- SkipFish — Web Application Scanner
- SkipFish Key Features
- How to use SkipFish on Kali Linux
- Как пользоваться SkipFish на Kali Linux
- Что такое SkipFish
- Использование SkipFish на Kali Linux
- Skipfish on kali linux
- Learn Latest Tutorials
- Preparation
- Trending Technologies
- B.Tech / MCA
- Javatpoint Services
- Training For College Campus
- Tool Documentation:
- Packages and Binaries:
- skipfish
SkipFish — Web Application Scanner
SkipFish is an active web application security scanner developed by Google’s information security engineering team, Michal Zalewski, Niels Heinen and Sebastian Roschke.
SkipFish comes preinstalled with Kali Linux and it can identify various vulnerabilities inside a web application.
SkipFish Key Features
SkipFish have some advantages they are following:
- High performance: 500+ requests per second against responsive Internet targets, 2000+ requests per second on LAN / MAN networks, and 7000+ requests against local instances have been observed, with a very modest CPU, network, and memory footprint.
- Well-designed security checks: the tool is meant to provide accurate and meaningful results.
- Automatic wordlist construction based on site content analysis.
- Probabilistic scanning features to allow periodic, time-bound assessments of arbitrarily complex sites.
- Handcrafted dictionaries offer excellent coverage and permit thorough $keyword.$extension testing in a reasonable timeframe.
- Three-step differential probes are preferred to signature checks for detecting vulnerabilities.
- Ratproxy-style logic is used to spot subtle security problems: cross-site request forgery, cross-site script inclusion, mixed content, issues MIME- and charset mismatches, incorrect caching directives, etc.
- Bundled security checks are designed to handle tricky scenarios: stored XSS (path, parameters, headers), blind SQL or XML injection, or blind shell injection.
- Snort style content signatures which will highlight server errors, information leaks or potentially dangerous web applications.
- Report post-processing drastically reduces the noise caused by any remaining false positives or server gimmicks by identifying repetitive patterns.
How to use SkipFish on Kali Linux
As we previously said that SkipFish comes pre-installed with Kali Linux (Full version) so we don’t need to install it (if not we can use sudo apt install skipfish ).
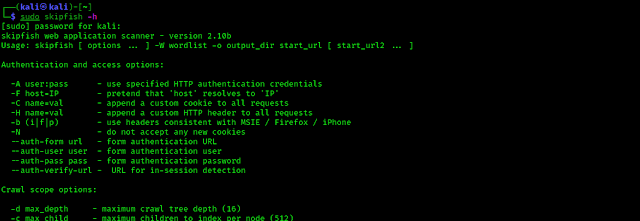
We can check it’s options by entering following command on our terminal:
The following screenshot shows the output of the preceding command and the help of SkipFish tool.
Now we can run this tool against our target. Here we have a demo localhost target, because using this tool without proper permission will be illegal. We can use this against our own site or have a permission to test.
So we run it against our localhost (http://192.168.225.37/bodgeit, we can use live websites URL when we want to run it against live website) using following command:
sudo skipfish -o SkipfishTEST http://192.168.225.37/bodgeitIn the above command we have used -o flag to specify our output directory and SkipFish will generate a folder called SkipfishTEST as per our used command.
After applying the above command we can see some welcome note on our terminal, as the following screenshot:
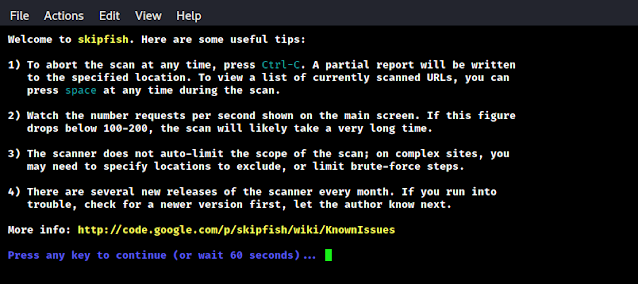
