Система сборки make linux
NAME
make - GNU make utility to maintain groups of programs
SYNOPSIS
DESCRIPTION
The make utility will determine automatically which pieces of a large program need to be recompiled, and issue the commands to recompile them. The manual describes the GNU implementation of make, which was written by Richard Stallman and Roland McGrath, and is currently maintained by Paul Smith. Our examples show C programs, since they are very common, but you can use make with any programming language whose compiler can be run with a shell command. In fact, make is not limited to programs. You can use it to describe any task where some files must be updated automatically from others whenever the others change. To prepare to use make, you must write a file called the makefile that describes the relationships among files in your program, and the states the commands for updating each file. In a program, typically the executable file is updated from object files, which are in turn made by compiling source files. Once a suitable makefile exists, each time you change some source files, this simple shell command: make suffices to perform all necessary recompilations. The make program uses the makefile description and the last-modification times of the files to decide which of the files need to be updated. For each of those files, it issues the commands recorded in the makefile. make executes commands in the makefile to update one or more target names, where name is typically a program. If no -f option is present, make will look for the makefiles GNUmakefile, makefile, and Makefile, in that order. Normally you should call your makefile either makefile or Makefile. (We recommend Makefile because it appears prominently near the beginning of a directory listing, right near other important files such as README.) The first name checked, GNUmakefile, is not recommended for most makefiles. You should use this name if you have a makefile that is specific to GNU make, and will not be understood by other versions of make. If makefile is '-', the standard input is read. make updates a target if it depends on prerequisite files that have been modified since the target was last modified, or if the target does not exist.
OPTIONS
-b, -m These options are ignored for compatibility with other versions of make. -B, --always-make Unconditionally make all targets. -C dir, --directory=dir Change to directory dir before reading the makefiles or doing anything else. If multiple -C options are specified, each is interpreted relative to the previous one: -C / -C etc is equivalent to -C /etc. This is typically used with recursive invocations of make. -d Print debugging information in addition to normal processing. The debugging information says which files are being considered for remaking, which file-times are being compared and with what results, which files actually need to be remade, which implicit rules are considered and which are applied---everything interesting about how make decides what to do. --debug[=FLAGS] Print debugging information in addition to normal processing. If the FLAGS are omitted, then the behavior is the same as if -d was specified. FLAGS may be a for all debugging output (same as using -d), b for basic debugging, v for more verbose basic debugging, i for showing implicit rules, j for details on invocation of commands, and m for debugging while remaking makefiles. Use n to disable all previous debugging flags. -e, --environment-overrides Give variables taken from the environment precedence over variables from makefiles. -f file, --file=file, --makefile=FILE Use file as a makefile. -i, --ignore-errors Ignore all errors in commands executed to remake files. -I dir, --include-dir=dir Specifies a directory dir to search for included makefiles. If several -I options are used to specify several directories, the directories are searched in the order specified. Unlike the arguments to other flags of make, directories given with -I flags may come directly after the flag: -Idir is allowed, as well as -I dir. This syntax is allowed for compatibility with the C preprocessor's -I flag. -j [jobs], --jobs[=jobs] Specifies the number of jobs (commands) to run simultaneously. If there is more than one -j option, the last one is effective. If the -j option is given without an argument, make will not limit the number of jobs that can run simultaneously. -k, --keep-going Continue as much as possible after an error. While the target that failed, and those that depend on it, cannot be remade, the other dependencies of these targets can be processed all the same. -l [load], --load-average[=load] Specifies that no new jobs (commands) should be started if there are others jobs running and the load average is at least load (a floating-point number). With no argument, removes a previous load limit. -L, --check-symlink-times Use the latest mtime between symlinks and target. -n, --just-print, --dry-run, --recon Print the commands that would be executed, but do not execute them (except in certain circumstances). -o file, --old-file=file, --assume-old=file Do not remake the file file even if it is