Image or reset broken SSD
Pretty much everything on there is backed up, but I would like to create an image just to be on the save side. dd seems to only see the 8MB drive:
dd if=/dev/sda of=/home/ubuntu/data/sda.img conv=sync,noerror bs=64K count=160G 128+0 records in 128+0 records out 8388608 bytes (8,4 MB) copied, 0,20943 s, 40,1 MB/s How can I create an image of the full 160G drive and how do I fix the drive to use it again? PS: I have read all sorts of Wikis etc. (https://help.ubuntu.com/community/DataRecovery) but none of them seems to deal with the kind of issue I have here.
3 Answers 3
There was a bug in some intel SSD’s firmware which caused this problem. This bug was corrected a while ago but you likely didn’t upgraded the firmware to the newer one.
Read about the bug and the new firmware here https://communities.intel.com/thread/24205
Unfortunately your data cannot be recovered, but your drive could be made usable again:
What should I do if I have already experienced this issue?
If you have already experienced a drive failure or encounter this problem before the firmware update was released, please contact your Intel representative or Intel customer support (via web: www.intel.com or phone: www.intel.com/p/en_US/support/contact/phone) for an SSD replacement. An alternative option is to use the Intel ® SSD Toolbox or similar tools to perform a secure erase in order to restore the SSD to an operational state; all data will be erased. After secure erase, update your SSD with the new firmware. The firmware update will not recover user data.
To solve this using linux: (Source and this)
- Boot up a live environment
- sudo apt-get install hdparm
- sudo hdparm -I /dev/sdX where sdX is your SSD device. This command will just print out some info about the drive. If you see in the output this: Serial Number: BAD_CTX 00000150 that confirms that you are hit by this bug. If at the Seucrity section it reads frozen you can’t continue, you have to use a workaround to eliminate the freeze:
If the command output shows «frozen» one cannot continue to the next step. Some BIOSes block the ATA Secure Erase command by issuing a «SECURITY FREEZE» command to «freeze» the drive before booting an operating system. A possible solution is to simply suspend the system. Upon waking up, it is likely that the freeze will be lifts. If unsuccessful, one can try hot-(re)plug the data cable (which might crash the kernel). If hot-(re)plugging the SATA data cable crashes the kernel try letting the operating system fully boot up, then quickly hot-(re)plug both the SATA power and data cables.
Security: Master password revision code = 65534 supported enabled not locked not frozen not expired: security count supported: enhanced erase Security level high 2min for SECURITY ERASE UNIT. 2min for ENHANCED SECURITY ERASE UNIT. Восстанавливаем SSD под Ubuntu Linux
На сайте как то появлялась статья о том, как оптимизировать работу Ubuntu Linux на SSD жёстких дисках. Но случиться может всякое, да и SSD довольно часто выходят из строя, поэтому и публикуется эта статья. Ниже вы узнаете как восстановить SSD в случае поломки.
Мне подумалось, что вдруг кого-то из владельцев SSD устройства этот топик наведёт на мысль о backup’е, кого-то о в целом более осторожном отношении, а кого-то избавит от общения с не слишком торопливой службой поддержки. Всё написанное относится не тдоолько к устройствам той серии и производителя, что у меня.
Дней 10 назад мне случилось оставить на ночь ноут с батареей в критическом состоянии без зарядки. Я не слишком беспокоюсь о жизни батареи, но удар последовал с другой стороны. Утром, включив ноутбук в зарядку и включив его я с удивлением обнаружил, что:
В ВIOS’е винчестер определялся. Схватив имевшийся под рукой Ubuntu Live CD на flash’ке и вооружившись командной строкой, я приготовился к дебагу.
Стоит сразу сказать, что в случаях таких сбоев удобнее было бы использоваться какой-нибудь Data Rescue Live CD, с уже установленными утилитами диагностики вместо совершенно не нужного офисного пакета, но тем не менее.
Наберём арсенал, который нам пргодится:
Смотрим, что у нас случилось:
Итак, с таблицей разделов вроде бы можно попрощаться.
Ошибка ввода-вывода? Диск не поддерживает SMART? Уже бред какой-то.
Ага. Можно заметить, что число условных SSD цилиндров упало в 10000 раз и согласно десктопному Gparted’у размер винчестера составляет 8MB (каюсь, в логах не сохранилась консольная команда и её вывод для просмотра этого безобразия, прошу верить мне на слово). Серийный номер отсутствует и вместо него BAD_CTX что-то там. Хорошо, симптомы поняли, можно обращаться к поиску и в поддержку. Действительно, оказывается, проблема далеко не единична, но, увы, такой идиот с Linux’ом я один.
В кратце для не знакомых с языком и ленивых, форумчане говорят о повальной подверженности всех Intel’овских SSD такому багу, особенно затронувшее 320ю серию и X25M. Есть новость о прошивке 0362, которая призвана избавить именно от этого бага, но количество обращений людей с уже этой прошивкой с теми же симптомами говорит о нерешённости проблемы. Да, лучшим решением в данном случае было бы отправить винчестер обратно в Intel, чтобы у них появился стимул поправить свои ошибки.
