- Установка и настройка СУБД PostgreSQL (Linux)#
- Необходимое программное обеспечение под ОС Astra Linux / Debian#
- Установка#
- Дополнительная настройка#
- Развертывание новой базы#
- Развертывание поставочного дампа#
- Установка PostgreSQL в Ubuntu
- Установка PostgreSQL в Ubuntu 20.04
- 1. Установка из официальных репозиториев
- 2. Установка из официальных репозиториев PostgreSQL
- Настройка PostgreSQL в Ubuntu 20.04
- Создание роли postgresql
- Создание базы данных
- Создание таблиц
- Выводы
Установка и настройка СУБД PostgreSQL (Linux)#
Необходимое программное обеспечение под ОС Astra Linux / Debian#
- Сервер PostgreSQL 12 или выше
PostgreSQL или Postgres Pro - postgresql-contrib (обычно устанавливаются вместе с сервером Postgres)
- htop
- Iotop
- sysstat
- pgbadger
- ssh (клиент и сервер SSH)
- mc (Midnight Commander)
- tar
- zip
Не рекоммендуется выполнять сборку сервера самостоятельно из исходного кода т.к. нельзя гарантировать стабильность работы таких сборок в продуктивном контуре.
Установка#
Скачайте требуемый пакет с сайта https://postgrespro.ru/products/download или https://www.postgresql.org/download. Для установки следуйте инструкциям на сайте.
Дополнительная настройка#
- В конфигурационном файле postgresql.conf переопределите умолчательные параметры согласно конфигурации железа.
Пример для сервера с конфигурацией ЦП: 4 ядра; ОЗУ: 8 Гб; Диск: SSD:
Добавить в конец конфигурационного файла
#------------------------------------------------------------------------------ # CUSTOMIZED OPTIONS #------------------------------------------------------------------------------ # Memory Configuration shared_buffers = 2GB effective_cache_size = 6GB work_mem = 41MB maintenance_work_mem = 410MB # Checkpoint Related Configuration min_wal_size = 2GB max_wal_size = 3GB checkpoint_completion_target = 0.9 wal_buffers = -1 # Network Related Configuration listen_addresses = '*' max_connections = 100 # Storage Configuration random_page_cost = 1.1 effective_io_concurrency = 200 # Worker Processes Configuration max_worker_processes = 8 max_parallel_workers_per_gather = 2 max_parallel_workers = 2 max_locks_per_transaction = 500
Для подбора параметров можно воспользоваться онлайн-мастером https://www.pgconfig.org
В мастере указать версию постгреса, выбрать профиль DataWare house and BI Applications и указать параметры железа сервера: количество ядер ЦП, размер ОЗУ, тип диска.
# TYPE DATABASE USER ADDRESS METHOD # IPv4 local connections: host all all all md5
Для получения подробной информации по конфигурации Postgres воспользуйтесь документацией на сайте: https://postgrespro.ru/docs
Развертывание новой базы#
Поменяйте пароль пользователю ОС c именем postgres
Подключитесь терминалом к серверу СУБД под пользователем root
Переключитесь на пользователя «postgres»
Подключитесь локально утилитой psql к СУБД Postgres
Поменяйте пароль суперпользователя
alter user postgres password '';
CREATE ROLE WITH LOGIN NOSUPERUSER NOCREATEDB NOCREATEROLE INHERIT NOREPLICATION CONNECTION LIMIT -1 PASSWORD ''; GRANT pg_signal_backend TO ;
Создайте новую БД, в качестве владельца укажите созданного пользователя
CREATE DATABASE "" WITH OWNER = ENCODING = 'UTF8' CONNECTION LIMIT = -1;
Подключитесь к созданной бд
Подключите, необходимые для работы Global, расширения
CREATE EXTENSION if not exists plpgsql; CREATE EXTENSION if not exists fuzzystrmatch; CREATE EXTENSION if not exists pg_trgm; CREATE EXTENSION if not exists pg_stat_statements; CREATE EXTENSION if not exists "uuid-ossp"; CREATE EXTENSION if not exists dict_xsyn; CREATE EXTENSION if not exists ltree;
Теперь БД готова к работе.
Развертывание поставочного дампа#
При получении преднастроенного поставочного дампа нагоните его на созданную БД.