older than its dependencies, and do not remake anything on account of changes in file. Essentially the file is treated as very old and its rules are ignored. -O[type], --output-sync[=type] When running multiple jobs in parallel with -j, ensure the output of each job is collected together rather than interspersed with output from other jobs. If type is not specified or is target the output from the entire recipe for each target is grouped together. If type is line the output from each command line within a recipe is grouped together. If type is recurse output from an entire recursive make is grouped together. If type is none output synchronization is disabled. -p, --print-data-base Print the data base (rules and variable values) that results from reading the makefiles; then execute as usual or as otherwise specified. This also prints the version information given by the -v switch (see below). To print the data base without trying to remake any files, use make -p -f/dev/null. -q, --question ``Question mode''. Do not run any commands, or print anything; just return an exit status that is zero if the specified targets are already up to date, nonzero otherwise. -r, --no-builtin-rules Eliminate use of the built-in implicit rules. Also clear out the default list of suffixes for suffix rules. -R, --no-builtin-variables Don't define any built-in variables. -s, --silent, --quiet Silent operation; do not print the commands as they are executed. -S, --no-keep-going, --stop Cancel the effect of the -k option. This is never necessary except in a recursive make where -k might be inherited from the top-level make via MAKEFLAGS or if you set -k in MAKEFLAGS in your environment. -t, --touch Touch files (mark them up to date without really changing them) instead of running their commands. This is used to pretend that the commands were done, in order to fool future invocations of make. --trace Information about the disposition of each target is printed (why the target is being rebuilt and what commands are run to rebuild it). -v, --version Print the version of the make program plus a copyright, a list of authors and a notice that there is no warranty. -w, --print-directory Print a message containing the working directory before and after other processing. This may be useful for tracking down errors from complicated nests of recursive make commands. --no-print-directory Turn off -w, even if it was turned on implicitly. -W file, --what-if=file, --new-file=file, --assume-new=file Pretend that the target file has just been modified. When used with the -n flag, this shows you what would happen if you were to modify that file. Without -n, it is almost the same as running a touch command on the given file before running make, except that the modification time is changed only in the imagination of make. --warn-undefined-variables Warn when an undefined variable is referenced.
EXIT STATUS
GNU make exits with a status of zero if all makefiles were successfully parsed and no targets that were built failed. A status of one will be returned if the -q flag was used and make determines that a target needs to be rebuilt. A status of two will be returned if any errors were encountered.
SEE ALSO
The full documentation for make is maintained as a Texinfo manual. If the info and make programs are properly installed at your site, the command info make should give you access to the complete manual.
BUGS
See the chapter ``Problems and Bugs'' in The GNU Make Manual.
AUTHOR
This manual page contributed by Dennis Morse of Stanford University. Further updates contributed by Mike Frysinger. It has been reworked by Roland McGrath. Maintained by Paul Smith.
Так все же, зачем нужен make?

Все началось, казалось бы, с простого вопроса, который сначала ввел меня в ступор — «Зачем нужен make? Почему нельзя обойтись bash скриптами?». И я подумал — Действительно, зачем нужен make? (и самое важное) Какие проблемы он решает?
Тут я решил немного подумать — как бы мы собирали свои проекты, если бы у нас не было make. Допустим, мы имеем проект с исходниками. Из них нужно получить исполняемый файл (или библиотеку). На первый взгляд задача вроде простая, но пошли дальше. Пусть на начальном этапе проект состоит из одного файла.
Для его компиляции достаточно выполнить одну команду:
Это было довольно просто. Но проходит некоторое время, проект развивается, в нем появляются некоторые модули и исходных файлов становится больше.

Для компиляции нужно выполнить условно вот такое количество команд:
$ gcc -c src0.c $ gcc -c src1.c $ gcc -c main.c $ gcc -o main main.o src0.o src1.oСогласитесь, это довольно длительный и кропотливый процесс. Выполнять это вручную я бы не стал. Я бы подумал, что этот процесс можно автоматизировать, просто создав скрипт build.sh, который бы содержал эти команды. Окей, так намного проще:
Погнали дальше! Проект растет, количество файлов с исходниками увеличивается и строк в них тоже становится больше. Мы начинаем замечать, что время компиляции заметно возросло. Тут мы видим существенную недоработку нашего скрипта — он выполняет компиляцию всех наших 50 файлов с исходниками, хотя мы модифицировали только один.
