Как собрать ядро linux под arm
Операционная система linux часто используется для встраиваемых (они же embedded) устройств, которые в свою очередь часто построены на основе контроллеров с архитектурой ARM.
Исходный код
Скачать исходный код ядра linux можно с http://git.kernel.org Например, если использовать код из проекта project: После того как исходники будут скачаны, заходим в директорию с исходным кодом ядра linux. Для того что бы отделить результат компиляции от исходного кода, создаем директорию build
Компилятор
Распаковываем ( например в /home/user ): И устанавливаем переменную PATH: Задаем переменные окружения для компиляции:
Конфигурирование ядра linux
Если нужная конфигурация уже существует ( например arch/arm/configs/colibri_pxa320_defconfig ), то выполняем: Если необходимо создать свою конфигурацию ядра linux, или изменить существующую то запускаем: и выбираем необходимые опции. Опции могут быть вкомпилированны в ядро или подгружаться как модули. В первом случае перед соответствующим пунктом меню отображается [*] , во втором [M].
Компиляция ядра linux
Сброка модулей ядра linux
Если какие-то опции ядра были включены как модули, то их тоже надо скомпилировать Что бы изменить директорию (папку) в которую modules_install установит модули, указываем путь, используя переменную INSTALL_MOD_PATH. В дальнейшем, что бы положить модули ядра на устройство, надо просто скопировать, все что лежит в директории /home/user/tmp/modules в корень файловой системы устройства. При этом важно сохранить структуру каталогов, самый просто способ — упаковать папку, а затем разархивировать ее на приборе.
Очистка проекта
Что бы удалить все файлы, созданные при компиляции: Если же необходимо удалить файлы, полученные при конфигурации ядра linux, нам поможет Мистер Пропер 🙂 Источник
Linux для ARM в эмуляторе qemu
Вывести что-нибудь на экран эмулируемого устройства VersatilePB не так-то просто. Все примеры простых ядер для ARM, которые удалось найти на момент написания статьи, ограничиваются работой с последовательным портом. Этот пост — начало серии, рассказывающей о том, как собиралось простое ядро для вывода на экран эмулируемого устройства. На примере 2-х с небольшим тысяч строк кода будет подробно рассказано об инициализации памяти, зонах памяти, slab-аллокаторе применяемых в Linux.
Сборка ядра для архитектуры ARM (на примере linux-2.6.32.3)
Команды, приводимые далее взяты из файлов *.cmd. Эти файлы формируются автоматически системой сборки ядра, но никто не запрещает использовать команды непосредственно. Ядро запускаемое в qemu ./arch/arm/boot/zImage получается отсечением ненужных секций от скомпилированного кода распаковки: Этот код собирается из библиотеки(libgcc.a), файла содержащего точку входа (head.o), файла в который включены двоичные данные упакованного ядра (piggy.o) и кода на Си выполняющего распаковку (misc.o):
Упакованное ядро добавляется в piggy.S строкой: piggy.o компилируется командой: Файл piggy.gz получается командой: Обратите внимание на две точки между директориями compressed и Image. Они означают переход на один уровень вверх в дереве файловой системы, т.е. Image расположен в arch/arm/boot/.
Такие сложности обусловлены автоматической генерацией команд сборки. Image получается отсечением ненужных секций от скомпилированного ядра.: Не упакованое ядро (vmlinux) получается так: И наконец файл main.c, который мы будем рассматривать входит в состав init/built-in.o:
После окончания работы по отделению необходимого кода от дерева исходников ядра получилась следующая последовательность команд, позволяющая собрать минимальное ядро, способное выводить информацию на дисплей эмулятора архитектуры ARM: user/arm-2011.09/bin/ — путь начинающийся от домашнего каталога автора до директории, содержащий тулчейн. Если вы скопируете тулчейн для ARM в свой домашний каталог и измените «user», на имя пользователя, то у Вас всё должно получиться. Команды объединены в исполняемый файл make (не путайте с одноименной утилитой). Код непосредственно после отделения от дерева исходников ядра, включая всё, о чем пойдет речь в следующих постах arm_qemu_max. Сокращенный вариант, без инициализации памяти и slab-аллокатора (только вывод на экран) arm_qemu_min. Текст остальных статей написан. Остается только опубликовать. Источник
Кросскомпиляция под ARM
Кому это интересно, прошу под кат.