К сожалению, поддержка Intel не отличается расторопностью, и отвечает примерно раз в сутки, затупливая по техническим вопросам, и очень рекомендуя установить их SSD Toolbox для определения проблемы. Хочется отдельно заметить, что основной срез пользователей SSD — это владельцы MacBook’ов, у которых аналогично со мной есть трудности с установкой софта под Windows. Отдельного упоминания достойно то, что эта тулза, предназначенная для определения неисправностей, требует:
Что делает её установку на компьютере, загруженном с Live CD практически невозможной задачей (во-первых из за ограничений объёма на виртуальном винчестере, а во-вторых в связи с тем, что WMP 11 требует проверки аутентичности Windows, которая со скрипом и стонами лишь у некоторых особо выдающихся личностей получается в Wine. Пламенный привет разработчикам этого ПО.
Мне чудом удалось объснить ситуацию поддержке, и они согласились на замену, но для замены нужно заполнить неимоверное количество форм, к которым нужно ещё приложить подтверждение поупки мной устройства. Волею судеб, я сейчас в десяти тысячах километров от дома, и не ждал такого подвоха.
К счастью, на форумах все однозначно говорят, что содержимое диска восстановлению не подлежит, но что работоспособность восстановить возможно. И то время, которое было потрачено на переписку со службой поддержки, я не потратил зря, а с пользой потратил на чтение форумов и эксперименты, краткий разультат которых здесь и привожу.
Нужно восстановить количество цилиндров, вернув заветные 16383. Для этой операции нам нужны будут две команды, запуск обоих затруднён для защиты от дурака и вредителя.
Выставляем пользователя, и пароль для мастер-операций над диском.
Реанимация NVMe диска в Linux — 3

Я уже писал о реанимации отвалившихся дисков NVMe. В первом случае у меня рассыпался namespace:
Вот втором случае namespace остался целым, но диск выпал из устройств PCI:
Сегодня у нас очень похожий случай, NVMe диск выпал из устройств PCI, из mdadm массива, соответственно тоже. Если раньше реанимация проводилась на RAID1 массивах, то сегодня пострадал RAID10. Возможно, именно из-за этого процедура восстановления оказалась чуть сложнее.
Итак, тестовый стенд представляет собой сервер с операционной системой Oracle Linux. В сервере четыре NVME диска Samsung, которые объединены в зеркальный программный RAID10 массив.
Помимо этого в сервере есть ещё два NVME диска Samsung, которые объединены в зеркальный программный RAID1 массив.
Один из NVMe дисков в RAID10 массиве на сервере перестал работать. Массив, собранный с помощью mdadm, перешёл в состояние degraded. Сработал мониторинг, начинаем разбираться в ситуации. Сервер перезагружать нельзя, будем чинить прямо так.
Посмотрим состояние массивов:
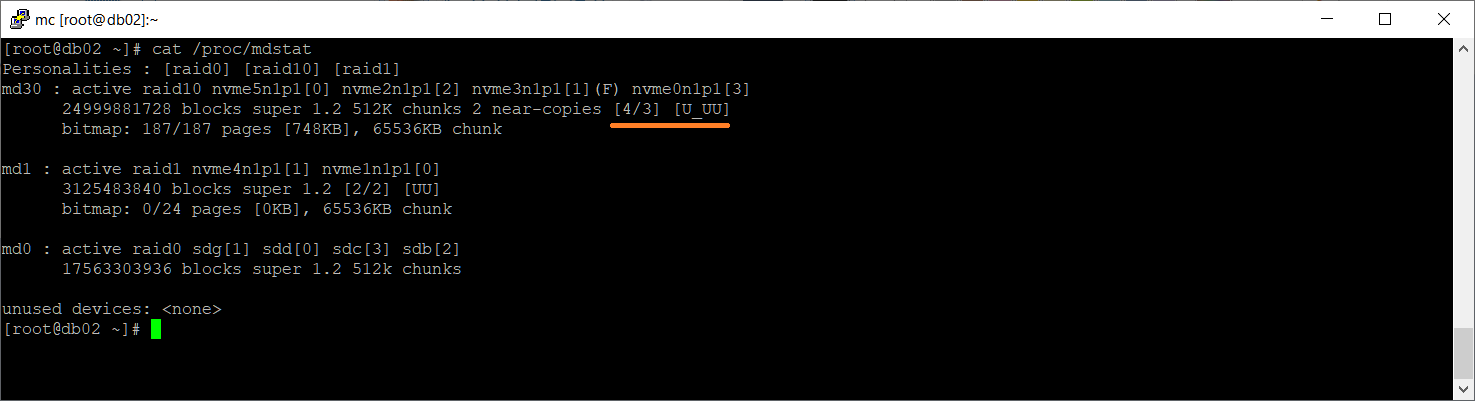
В массиве md30 работают три из четырёх дисков: [U_UU]. В качестве дисков массиву переданы четыре раздела:
По значку (F) видно, что /dev/nvme3n1p1 — faulty. Посмотрим подробности:
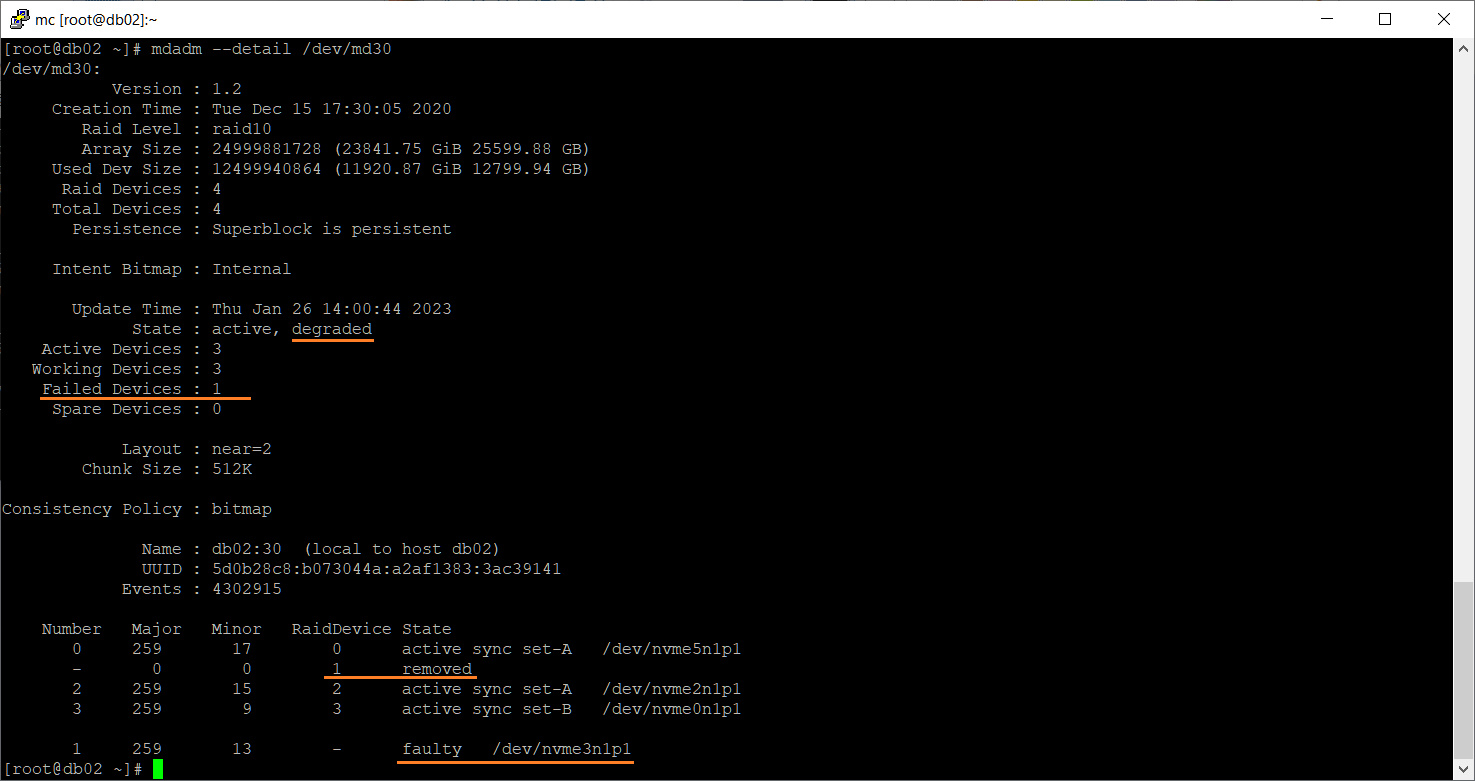
А диск-то у нас из массива не удалился на этот раз. Он числится в массиве и помечен как сбойный.
Посмотреть информацию об NVMe дисках можно с помощью утилиты nvme из пакета nvme-cli:
yum install nvme-cli или apt install nvme-cli nvme list
Однако, утилита не смогла обнаружить диск /dev/nvme3n1. Видим пять устройств, а должно быть шесть. Можно посмотреть, определяется ли диск как PCI устройство командой lspci.
lspci | grep -E "NVMe|Non-Volatile"Диски бывают разные, у меня Samsung, можно и по-другому вычислить:
04:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 41:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 44:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 47:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 84:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824 87:00.0 Non-Volatile memory controller: Samsung Electronics Co Ltd Device a824
В списке присутствуют все шесть NVMe дисков из обоих RAID массивов. Нам нужно определить адрес сбойного диска.