Here we can wait 60 seconds to start our scan or we can press any key to start the scan immediately.
After the scanning process is start we can see SkipFish is trying to find vulnerabilities on our target, as we can see in the following screenshot:
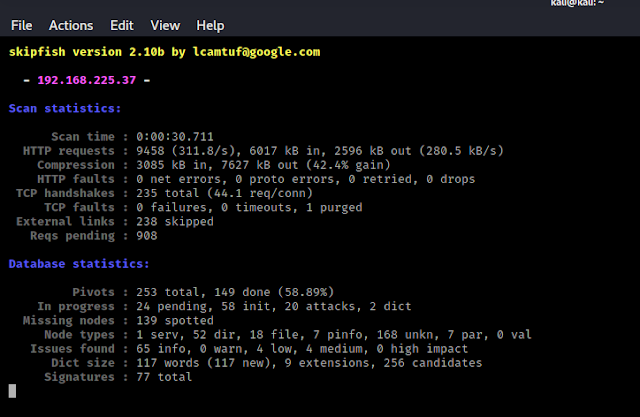
This will take some time to scan depending on the size of our target web application and internet speed (Here we are in localhost so internet speed is not an issue).
If we want to see the details of scanning we can press space bar, then we can see the live scanning:
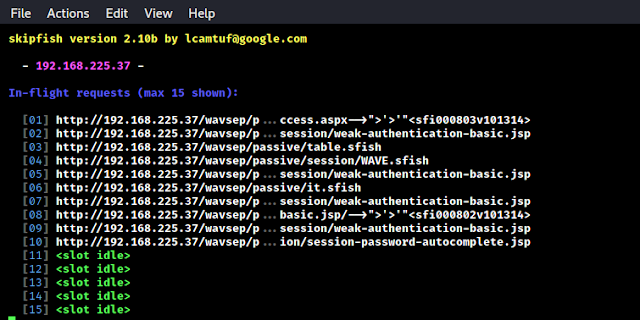
After the scan complete we can see SkipFish generated a ton of output
files in the location specified.
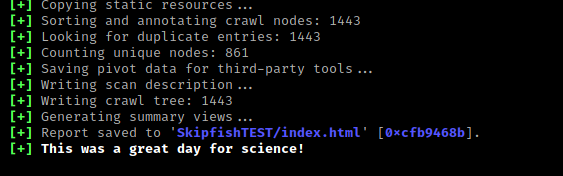
Now we can go to the location where we have saved our reports. In our case it is in SkipfishTEST folder inside the /home/kali directory.
Inside the folder we got a file called index.html we need to open the html file on our browser to get the reports generated by SkipFish. As we did in the following screenshot:
We can see the issues here. To know on which URL we have issues we need to click the issue to expand it.
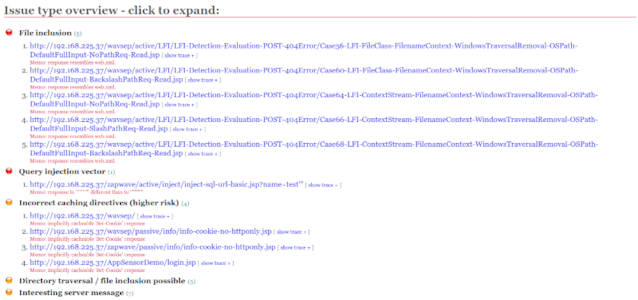
We can see on the above screenshot we have some serious issue to fix. Bad guys can use these loopholes for bad things. But a ethical guy or bounty hunter will report these issues to the admins. To know more specific scans of SkipFish click here.
This is how we can use SkipFish to find security problems on websites or web application using Kali Linux.
Disclaimer: Please do not be evil. Use SkipFish only against services we own, or have a permission to test. Using these against other property may considered as crime. We wrote this article for educational purpose only. If anyone do any disturbing activity then we are not responsible for that, only that person will responsible.
Liked our article? then make sure to follow our e-mail subscription to get our latest article directly on inbox. We also update our article on our GitHub and Twitter, make sure to follow us there. We also have stated a Telegram group for more discussion.
For any kind of problem or query kindly leave a comment on the comment section. We always reply.
Как пользоваться SkipFish на Kali Linux
В этой статье я познакомлю вас с отличным сканером веб-приложений SkipFish от Google.
Что такое SkipFish
Skipfish — это инструмент для поиска уязвимостей веб-приложений. После выполнения рекурсивного сканирования и поиска на основе словаря, создает интерактивную карту целевого сайта. Полученная карта затем аннотируется выводом ряда активных проверок безопасности. Окончательный отчет, созданный инструментом, служит основой для оценки безопасности веб-приложения.
- Высокая производительность при скромном использовании процессора и памяти.
- Хорошо продуманная проверка безопасности сайта.
- Автоматическое построение списка слов на основе анализа контента сайта.
- Связанные проверки безопасности предназначены для обработки сложных сценариев (слепая инъекция SQL или XML и т.д).
- Постобработка отчетов значительно снижает шум, вызванный любыми оставшимися ложными срабатываниями или уловками сервера, путем выявления повторяющихся шаблонов.
Использование SkipFish на Kali Linux
SkipFish по умолчанию установлен в полной версии Kali Linux. Если в вашей версии его нет, тогда установите его через apt:
Для начала открываем справку и изучаем параметры использования:

В качестве цели, вместо IP-адреса сайта, буду сканировать localhost:
В приведенной выше команде был использован параметр — o , который позволяет выбрать каталог для сохранения отчета (в моем случае — SkipfishTEST).
После выполнения команды появится меню, где можно подождать 60 секунд, чтобы начать сканирование, или нажать любую клавишу, для запуска сканирования.

SkipFish начнет поиск уязвимостей. Это займет какое-то время, в зависимости от размера целевого веб-приложения и скорости интернет подключения (в моем случае — это локальный хост, поэтому скорость подключения никак не влияет).

Для получения информации о процессе сканирования, нажмите пробел.
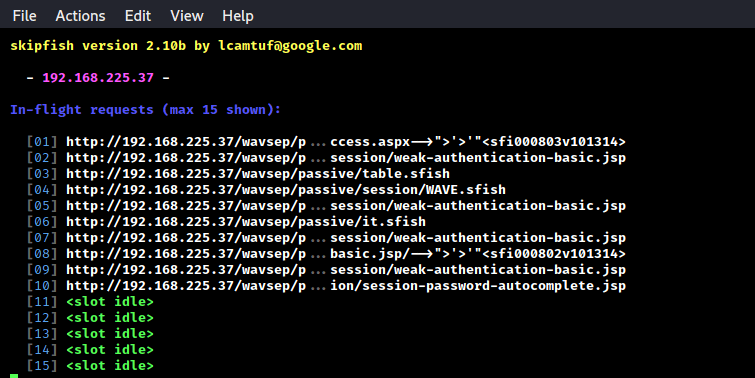
После завершения сканирования, SkipFish создаст отчет.

Для просмотра отчета, откройте в браузере файл index.html.

Для получения информации, кликните по найденной уязвимости.

На приведенном выше скрине видно, что SkipFish нашел уязвимости, среди которых есть и критические.
На этом все. Надеюсь статья помогла в использовании SkipFish на Kali Linux. Дополнительную информацию найдете здесь.
ПОЛЕЗНЫЕ ССЫЛКИ:
Skipfish on kali linux
Learn Latest Tutorials














Preparation




Trending Technologies











B.Tech / MCA























Javatpoint Services
JavaTpoint offers too many high quality services. Mail us on h[email protected], to get more information about given services.
- Website Designing
- Website Development
- Java Development
- PHP Development
- WordPress
- Graphic Designing
- Logo
- Digital Marketing
- On Page and Off Page SEO
- PPC
- Content Development
- Corporate Training
- Classroom and Online Training
- Data Entry
Training For College Campus
JavaTpoint offers college campus training on Core Java, Advance Java, .Net, Android, Hadoop, PHP, Web Technology and Python. Please mail your requirement at [email protected].
Duration: 1 week to 2 week
Like/Subscribe us for latest updates or newsletter 





