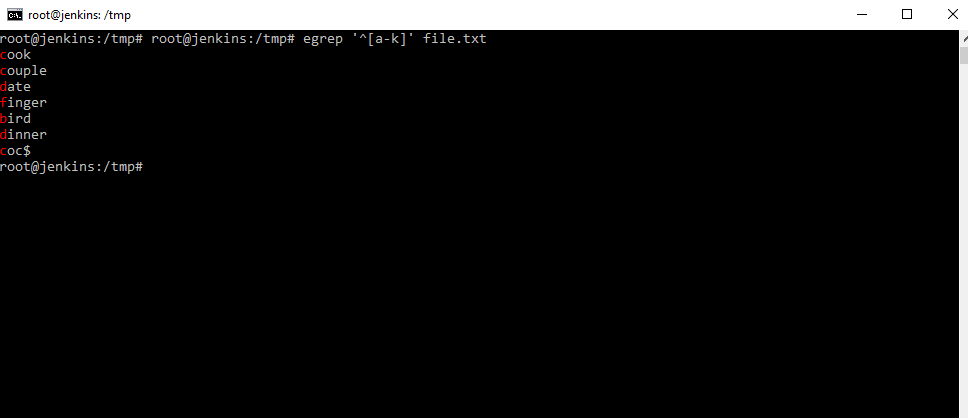
Получим все слова, начинающиеся с «a» по «к». Знак «[]» — диапазона. Как мы видим слова, начинающиеся с большой буквы, не попали. Все эти регулярные выражения очень пригодятся, когда мы что-то ищем в файлах логах.
Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Как вариант egrep можно запускать просто grep с ключиком -e.
Про fgrep
man fgrep — отошлет к справке по grep. Команда fgrep не понимает регулярных выражений вообще.
Получается следующим образом если мы вводим: egrep c$ file.txt . То команда согласно шаблону, ищет в файле букву «c» в конце слова. В случае же с командой fgrep c$ file.txt , команда будет искать именно сочетание «с$». Т.е. команда fgrep воспринимает символы регулярных выражений, как обычные символы, которые ей нужно найти, как аргументы.
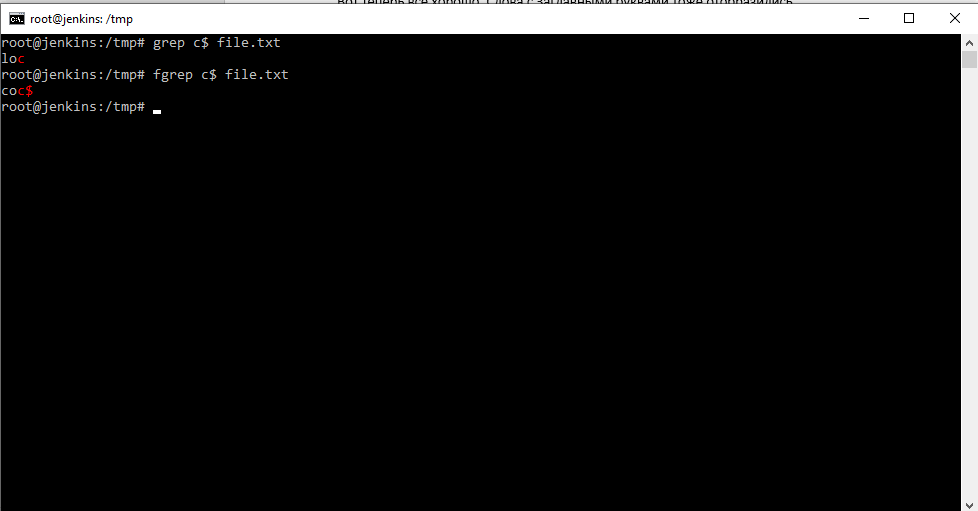
Рекурсивный rgrep
Создадим каталог mkdir folder . Создадим файл great.txt в созданной директории folder со словом Hello при помощью команды echo «Hello» folder/great.txt
И если мы скажем grep Hello * , поищи слово Hello в текущей директории. Получится следующая картина.