cd /sys/bus/pci/drivers/nvme/ ll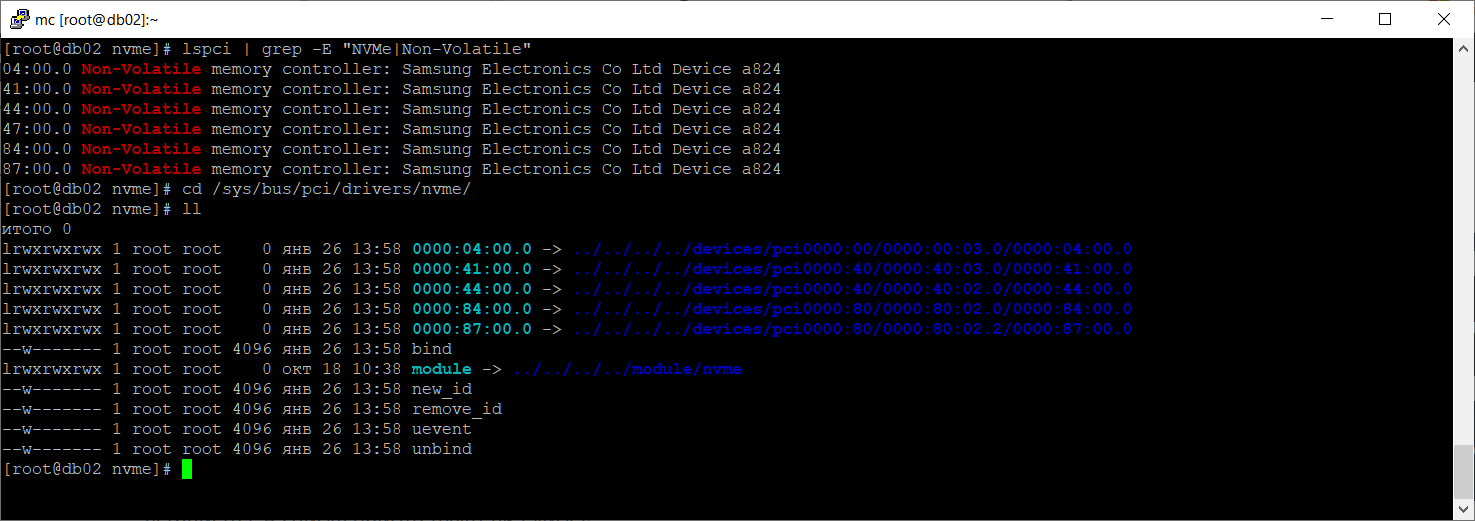
Драйвер устройства 0000:47:00.0 отсутствует, остальные есть. Удаляем отсутствующий диск из списка устройств и заново сканируем PCI.
echo 1 > /sys/bus/pci/devices/0000\:47\:00.0/remove echo 1 > /sys/bus/pci/rescanЗдесь самое важное, не удалить что-нибудь не то. Если ошибиться с диском, то можно потерять данные.