Tool Documentation:
Using the given directory for output ( -o 202 ), scan the web application URL ( http://192.168.1.202/wordpress ):
[email protected]:~# skipfish -o 202 http://192.168.1.202/wordpress skipfish version 2.10b by [email protected] - 192.168.1.202 - Scan statistics: Scan time : 0:00:05.849 HTTP requests : 2841 (485.6/s), 1601 kB in, 563 kB out (370.2 kB/s) Compression : 802 kB in, 1255 kB out (22.0% gain) HTTP faults : 0 net errors, 0 proto errors, 0 retried, 0 drops TCP handshakes : 46 total (61.8 req/conn) TCP faults : 0 failures, 0 timeouts, 16 purged External links : 512 skipped Reqs pending : 0 Database statistics: Pivots : 13 total, 12 done (92.31%) In progress : 0 pending, 0 init, 0 attacks, 1 dict Missing nodes : 0 spotted Node types : 1 serv, 4 dir, 6 file, 0 pinfo, 0 unkn, 2 par, 0 val Issues found : 10 info, 0 warn, 0 low, 8 medium, 0 high impact Dict size : 20 words (20 new), 1 extensions, 202 candidates Signatures : 77 total [+] Copying static resources. [+] Sorting and annotating crawl nodes: 13 [+] Looking for duplicate entries: 13 [+] Counting unique nodes: 11 [+] Saving pivot data for third-party tools. [+] Writing scan description. [+] Writing crawl tree: 13 [+] Generating summary views. [+] Report saved to '202/index.html' [0x7054c49d]. [+] This was a great day for science! Packages and Binaries:
skipfish
Skipfish is an active web application security reconnaissance tool. It prepares an interactive sitemap for the targeted site by carrying out a recursive crawl and dictionary-based probes. The resulting map is then annotated with the output from a number of active (but hopefully non-disruptive) security checks. The final report generated by the tool is meant to serve as a foundation for professional web application security assessments.
Installed size: 554 KB
How to install: sudo apt install skipfish
skipfish
Web application security scanner
[email protected]:~# skipfish -h skipfish web application scanner - version 2.10b Usage: skipfish [ options . ] -W wordlist -o output_dir start_url [ start_url2 . ] Authentication and access options: -A user:pass - use specified HTTP authentication credentials -F host=IP - pretend that 'host' resolves to 'IP' -C name=val - append a custom cookie to all requests -H name=val - append a custom HTTP header to all requests -b (i|f|p) - use headers consistent with MSIE / Firefox / iPhone -N - do not accept any new cookies --auth-form url - form authentication URL --auth-user user - form authentication user --auth-pass pass - form authentication password --auth-verify-url - URL for in-session detection Crawl scope options: -d max_depth - maximum crawl tree depth (16) -c max_child - maximum children to index per node (512) -x max_desc - maximum descendants to index per branch (8192) -r r_limit - max total number of requests to send (100000000) -p crawl% - node and link crawl probability (100%) -q hex - repeat probabilistic scan with given seed -I string - only follow URLs matching 'string' -X string - exclude URLs matching 'string' -K string - do not fuzz parameters named 'string' -D domain - crawl cross-site links to another domain -B domain - trust, but do not crawl, another domain -Z - do not descend into 5xx locations -O - do not submit any forms -P - do not parse HTML, etc, to find new links Reporting options: -o dir - write output to specified directory (required) -M - log warnings about mixed content / non-SSL passwords -E - log all HTTP/1.0 / HTTP/1.1 caching intent mismatches -U - log all external URLs and e-mails seen -Q - completely suppress duplicate nodes in reports -u - be quiet, disable realtime progress stats -v - enable runtime logging (to stderr) Dictionary management options: -W wordlist - use a specified read-write wordlist (required) -S wordlist - load a supplemental read-only wordlist -L - do not auto-learn new keywords for the site -Y - do not fuzz extensions in directory brute-force -R age - purge words hit more than 'age' scans ago -T name=val - add new form auto-fill rule -G max_guess - maximum number of keyword guesses to keep (256) -z sigfile - load signatures from this file Performance settings: -g max_conn - max simultaneous TCP connections, global (40) -m host_conn - max simultaneous connections, per target IP (10) -f max_fail - max number of consecutive HTTP errors (100) -t req_tmout - total request response timeout (20 s) -w rw_tmout - individual network I/O timeout (10 s) -i idle_tmout - timeout on idle HTTP connections (10 s) -s s_limit - response size limit (400000 B) -e - do not keep binary responses for reporting Other settings: -l max_req - max requests per second (0.000000) -k duration - stop scanning after the given duration h:m:s --config file - load the specified configuration file Send comments and complaints to [email protected]>.