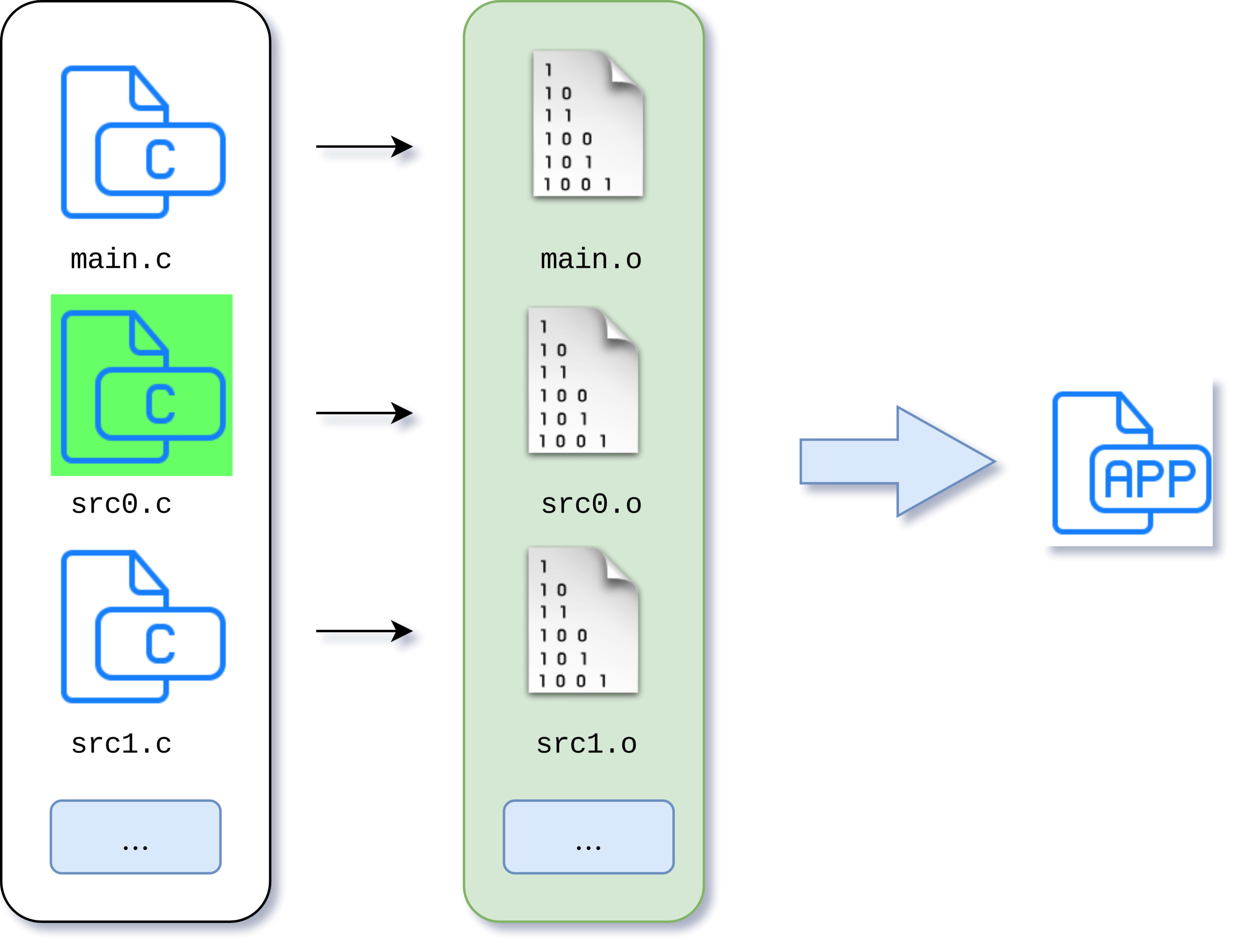
Так не пойдет! Время разработчика слишком ценный ресурс. Что же, мы можем попытаться доработать скрипт сборки таким образом, чтобы перед компиляцией производилась проверка времени модификации исходников и объектных файлов. И компилировать только те исходники, которые были изменены. И условно это может выглядеть как-то так:
#!/bin/bash function modification_time < date -r "$1" '+%s' >function check_time < local name=$1 [ ! -e "$name.o" ] && return $? [ "$(modification_time "$name.c")" -gt "$(modification_time "$name.o")" ] && return $? >check_time src0 && gcc -c src0.c check_time src1 && gcc -c src1.c check_time main && gcc -c main.c gcc -o main main.o src0.o src1.oИ теперь компилироваться будут только те исходники, которые были модифицированы.