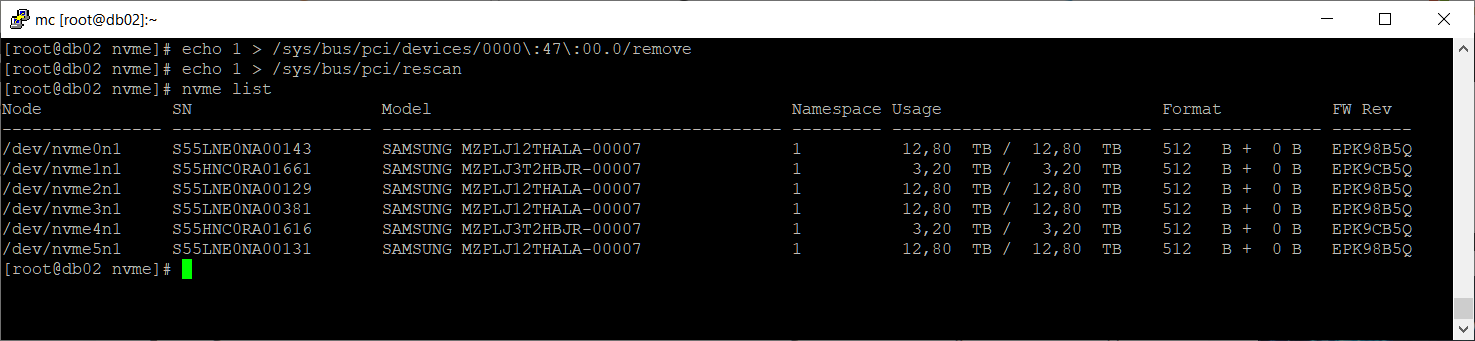
Диск /dev/nvme3n1 появился. Проверим ошибки:
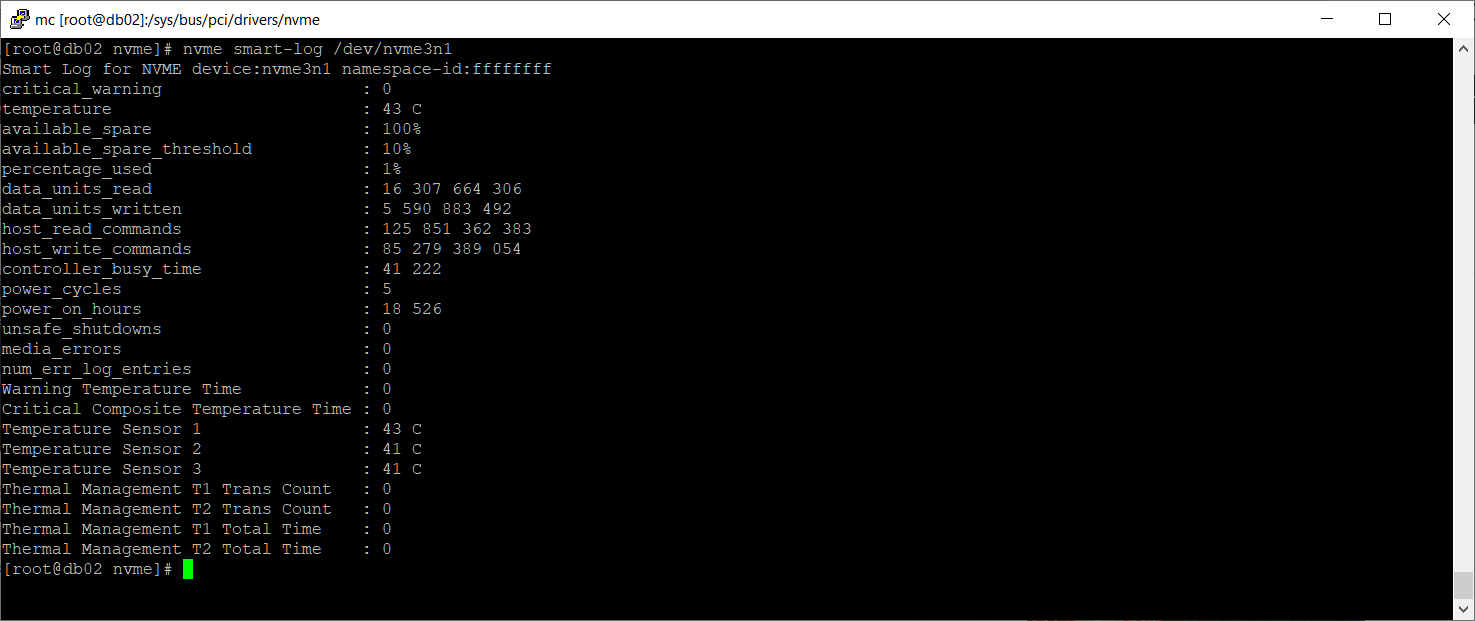
Странно, ошибок нет. Вероятно, сбой произошёл не по причине неисправности диска. Проверим namespace:
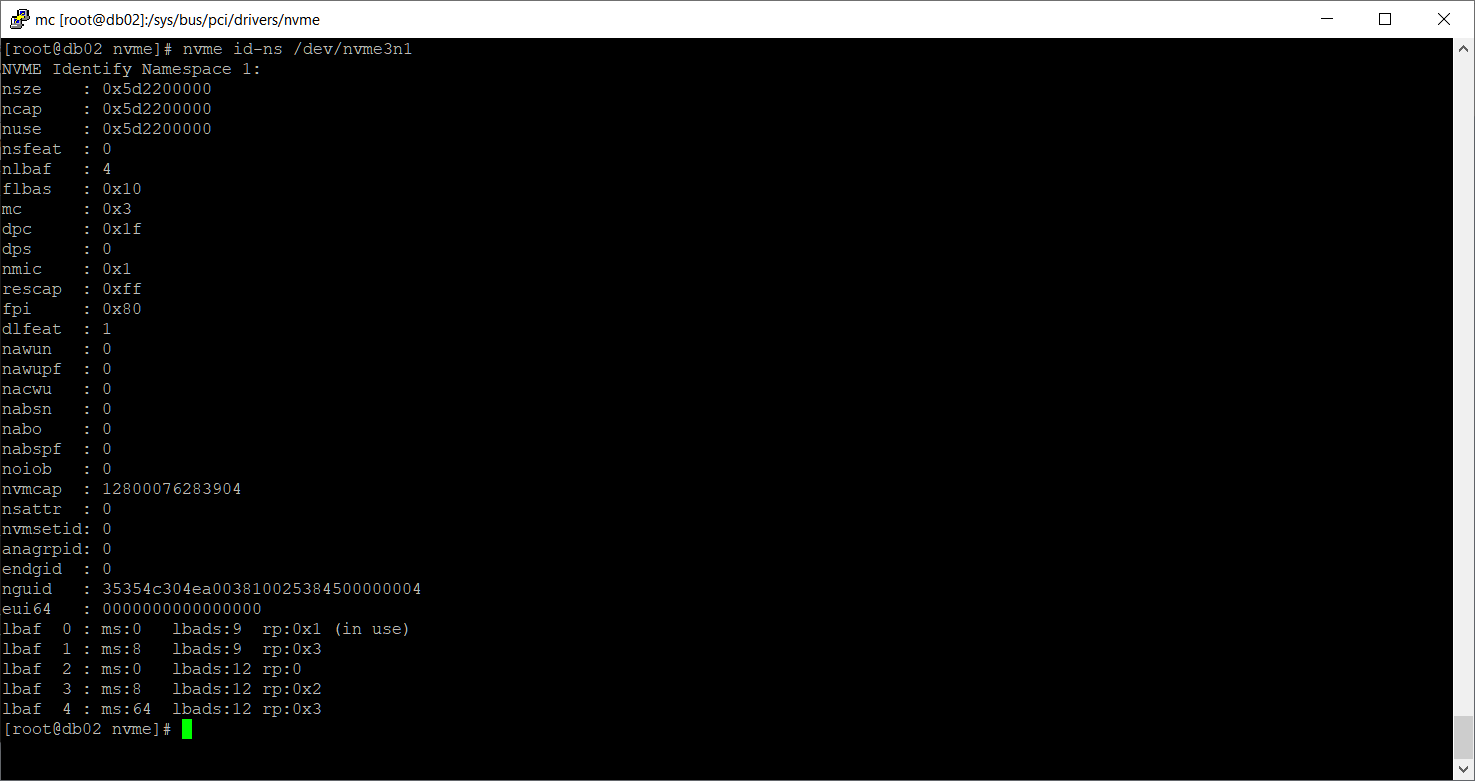
Namespace существует. Посмотрим раздел.
