How to append contents of multiple files into one file
and it did not work. I want my script to add the newline at the end of each text file. eg. Files 1.txt, 2.txt, 3.txt. Put contents of 1,2,3 in 0.txt How do I do it ?
12 Answers 12
You need the cat (short for concatenate) command, with shell redirection ( > ) into your output file
@blasto it depends. You would use >> to append one file onto another, where > overwrites the output file with whatever’s directed into it. As for the newline, is there a newline as the first character in file 1.txt ? You can find out by using od -c , and seeing if the first character is a \n .
@blasto You’re definitely heading in the right direction. Bash certainly accepts the form <. >for filename matching, so perhaps the quotes messed things up a bit in your script? I always try working with things like this using ls in a shell. When I get the command right, I just cut-n-paste it into a script as is. You might also find the -x option useful in your scripts — it will echo the expanded commands in the script before execution.
To maybe stop somebody from making the same mistake: cat 1.txt 2.txt > 1.txt will just override 1.txt with the content of 2.txt . It does not merge the two files into the first one.
Another option, for those of you who still stumble upon this post like I did, is to use find -exec :
find . -type f -name '*.txt' -exec cat <> + >> output.file In my case, I needed a more robust option that would look through multiple subdirectories so I chose to use find . Breaking it down:
Look within the current working directory.
Only interested in files, not directories, etc.
Whittle down the result set by name
Execute the cat command for each result. «+» means only 1 instance of cat is spawned (thx @gniourf_gniourf)
As explained in other answers, append the cat-ed contents to the end of an output file.
There are lots of flaws in this answer. First, the wildcard *.txt must be quoted (otherwise, the whole find command, as written, is useless). Another flaw comes from a gross misconception: the command that is executed is not cat >> 0.txt <> , but cat <> . Your command is in fact equivalent to < find . -type f -name *.txt -exec cat '<>‘ \; ; > >> 0.txt (I added grouping so that you realize what’s really happening). Another flaw is that find is going to find the file 0.txt , and cat will complain by saying that input file is output file.
Thanks for the corrections. My case was a little bit different and I hadn’t thought of some of those gotchas as applied to this case.
You should put >> output.file at the end of your command, so that you don’t induce anybody (including yourself) into thinking that find will execute cat <> >> output.file for every found file.
Starting to look really good! One final suggestion: use -exec cat <> + instead of -exec cat <> \; , so that only one instance of cat is spawned with several arguments ( + is specified by POSIX).
Good answer and word of warning — I modified mine to: find . -type f -exec cat <> + >> outputfile.txt and couldn’t figure out why my output file wouldn’t stop growing into the gigs even though the directory was only 50 megs. It was because I kept appending outputfile.txt to itself! So just make sure to name that file correctly or place it in another directory entirely to avoid this.
if you have a certain output type then do something like this
cat /path/to/files/*.txt >> finalout.txt Keep in mind that you are losing the possibility to maintain merge order though. This may affect you if you have your files named, eg. file_1 , file_2 , … file_11 , because of the natural order how files are sorted.
If all your files are named similarly you could simply do:
If all your files are in single directory you can simply do
Files 1.txt,2.txt, .. will go into 0.txt
Already answered by Eswar. Keep in mind that you are losing the possibility to maintain merge order though. This may affect you if you have your files named, eg. file_1 , file_2 , … file_11 , because of the natural order how files are sorted.
for i in ; do cat "$i.txt" >> 0.txt; done I found this page because I needed to join 952 files together into one. I found this to work much better if you have many files. This will do a loop for however many numbers you need and cat each one using >> to append onto the end of 0.txt.
as brought up in the comments:
sed r 1.txt 2.txt 3.txt > merge.txt sed h 1.txt 2.txt 3.txt > merge.txt sed -n p 1.txt 2.txt 3.txt > merge.txt # -n is mandatory here sed wmerge.txt 1.txt 2.txt 3.txt Note that last line write also merge.txt (not wmerge.txt !). You can use w»merge.txt» to avoid confusion with the file name, and -n for silent output.
Of course, you can also shorten the file list with wildcards. For instance, in case of numbered files as in the above examples, you can specify the range with braces in this way:
if your files contain headers and you want remove them in the output file, you can use:
for f in `ls *.txt`; do sed '2,$!d' $f >> 0.out; done All of the (text-) files into one
find . | xargs cat > outfile xargs makes the output-lines of find . the arguments of cat.
find has many options, like -name ‘*.txt’ or -type.
you should check them out if you want to use it in your pipeline
You should explain what your command does. Btw, you should use find with —print0 and xargs with -0 in order to avoid some caveats with special filenames.
If the original file contains non-printable characters, they will be lost when using the cat command. Using ‘cat -v’, the non-printables will be converted to visible character strings, but the output file would still not contain the actual non-printables characters in the original file. With a small number of files, an alternative might be to open the first file in an editor (e.g. vim) that handles non-printing characters. Then maneuver to the bottom of the file and enter «:r second_file_name». That will pull in the second file, including non-printing characters. The same could be done for additional files. When all files have been read in, enter «:w». The end result is that the first file will now contain what it did originally, plus the content of the files that were read in.