Но что произойдет, когда проект превратится во что-нибудь подобное:
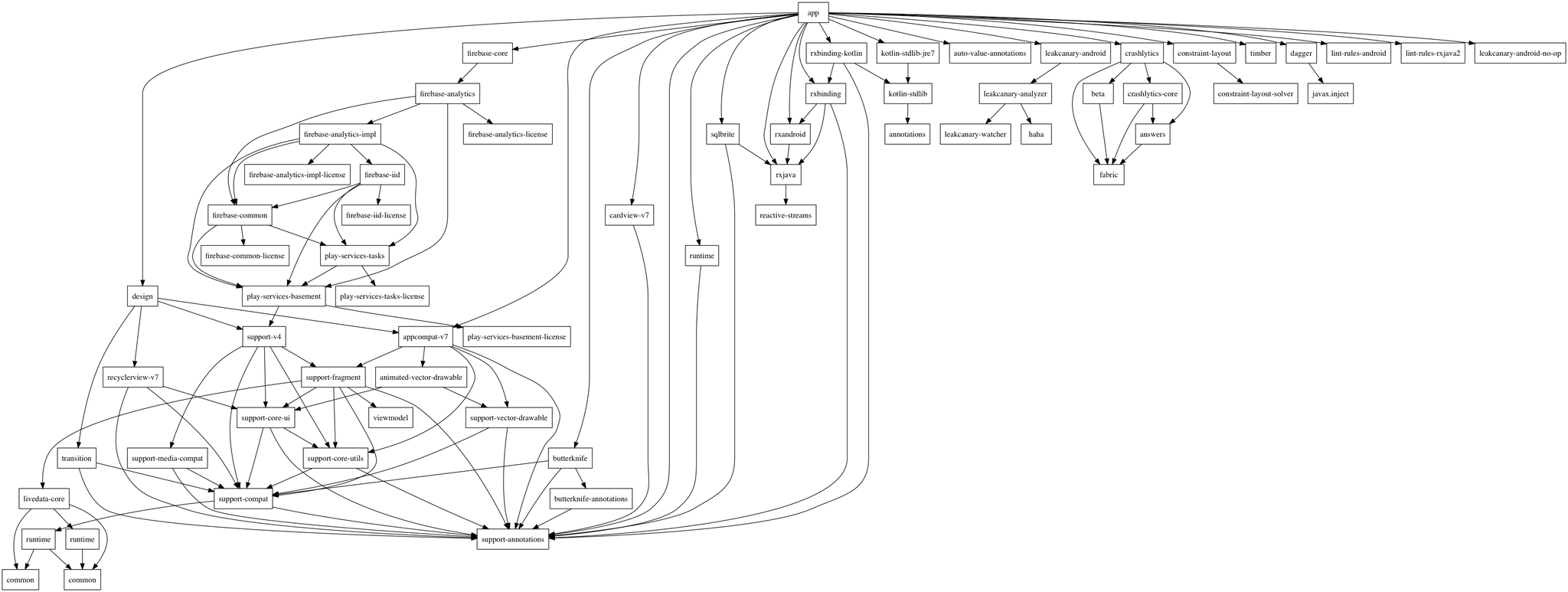
Рано или поздно наступит такой момент, когда в проекте будет очень сложно разобраться и сама по себе поддержка подобных скриптов станет трудоемким процессом. И не факт, что этот скрипт будет производить адекватную проверку всех зависимостей. К тому же, у нас может быть несколько проектов и у каждого будет свой скрипт для сборки.
Само собой мы видим, что напрашивается какое то общее решение этой проблемы. Инструмент, который бы предоставил механизм для проверки зависимостей. И вот тут мы потихоньку подобрались к изобретению make. И теперь, зная с какими проблемами мы столкнемся в процессе сборки проекта, в конце концов я бы сформулировал следующие требования к make:
- анализ временных меток зависимостей и целей
- выполнение минимального объема работы, необходимого для того, чтобы гарантировать актуальность производных файлов
- (ну и + параллельное выполнение команд)
Makefile
Для описания правил сборки проекта используются Makefile’ы. Создавая Makefile, мы декларативно описываем определенное состояние отношений между файлами. Декларативный характер определения состояния удобен тем, что мы говорим, что у нас есть некоторый список файлов и из них нужно получить новый файл, выполнив некоторый список команд. В случае использования какого-либо императивного языка (например, shell) нам приходилось бы выполнять большое количество различных проверок, получая на выходе сложный и запутанный код, тогда как make делает это за нас. Главное построить правильное дерево зависимостей.
Не буду рассказывать про то, как писать Makefile’ы. В интернете очень много мануалов на эту тему и при желании можно обратиться к ним. И к тому же, мало кто пишет Makefile’ы вручную. А очень сложные Makefile’ы могут стать источником осложнений вместо того, чтобы упростить процесс сборки.