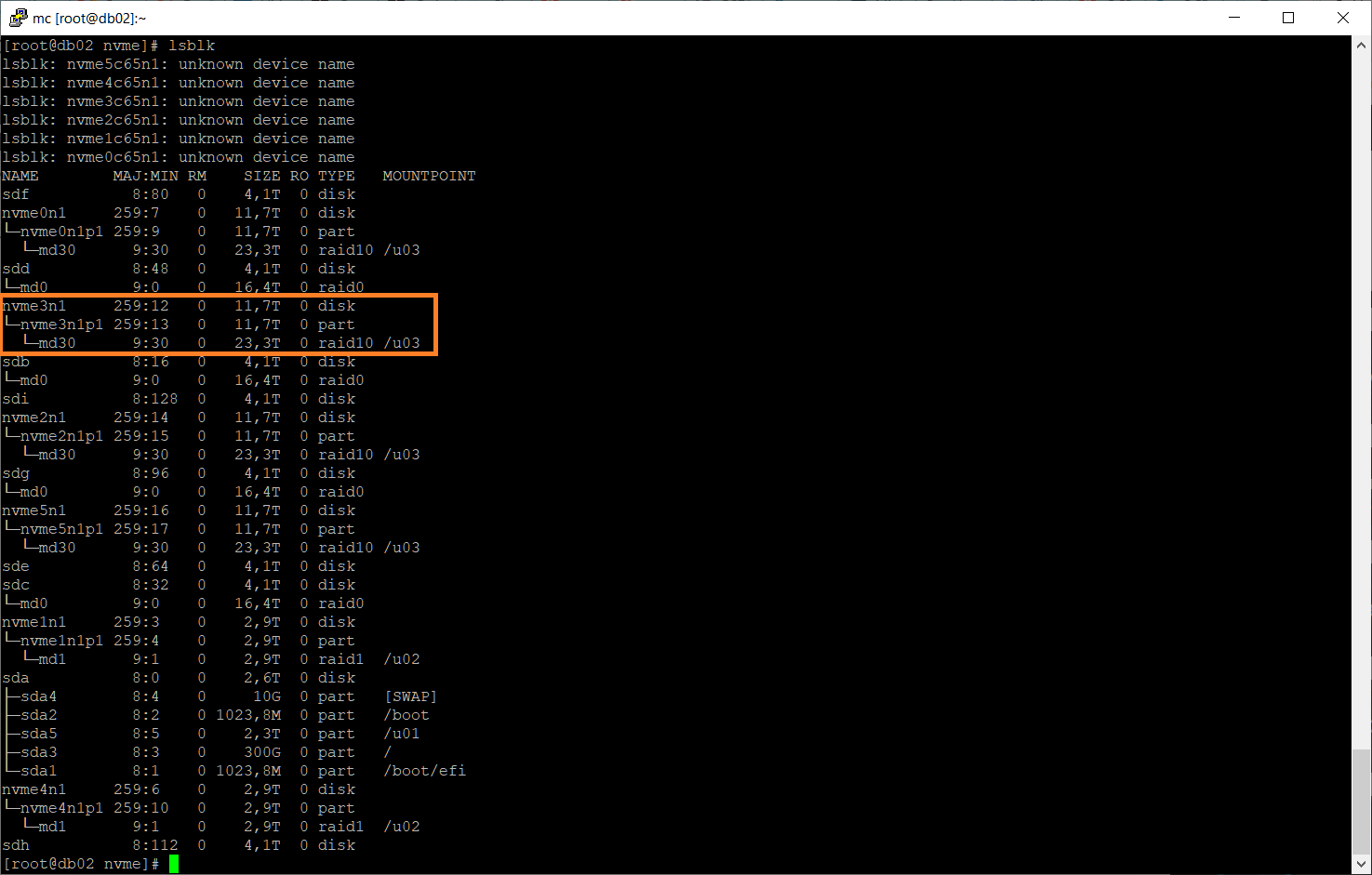
Раздел /dev/nvme3n1p1 существует. Поскольку раздел ещё числится в массиве как сбойный, выкинем его оттуда:
mdadm /dev/md30 --remove /dev/nvme3n1p1 mdadm --detail /dev/md30Теперь сбойных дисков в массиве не числится.