Send multi file to a file(textall.txt):
Объединение файлов командой cat
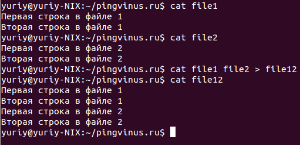
Команду cat в большинстве случаев используют только для просмотра файлов. На самом деле одно из ее предназначений это конкатенация (объединение) файлов. А название команды происходит от слова catenate (сцепить), то есть присоединение одного после другого.
Под объединением файлов понимается их соединение. Например, если мы имеем два текстовых файла и в одном из них записана строка:
My text file 1
А в другом:
My text file 2
То после объединения мы получим файл с двумя строками:
My text file 1
My text file 2
То есть происходит простое соединение файлов. К содержимому одного добавляется содержимое другого. Это касается не только текстовых файлов, но и всех остальных (бинарных, например).
Чтобы объединить два файла командой cat нужно просто указать в качестве аргументов названия этих файлов и направить результат выполнения в новый файл. Например, мы хотим объединить два файла file1 и file2, а результат записать в новый файл file12. Тогда мы должны выполнить следующую команду:
Вы можете объединить неограниченное количество файлов. Например, чтобы объединить четыре файла и записать результат в файл myfile, выполните команду:
cat file1 file2 file3 file4 > myfilejoin multiple files
I am using the standard join command to join two sorted files based on column1. The command is simple join file1 file2 > output_file. But how do I join 3 or more files using the same technique ? join file1 file2 file3 > output_file Above command gave me an empty file. I think sed can help me but I am not too sure how ?
8 Answers 8
NAME join - join lines of two files on a common field SYNOPSIS join [OPTION]. FILE1 FILE2 it only works with two files.
if you need to join three, maybe you can first join the first two, then join the third.
join file1 file2 | join - file3 > output that should join the three files without creating an intermediate temp file. — tells the join command to read the first input stream from stdin
One can join multiple files (N>=2) by constructing a pipeline of join s recursively:
#!/bin/sh # multijoin - join multiple files join_rec() < if [ $# -eq 1 ]; then join - "$1" else f=$1; shift join - "$f" | join_rec "$@" fi >if [ $# -le 2 ]; then join "$@" else f1=$1; f2=$2; shift 2 join "$f1" "$f2" | join_rec "$@" fi Definitely my favourite answer! However, I replaced the join_rec function’s body by this : f1=$1; f2=$2; shift 2; if [ $# -gt 0 ]; then; join «$f1» «$f2» | join_rec — «$@»; else; join «$f1» «$f2»; fi as to eliminate the need for the second if . The call would look like join_rec «$@»
I know this is an old question but for future reference. If you know that the files you want to join have a pattern like in the question here e.g. file1 file2 file3 . fileN Then you can simply join them with this command
Where output will be the series of the joined files which were joined in alphabetical order.
This works superb for text files. How about the binary files which have been split using other commands / packages / software.
well there you have probably some header in every file which indicates, what kind of file is it, so there is this not sufficient, but you should search for other so questions for this, i am sure someone solved it already
I created a function for this. First argument is the output file, rest arguments are the files to be joined.
function multijoin() < out=$1 shift 1 cat $1 | awk '' > $out for f in $*; do join $out $f > tmp; mv tmp $out; done > multijoin output_file file* While a bit an old question, this is how you can do it with a single awk :
awk -v j= ' # get key and delete field j (NR==FNR) # store the key-order # update key-entry END < for(i=1;i<=FNR;++i) < key=order[i]; print key entryСлить два файла linux # print >>' file1 . filen - all files have the same amount of lines
- the order of the output is the same order of the first file.
- files do not need to be sorted in field
- is a valid integer.
The man page of join states that it only works for two files. So you need to create and intermediate file, which you delete afterwards, i.e.:
> join file1 file2 > temp > join temp file3 > output > rm temp Join joins lines of two files on a common field. If you want to join more — do it in pairs. Join first two files first, then join the result with a third file etc.
Assuming you have four files A.txt, B.txt, C.txt and D.txt as:
~$ cat A.txt x1 2 x2 3 x4 5 x5 8 ~$ cat B.txt x1 5 x2 7 x3 4 x4 6 ~$ cat C.txt x2 1 x3 1 x4 1 x5 1 ~$ cat D.txt x1 1 firstOutput='0,1.2'; secondOutput='2.2'; myoutput="$firstOutput,$secondOutput"; outputCount=3; join -a 1 -a 2 -e 0 -o "$myoutput" A.txt B.txt > tmp.tmp; for f in C.txt D.txt; do firstOutput="$firstOutput,1.$outputCount"; myoutput="$firstOutput,$secondOutput"; join -a 1 -a 2 -e 0 -o "$myoutput" tmp.tmp $f > tempf; mv tempf tmp.tmp; outputCount=$(($outputCount+1)); done; mv tmp.tmp files_join.txt ~$ cat files_join.txt x1 2 5 0 1 x2 3 7 1 0 x3 0 4 1 0 x4 5 6 1 0 x5 8 0 1 0