Распределенные базы данных
Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Однако пользователь распределенной базы данных не обязан знать, каким образом ее компоненты размещены в узлах сети, и представляет себе эту базу данных как единое целое (данное свойство называют прозрачность). Работа с такой базой данных осуществляется с помощью системы управления распределенной базой данных (СУРБД). Части распределенной базы данных, размещенные на отдельных ЭВМ сети, могут управляться собственными (локальными) СУБД. Локальные СУБД не обязательно должны быть одинаковыми в разных узлах сети. Объединение неоднородных локальных баз данных в единую распределенную базу данных является сложной научно-технической проблемой. Ее решение потребовало проведения большого комплекса научных исследований и экспериментальных разработок.
Программное обеспечение систем управления распределенными базами данных (СУРБД) обычно имеет многоуровневую архитектуру (рис. 1).
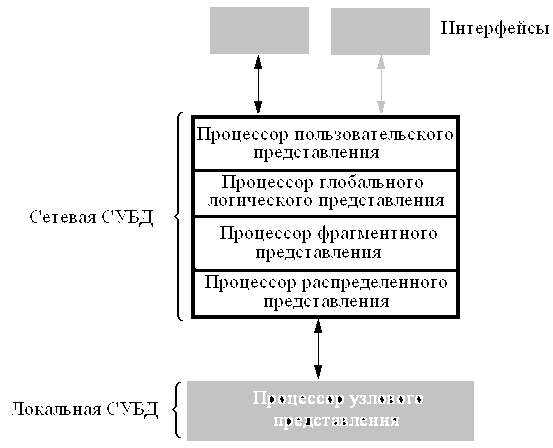
Рис. 1. Уровни распределенной БД
Следует различать работу с распределенной БД и работу с удаленными БД. Во втором случае пользователь явно соединяется с источником данных.
2. Основные принципы распределенной обработки
Рассмотрим основные принципы распределенной обработки.
Локальная автономия. Данный принцип означает, что операции на данном узле управляются им же, не требуется ожидания от других узлов, хотя в реальных системах автономия неполная, т.к. есть много ситуаций, когда требуется согласованная работа узлов.
Независимость от центрального узла. Принцип означает, что все узлы выступают как равные, иначе при повреждении центра может выйти из строя вся система.
Непрерывное функционирование. Принцип означает, что системы должны быть высоко надежны и данные доступны. Надежность – это вероятность того, что система исправна и работает в любой заданный момент времени. Системы могут поддерживать весь спектр методов повышения надежности (зеркальные диски, резервные серверы, многомашинные кластеры и т.д.)
Независимость от расположения. Принцип означает прозрачность расположения данных.
Независимость от фрагментации. Таблица разбивается на группы, которые хранятся на разных дисковых разделах (дисках). Фрагментация желательна для повышения производительности системы, т.к. части таблиц читаются одновременно. Повышается доступность таблицы, даже если ее части повреждены, снижается конкурентность операций. Данные лучше хранить там, где их чаще используют. Существуют два основных вида фрагментации: вертикальная и горизонтальная (фактически это операции проекции и выборки).
Независимость от репликации. Репликация полезна по двум причинам: для повышения производительности и увеличения доступности. Асинхронная асимметричная – это репликация, когда один узел – владелец основной мастер-копии таблицы с возможностью внесения изменений в нее и автоматической поддержкой неограниченного числа копий в других узлах, с доступом только чтение. Асинхронная симметричная – это репликация данных, когда данные доступны для изменения в любом узле и автоматически распространяются на все копии.
Обработка распределенных запросов. В распределенных системах имеется сложный оптимизатор, т.к. чрезвычайно важно найти наиболее эффективную стратегию выполнения запроса. Возможны использование параллельных операций. Оптимальная пересылка данных между узлами. Подключение индексов.
Управление распределенными транзакциями. Базовой конструкцией, которая позволяет фиксировать «правильное» состояние БД, является транзакция. Под транзакцией понимают такую логическую единицу работы с БД, которая не приводит ее в непротиворечивое состояние. Она может включать сотни операций (например, UPDATE-запросов) и в момент работы БД может находиться в противоречивом состоянии. Но по завершении БД должна быть в согласованном состоянии. Иными словами транзакция – выполнение в качестве атомарного (неделимого) действия одной и более операций над БД, не приводящее к нарушению целостности БД.
