Speech to Text Software for Linux
Compare the Top Speech to Text Software for Linux of 2023
What is Speech to Text Software for Linux?
Speech to text software enables users to convert human speech into text. Speech to text software, sometimes known as dictation software, can be used on desktop machines, or speech to text apps can be used on a smartphone. Speech to text software and apps can be standalone products, or built into existing applications. Compare the best Speech to Text software for Linux currently available using the table below.
LumenVox
Transforming customer engagement with AI-driven speech recognition and voice authentication technology. We’ve spent the last 20 years empowering our partners’ success through collaboration. Our curiosity keeps us innovating for the next 20. Our flexible speech-enabling technology enables you to build a solution that fulfills all your customers’ demands, affordably and reliably. We do one thing, and we do it well. And that’s speech-enabling your applications. Finally, deliver great voice automation and interactions. Whether short and simple commands, or conversational questions, LumenVox ASR and TTS is accurate and affordable, helping you improve efficiencies on both sides of the phone line. You’ll never repeat yourself again. We provide you with the utmost flexibility from a capabilities, deployment and monetization perspective. If you can think it, you can build it with LumenVox. Shorten your development to deployment time with our easy, intuitive technology and toolsets.
AIWriter
Introducing AIWriter, the ultimate solution for all your content creation needs. With our advanced AI technology, including GPT-3 and GPT-4 language models, you can create high-quality content in multiple languages with ease. Our platform offers a variety of features, including AI Text Generation, AI Image Generation, AI Coding Generation, and Speech to Text. Choose from a range of specialized bots or use our templates to generate articles, blogs, ads, and more. With different content creation templates available, you’ll never run out of ideas. Our AI-generated topic suggestions and outlines will provide you with endless inspiration, making content creation a breeze. With our Stable Diffusion Solution, you can generate unique images simply by describing them in words. Our AI code generator enables developers to generate code faster and with greater accuracy than ever before. Not only does AIWriter make content creation easier, but it also offers a referral system to earn passive
AssemblyAI
Automatically convert audio and video files and live audio streams to text with AssemblyAI’s speech-to-text APIs. Do more with audio intelligence, summarization, content moderation, topic detection, and more. Powered by cutting-edge AI models. From in-depth tutorials to detailed changelogs, to comprehensive documentation, AssemblyAI is focused on providing developers a great experience every step of the way. From core speech-to-text conversion to sentiment analysis, our simple API offers a full suite of solutions catered to all your business speech-to-text needs. We work with startups of all sizes, from early-stage startups to scale-ups, by providing cost-efficient speech-to-text solutions. We’re built for scale. We process millions of audio files every day for hundreds of customers, including dozens of Fortune 500 enterprises. We provide comprehensive support to developers through our in-depth tutorials, detailed documentation, and changelog.
TTS движки для Ubuntu Linux (Text-to-Speak)

Голосовой движок (озвучивание русского текста) может использоваться для разных задач, например можно слушать книги без их предварительной озвучки, прослушивать входящие тестовые сообщения, да и в общем, можно вести любой диалог с компьютером посредством голосового взаимодействия, на базе чего строить разные сервисы и умные системы.
Я расцениваю TTS движки только в качестве одной из компонент для реализации системы «Умного дома». Книги на русском они читают терпимо-ужасно, озвучивать сообщения и прочие обрывки информации мне не нужно. Мне нужен TTS для решения единственной задачи — обратная связь с системой умного дома.
Ниже я приведу список существующих TTS движков и субъективную оценку качества озвучки русского текста.
Демо примеры озвучки
- Festival;
- Nuance Loquendo (Demo ) — голос Olga лучший на текущий момент, но штука платная;
- RHVoice (Demo, Установка RHVoice );
- Open Mary (Demo ) — ниже среднего;
- Espeak (Demo) — с русским все очень плохо;
- Платные движки (Demo );
- Acapela (Demo ) — голос Alena, качество не особо;
RHVoice
Довольно хороший TTS движок от Ольги Яковлевой (Github ).