Вводная
Одно из развивающихся направлений в современном IT это IoT. Развивается это направление достаточно быстро, всё время выходят всякие крутые штуки (типа кроссовок со встроенным трекером или кроссовки, которые могут указывать направление, куда идти (специально для слепых людей)). Основная масса этих устройств представляют собой что-то типа «блютуз лампочки», но оставшаяся часть являет собой сложные процессорные системы, которые собирают данные и управляют этим огромным разнообразием всяких умных штучек. Эти сложные системы, как правило, представляют собой одноплатные компьютеры, такие как Raspberry Pi, Odroid, Orange Pi и т.п. На них запускается Linux и пишется прикладной софт. В основном, используют скриптовые языки и Java. Но бывают приложения, когда необходима высокая производительность, и здесь, естественно, требуются C и C++. К примеру, может потребоваться добавить что-то специфичное в ядро или, как можно быстрее, высчитать БПФ. Вот тут-то и нужна кросскомпиляция.
Если проект не очень большой, то его можно собирать и отлаживать прямо на целевой платформе. А если проект достаточно велик, то компиляция на целевой платформе будет затруднительна из-за временных издержек. К примеру, попробуйте собрать Boost на Raspberry Pi. Думаю, ожидание сборки будет продолжительным, а если ещё и ошибки какие всплывут, то это может занять ох как много времени.
Поэтому лучше собирать на хосте. В моём случае, это i5 с 4ГБ ОЗУ, Fedora 24.
Инструменты
Для кросскомпиляции под ARM требуются toolchain и эмулятор платформы либо реальная целевая платформа.
Т.к. меня интересует компиляция для ARM, то использоваться будет и соответствующий toolchain.
Toolchain’ы делятся на несколько типов или триплетов. Триплет обычно состоит из трёх частей: целевой процессор, vendor и OS, vendor зачастую опускается.
- *-none-eabi — это toolchain для компиляции проекта работающего в bare metal.
- *eabi — это toolchain для компиляции проекта работающего в какой-либо ОС. В моём случае, это Linux.
- *eabihf — это почти то же самое, что и eabi, с разницей в реализации ABI вызова функций с плавающей точкой. hf — расшифровывается как hard float.
Описанное выше справедливо для gcc и сделанных на его базе toolchain’ах.
Сперва я пытался использовать toolchain’ы, которые лежат в репах Fedora 24. Но был неприятно удивлён этим:
Поискав, наткнулся на toolchain от компании Linaro. И он меня вполне устроил.
Второй инструмент- это QEMU. Я буду использовать его, т.к. мой Odroid-C1+ пал смертью храбрых (нагнулся контроллер SD карты). Но я таки успел с ним чуток поработать, что не может не радовать.
Элементарная технология кросскомпиляции
Собственно, ничего необычного в этом нет. Просто используется toolchain в роли компилятора. А стандартные библиотеки поставляются вместе с toolchain’ом.
Какие ключи у toolchain’а можно посмотреть на сайте gnu, в соответствующем разделе.
Для начала нужно запустить эмуляцию с интересующей платформой. Я решил съэмулировать Cortex-A9.
После нескольких неудачных попыток наткнулся на этот how2, который оказался вполне вменяемым, на мой взгляд.
Ну сперва, само собою, нужно заиметь QEMU. Установил я его из стандартных репов Fedor’ы.
Далее создаём образ жёсткого диска, на который будет установлен Debian.
По этой ссылке скачал vmlinuz и initrd и запустил их в эмуляции.
Далее просто устанавливаем Debian на наш образ жёсткого диска (у меня ушло
После установки нужно вынуть из образа жёсткого диска vmlinuz и initrd. Делал я это по описанию отсюда.
Сперва узнаём смещение, где расположен раздел с нужными нам файлами:
Теперь по этому смещению примонтируем нужный нам раздел.
Копируем файлы vmlinuz и initrd и размонтируем жёсткий диск.
Теперь можно запустить эмуляцию.
И вот заветное приглашение:
Теперь с хоста по SSH можно подцепиться к симуляции.
Теперь можно и собрать программку. По Makefile’у ясно, что будет калькулятор. Простенький.
Собираем на хосте исполняемый файл.
Отмечу, что проще собрать с ключом -static, если нет особого желания предаваться плотским утехам с библиотеками на целевой платформе.
Копируем исполняемый файл на таргет и проверяем.
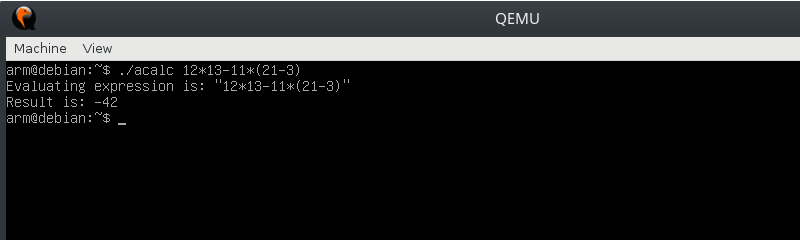
Собственно, вот такая она, эта кросскомпиляция.
UPD: Подправил информацию по toolchain’ам по комментарию grossws.