Двухфазная фиксация транзакции – когда транзакция выполняется под управлением одного сервера-координатора. Первая фаза: координатор, получив инструкцию СOMMIT, рассылает остальным серверам сообщения о подготовке к фиксации. Серверы отвечают о возможности фиксации. Вторая фаза: координатор, получив все подтверждения, принимает решение о фиксации или об отмене транзакции. Непротиворечивость данных может поддерживаться с помощью триггеров и хранимых процедур. Триггеры – способ автоматизации действий над БД. Триггер – это специальная процедура, которая срабатывает при определенном условии, операции и т.п. Хранимая процедура хранится в откомпилированном и оптимизированном виде на сервере, в результате часть вычислений переносится с машин-клиентов на сервер, сокращается сетевой трафик.
Распределенный словарь данных. Словарь состоит не только из обычной для него информации, но и хранит всю информацию о размещении, фрагментации, репликации. Сам словарь может находиться в одном узле, быть полностью или частично реплицированным.
Многомасштабность и многоплатформность. Данный принцип означает независимость от аппаратуры, независимость от операционной системы, независимость от сети.
Независимость от СУБД. Принцип означает уход от однородности. Все СУБД должны поддерживать один и тот же интерфейс. В неоднородных системах требуются специальные программы – шлюзы для организации прозрачного обмена между разными СУБД.
6.5. Распределенные базы данных и субд
Технология распределенных баз данных, получившая в настоящее время широкое распространение, способствует обратному переходу от централизованной обработки данных к децентрализованной. Создание технологии систем управления распределенными базами данных является одним самых больших достижений в области баз данных. Технология распределенных баз данных – симбиоз сетевых технологий и технологий баз данных при доминирующей роли первых (более важным аспектом является распределенность системы).
6.5.1. Понятие распределенных баз данных и субд
Основной причиной разработки систем, использующих базы данных, является стремление интегрировать все обрабатываемые в организации данные в единое Целое и обеспечить к ним контролируемый доступ. Хотя интеграция и предоставление контролируемого доступа могут способствовать централизации, последняя не является самоцелью. На практике создание компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный подход отражает организационную структуру компании, логически состоящую из отдельных подразделений, отделов, проектных групп и тому подобного, которые физически распределены по разным офисам, отделениям, предприятиям или филиалам, причем каждая отдельная единица имеет дело с собственным набором обрабатываемых данных.
Разработка распределенных баз данных позволяет сделать данные, поддерживаемые каждым из существующих подразделений организации, общедоступными, обеспечив при этом их сохранение именно в тех местах, где они чаще всего используются. Подобный подход расширяет возможности совместного использования информации, одновременно повышая эффективность доступа к ней.
Распределенные системы призваны разрешить проблему островов информации.Базы данных иногда рассматривают как некие электронные острова, представляющие собой отдельные и, в общем случае, труднодоступные места, подобные удаленным друг от друга островам. Данное положение может являться следствием географической разобщенности, несовместимости используемой компьютерной архитектуры, несовместимости используемых коммутационных протоколов и т.д. Интеграция отдельных баз данных в одно логическое целое способна изменить подобное положение дел.
Распределенная база данных –набор логически связанных между собой разделяемых данных (и их описаний), которые физически распределены в некоторой компьютерной сети.Распределенная СУБД –программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распределенность информации прозрачной для конечного пользователя.
Система управления распределенными базами данных (СУРБД) состоит из единой логической базы данных, разделенной на некоторое количество фрагментов.Каждый фрагмент базы данных сохраняется на одном или нескольких компьютерах, которые соединены между собой линиями связи и каждый из которых работает под управлением отдельной СУБД. Любой из сайтов способен независимо обрабатывать запросы пользователей, требующие доступа к локально сохраняемым данным (что создает определенную степень локальной автономии), а также способен обрабатывать данные, сохраняемые на других компьютерах сети.
Пользователи взаимодействуют с распределенной базой данных через приложения. Приложения могут быть классифицированы как те, которые не требуют доступа к данным на других сайтах (локальные приложения),и те, которые требуют подобного доступа(глобальные приложения).В распределенной СУБД должно существовать хотя бы одно глобальное приложение, поэтому любая СУРБД должна иметь следующие особенности:
- Набор логически связанных разделяемых данных.
- Сохраняемые данные разбиты на некоторое количество фрагментов.
- Между фрагментами может быть организована репликация данных.
- Фрагменты и их реплики распределены по различным сайтам.
- Сайты связаны между собой сетевыми соединениями.
- Работа с данными на каждом сайте управляется СУБД.
- СУБД на каждом сайте способна поддерживать автономную работу локальных приложений.
- СУБД каждого сайта поддерживает хотя бы одно глобальное приложение.