Пример консольной команды:
echo "Напоминаю.. Пора работать!" | RHVoice-test --profile "Elena" -v 100 --pitch 100 --rate 90 --sample-rate 360 ESpeak
# установка apt-get install espeak # озвучить espeak -vru -s130 "Русский синтезатор речи" # vru - русский, ven - английский # сохранить озвучку в файл espeak -vru -s130 -w espeak.wav "Я хреново говорю по-русски.." FestVox
Это ще один TTS. Поддерживает русский текст. Голосовой пакет весит 196MB. Виндовые бинарники тут .
sudo apt-get install festvox-ruНа многих форумах рекомендуют править конфиг ~/.festivalrc , зачем не знаю:
(Parameter.set 'Audio_Command "aplay -q -c 1 -t raw -f s16 -r $SR $FILE") (Parameter.set 'Audio_Method 'Audio_Command)echo "Я умею озвучивать русский текст!" | festival --tts --language russian # озвучить текст из файла >> festival --tts --language russian from_file.txt cat text.txt | festival --tts --language russian text2wave -eval '(voice_msu_ru_nsh_clunits)' ~/text.txt -o ~/festival_example_ru.wavСсылки
Сообщения
#!/bin/sh HOURS=»`date +%I`» h=$HOURS MINUTE=»`date +%M`» DISPLAY=:0.0 notify-send -i «typing-monitor» «Текущее время» «$HOURS:$MINUTE» while [ $h != 0 ] do aplay -q ~/ku-ku.wav h=`expr $h — 1` sleep 1 done h=$(($HOURS % 100)) h1=$(($h % 10)) if [ $h -gt 10 -a $h -lt 20 ]; then HOURS_SAY=’час+ов’; elif [ $h1 -gt 1 -a $h1 -lt 5 ]; then HOURS_SAY=’час+а’; elif [ $h1 -eq 1 ]; then HOURS_SAY=’час’; else HOURS_SAY=’час+ов’; fi m=$(($MINUTE % 100)) m1=$(($m % 10)) if [ $m -gt 10 -a $m -lt 20 ]; then MINUTE_SAY=’мин+ут’; elif [ $m1 -gt 1 -a $m1 -lt 5 ]; then MINUTE_SAY=’мин+уты’; elif [ $m1 -eq 1 ]; then MINUTE_SAY=’мин+ута’; else MINUTE_SAY=’мин+ут’; fi if [ $MINUTE -eq 00 ]; then MINUTE_SAY=’р+овно’; fi echo «тек+ущее вр+емя: $HOURS $HOURS_SAY, $MINUTE $MINUTE_SAY» | /usr/bin/festival —tts —language russian октября 2017
Транскрибация в Linux + lifehack
Нет, это не ругательное слово (для тех, кто не в курсе). Транскрибация это перевод голоса в текст.
На протяжении нескольких лет я подрабатывал этим делом. Титры для видео (использовал subtitle editor), интервью, доклады, проповеди и т. п. По заказам речь переводил в текст.
Долго пытался автоматизировать этот процесс. Сейчас существует много сервисов, которые могли бы в этом помочь. Но, как выяснилось, в реальной работе эти сервисы не могут быть полезны. На записях шум, необычный выговор докладчика, качество самой записи не позволяли применить методы автоматического распознавания голоса и перевода речи в текст.
Тем не менее существенно облегчить труд может творческое отношение к процессу.
Во время транскрибации можно использовать любой аудио проигрыватель, который управляется с клавиатуры и показывает тайминг.
При записи текста обычно требуется указывать этот самый тайминг.
Если текст большой, хотелось бы иметь некоторую форму для записи этого текста, в которой тайминги уже указаны с некоторым периодом.
Это существенно помогает ориентироваться в тексте и в аудио записи.
При необходимости по тексту легко определить место в записи, чтобы перейти к нему для уточнения.
Обычно работа по транскрибации оплачивается по времени записи. Было бы удобно сразу после завершения работы видеть и сумму, которую вам должен будет заплатить заказчик.
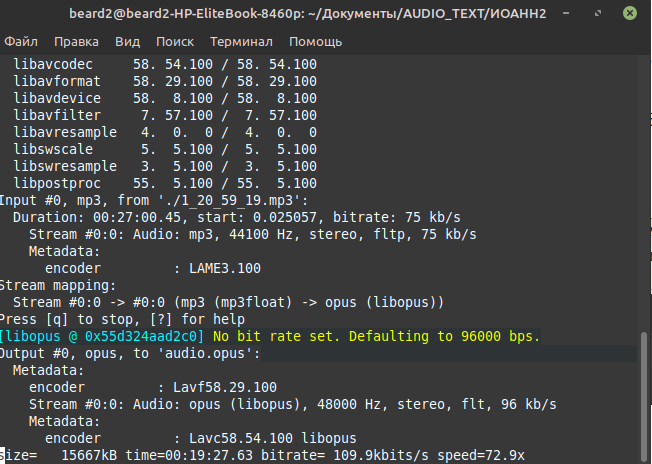
Оказалось, что в Linux есть простое средство позволяющее создать небольшой скрипт, который может просмотреть аудио файл, определить его продолжительность и создать текстовый файл с указанием интервалов по 15 секунд. В конце файла может быть указана цена работы.