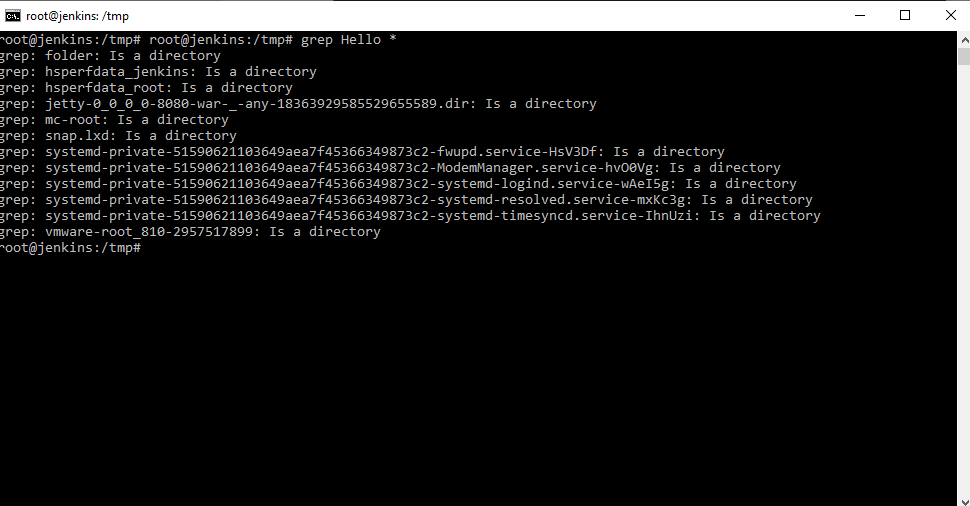
Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
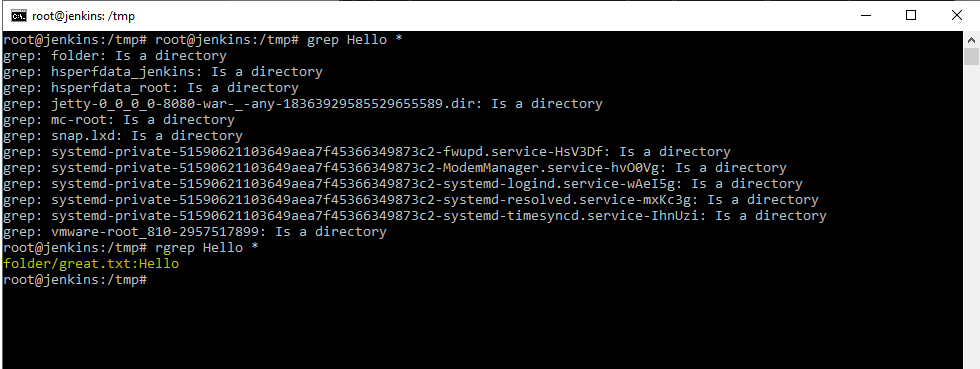
Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Данная утилита пробежалась по всем папкам и файлам в них и нашла подходящее под шаблон слово. Т.е. если нам необходимо провести поиск по всем файлам и папкам, то необходимо использовать утилиту rgrep .
Команда sed
man sed — стрим редактор. Т.е потоковый редактор для фильтрации и редактирования потока данных.
Например, sed -e ‘s/oo/aa’ file.txt — открыть редактор sed и заменить вывод всех oo на aa в файле file.txt. Нужно понимать, что в результате данной команды изменения в файле не произойдут. Просто данные из файла будут взяты и с изменениями выведены на стандартный вывод, т.е. экран. Для сохранения результатов мы можем сказать, чтобы вывел в новый файл указав направление вывода.
sed -e ‘s/oo/aa’ file.txt newfile.txt
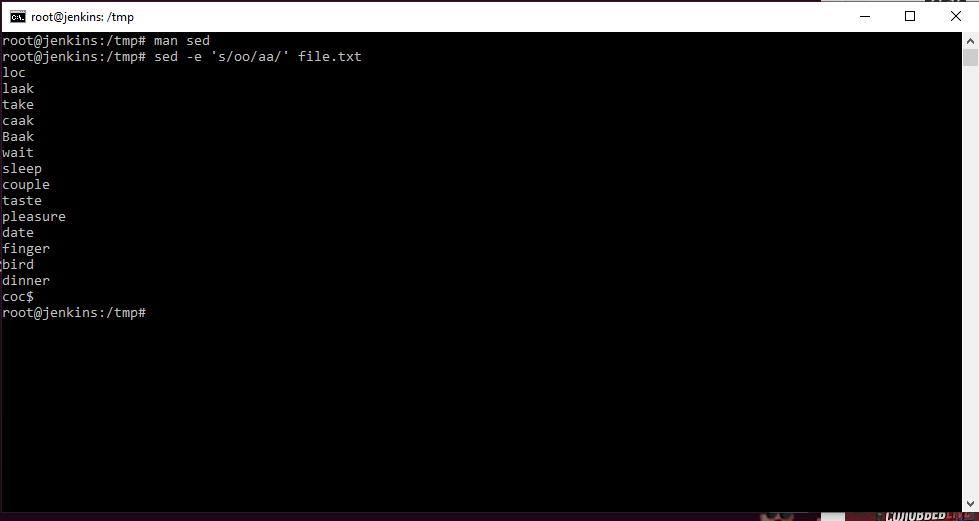
В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.