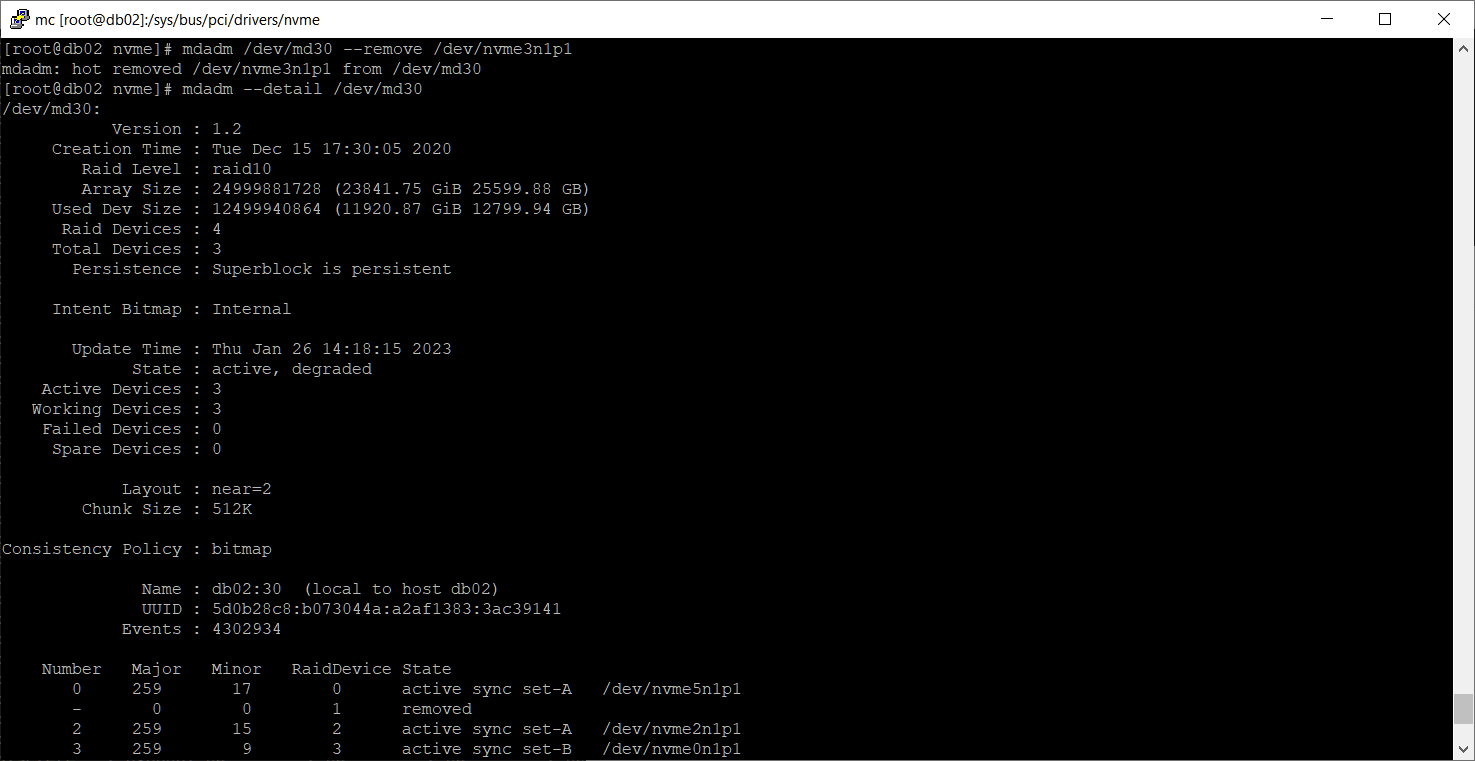
mdadm /dev/md30 --add /dev/nvme3n1p1 cat /proc/mdstat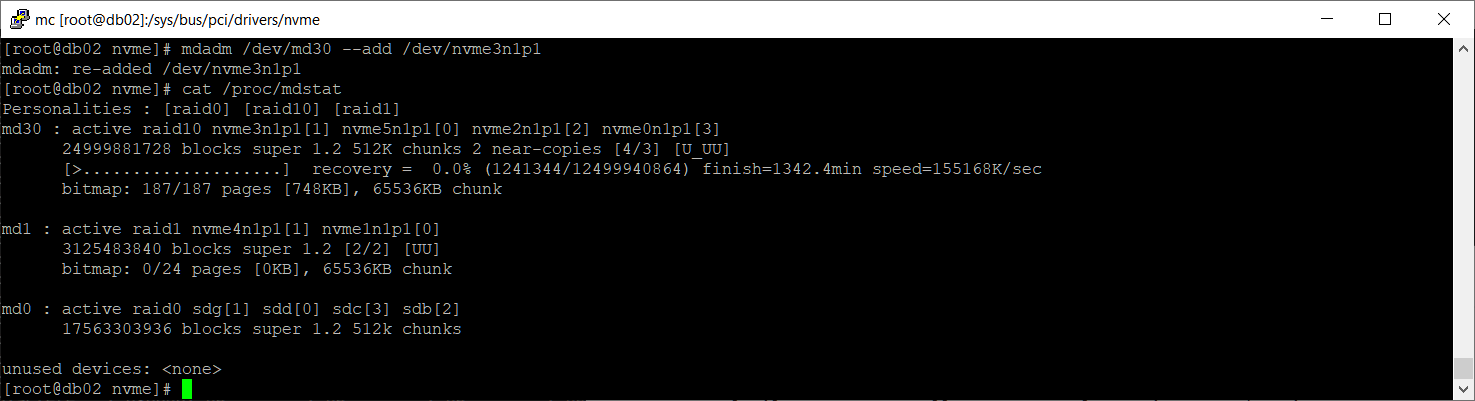
Массив начал восстанавливаться.