Это средство обыкновенный терминал и bash (Одна из наиболее популярных современных разновидностей командной оболочки UNIX).
Я далеко не программист. Но мне потребовалось всего пара дней для создания такого файла. А теперь, когда я уже давно не занимаюсь транскрибацией регулярно, мне пришёл случайный заказ. Достав из закромов свой файл скрипта, я оперативно этот заказ исполнил.
0:15:30 !
Дадим же Богу возможность в нашей жизни действовать. Действовать через нас, через нашу жизнь, через наши слова, через наши поступки.
0:15:45 !
Сделаемся и мы его орудием для того чтобы ещё хоть кого-то обратить к Богу. Во всём этом пусть каждому из нас Господь поможет
0:16:00 !
и укрепит в наших желаниях. Аминь.
0:16:15 !
— — —
=282.75 ₽.
Скрипт определяет стоимость работы исходя из расценки 17 р/мин. Эта цена настраивается в строке 65 указанием цены за 15 секунд.
#!/bin/bash ##Создание формы для транскрибации ## 15 р / мин 0,216666667 р/ сек. # # echo "Запускается перетаскиванием исполняемого файла и акдиофайла в окно терминала, открытого в рабочем каталоге." echo "Из исходного видео или аудио извлекает фрагменты в формата opus по 15 сек." echo "и записывает пустые строки [имя аудио].txt" echo "Временные файлы удаляются автоматически" F_NAME_FULL1=$1 echo $F_NAME_FULL1 ##sleep 5 EXT=$ BNAME=`basename "$F_NAME_FULL1" ".$EXT"` F_NAME_FULL="./"$BNAME"."$EXT echo $BNAME ##sleep 2 TIME_R=15 ###################################### ## Преобразование входного файла в формат OPUS для расшифровки ffmpeg -i $F_NAME_FULL -vn -c:a libopus audio.opus && ffmpeg -i ./audio.opus -f segment -segment_time $TIME_R -acodec copy "%03d.ogg" ##sleep 1 rm ./audio.opus ## Проверка наличия файла для расшифровки RASH=".ogg" NNN=0 FILE1=$F_NAME_PREF$(printf '%03d' $NNN)$RASH echo $FILE1 while [ -f "$FILE1" ] do ## echo $FILE1 echo "Есть" ## Распознавание ################################ PREF="@" FILE2=$PREF$FILE1 echo $FILE2 (echo "X")>>./text_1.txt ## Контролируем процесс ################################ rm $FILE1 NNN=$[1+$NNN] ## Добавляем пустую строку с номером минуты. TIMING=$(($NNN*$TIME_R)) ## расходы ############################################ MON1=$(bc > ./text_1.txt ########################################### FILE1=$F_NAME_PREF$(printf '%03d' $NNN)$RASH ## sleep 1 done echo " - - - ">>./text_1.txt echo $ " ₽. ">>./text_1.txt echo " 0:00:00 !">'./'$BNAME'.txt' echo -e «\n+++» | cat ./text_1.txt>>'./'$BNAME'.txt' ##echo | cat ./text_1.txt>>'./'$BNAME'.txt' clear ################################ rm ./text_1.txt ## mm.ss TIME_CODE="0:00:00" TIME_CODE_str=$"("$TIME_CODE$")" Имя файла любое допустимое, например write-speech-form.
Достаточно открыть окно терминала из каталога где лежит аудио файл и скрипт, перетащить мышью файл скрипта и аудио файл в окно терминала, нажать . Имя аудио файла не должно содержать пробелов и лишних точек, должны быть установлены права на выполнение. Я именую обычно датой или временем 20_59_19.mp3.
Через несколько секунд в каталоге появится текстовая форма разграфка с ценой работы.
При необходимости автоматически проставленные тайминги можно удалить или заменить на более редкие.
В процессе работы скрипт разбирает исходный файл на фрагменты. Это можно использовать для анализа фрагментов и решении других задач автоматизации. Раньше мной это использовалось для отправки фрагментов Яндексу для дешифровки.