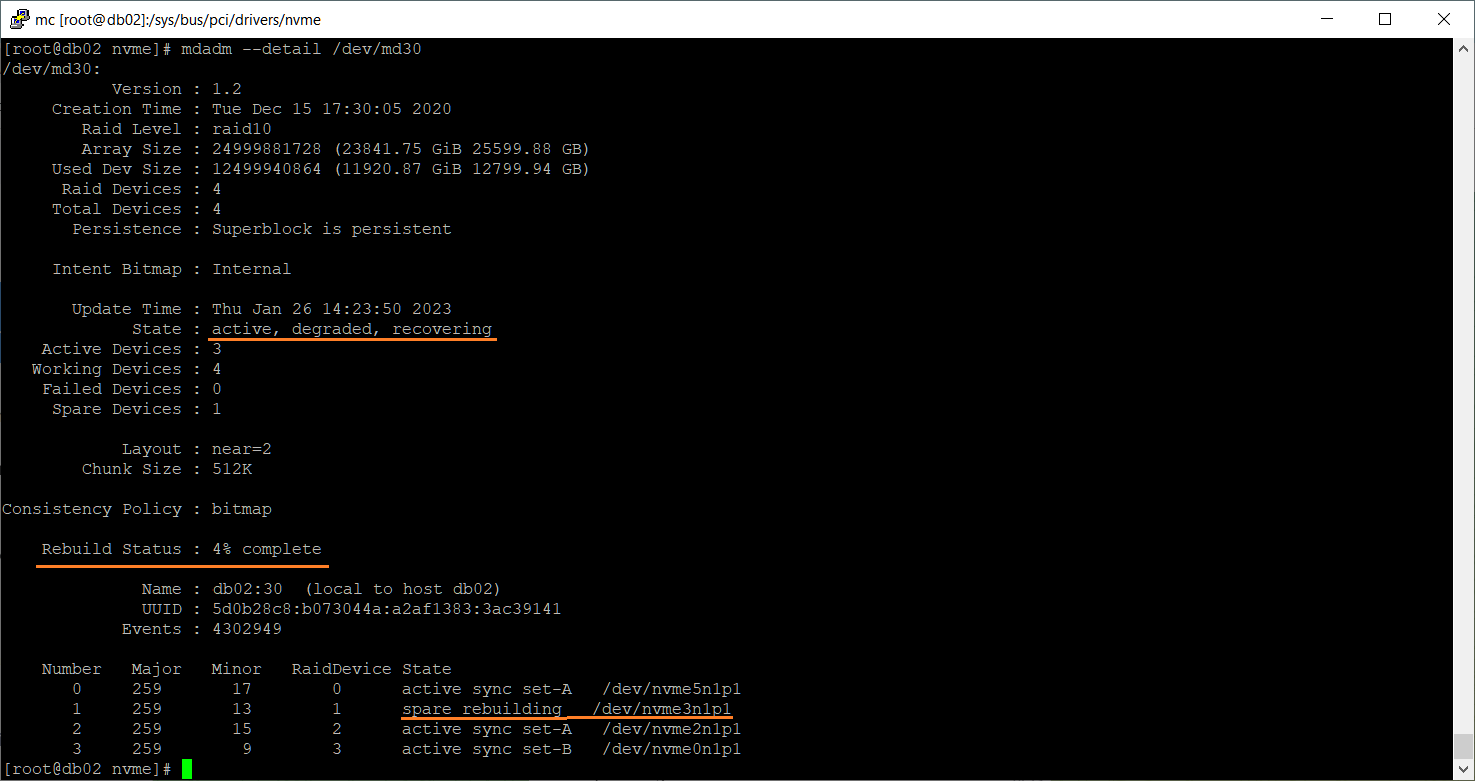
Осталось дождаться окончания процедуры перестроения массива.