Если БД не пуста и содержит объекты, удалите их
При наличии прав суперпользователя Postgres можно удалить БД
и создать заново, выполнив шаги раздела «Развертывание новой базы»
Если прав суперпользователя Postgres нет, воспользуйтесть скриптом удаления
SET search_path TO public; -- DO $$ DECLARE r RECORD; BEGIN FOR r IN (SELECT p.oid::regprocedure as sFunctionName FROM pg_proc p INNER JOIN pg_namespace ns ON (p.pronamespace = ns.oid) inner join pg_roles a on p.proowner =a.oid WHERE ns.nspname = current_schema and a.rolname =current_user and p.probin is null) LOOP EXECUTE 'DROP FUNCTION IF EXISTS ' || r.sFunctionName || ' CASCADE'; END LOOP; END $$; -- DO $$ DECLARE r RECORD; BEGIN FOR r IN (SELECT tablename FROM pg_tables WHERE schemaname = current_schema()) LOOP EXECUTE 'DROP TABLE IF EXISTS ' || quote_ident(r.tablename) || ' CASCADE'; END LOOP; END $$; -- DO $$ DECLARE r RECORD; BEGIN FOR r IN (SELECT c.relname FROM pg_class c inner join pg_catalog.pg_namespace n on c.relnamespace =n.oid inner join pg_roles a on c.relowner =a.oid WHERE (c.relkind = 'S') and n.nspname =current_schema and a.rolname =current_user) LOOP EXECUTE 'drop sequence IF EXISTS ' || quote_ident(r.relname) || ' CASCADE'; END LOOP; END $$; -- DO $$ DECLARE r RECORD; BEGIN FOR r IN (SELECT c.relname FROM pg_class c inner join pg_catalog.pg_namespace n on c.relnamespace =n.oid inner join pg_roles a on c.relowner =a.oid where c.relkind ='v' and n.nspname =current_schema and a.rolname =current_user) LOOP EXECUTE 'drop view IF EXISTS ' || quote_ident(r.relname) || ' CASCADE'; END LOOP; END $$; -- SELECT lo_unlink(l.oid) FROM pg_largeobject_metadata l inner join pg_roles a on l.lomowner =a.oid WHERE a.rolname =current_user;
Поставочный дамп запакован архиватором tar
Имя файла архива имее следующий вид: _public__.tar Пример: demoDb_public_04.11.2022_170406.tar
Загрузите файл поставочного дампа на сервер Postgres в директорию /usr/dumpstore
mkdir -p /tmp/global/Dump tar -xvf /usr/dumpstore/_public__.tar -C /tmp/global/Dump --strip-components 1 Дамп распакуется в каталог /tmp/global/Dump/_public__
/opt/pgpro/std-12/bin/pg_restore —dbname=postgresql://:@localhost:5432/ -O -x -v —no-tablespaces —jobs=4 /tmp/global/Dump/_public__
/opt/pgpro/std-12/bin/pg_restore — путь до утилиты распаковки дампа (postgres pro 12)
jobs=4 — количество потоков, указывать по количеству ядер
Установка PostgreSQL в Ubuntu
Реляционные системы управления базами данных (РСУБД) — это ключевой компонент многих веб-сайтов и приложений. Они обеспечивают структурированный способ хранения данных и организацию доступа к информации. PostgreSQL- это объектно-реляционная система управления базами данных, которая все больше и больше вытесняет MySQL и производственных серверов.
Её преимущество в множестве дополнительных функций и улучшений, таких как надежная передача данных и параллелизация без блокировок чтения. Вы можете использовать эту СУБД с различными языками программирования, а её синтаксис запросов PL/pgSQL очень похож на MySQL от Oracle. В этой статье мы рассмотрим, как выполняется установка PostgreSQL в Ubuntu 20.04 из официальных репозиториев и репозитория PostgreSQL (PPA) а так же, как выполнить первоначальную настройку и подготовку к работе c данной СУБД.
Установка PostgreSQL в Ubuntu 20.04
1. Установка из официальных репозиториев
Это очень популярная СУБД, потому программа присутствует в официальных репозиториях. Для установки выполните следующие команды. Сначала обновите списки пакетов:
Установите СУБД PostgreSQL:
sudo apt -y install postgresql
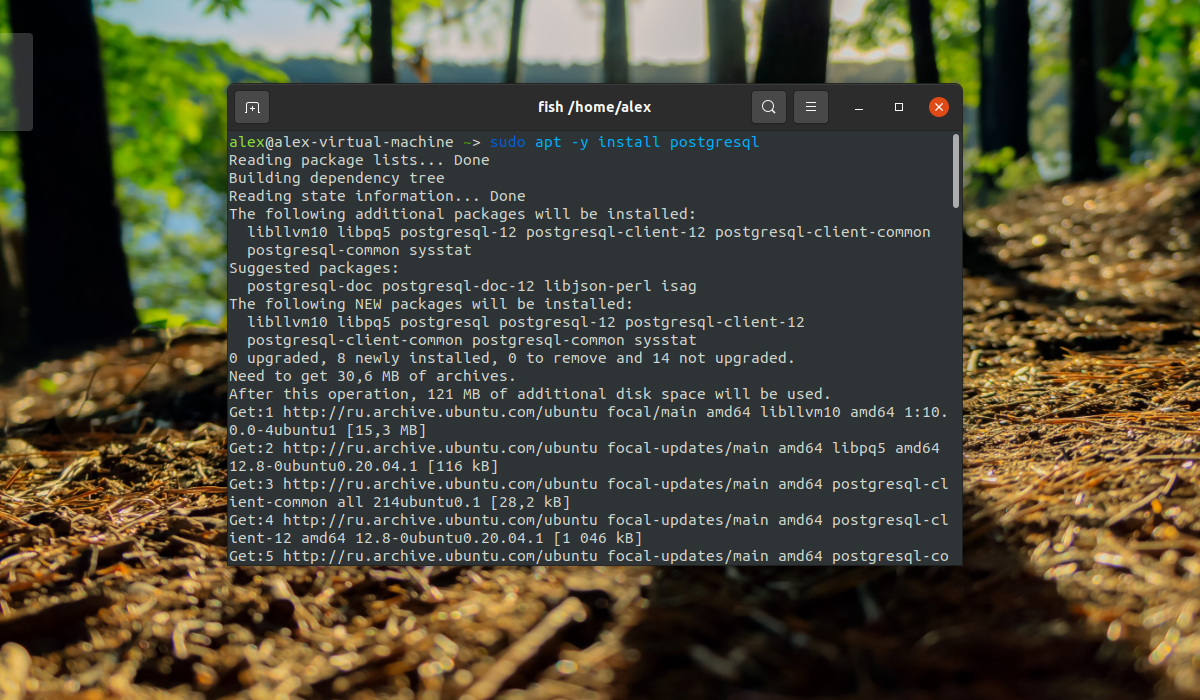
2. Установка из официальных репозиториев PostgreSQL
Если есть необходимость в получение самой последней версии, то необходимо добавить в систему официальный PPA от разработчиков PostgreSQL. Для этого выполните следующие команды:
sudo sh -c ‘echo «deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main» > /etc/apt/sources.list.d/pgdg.list’
wget —quiet -O — https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add —
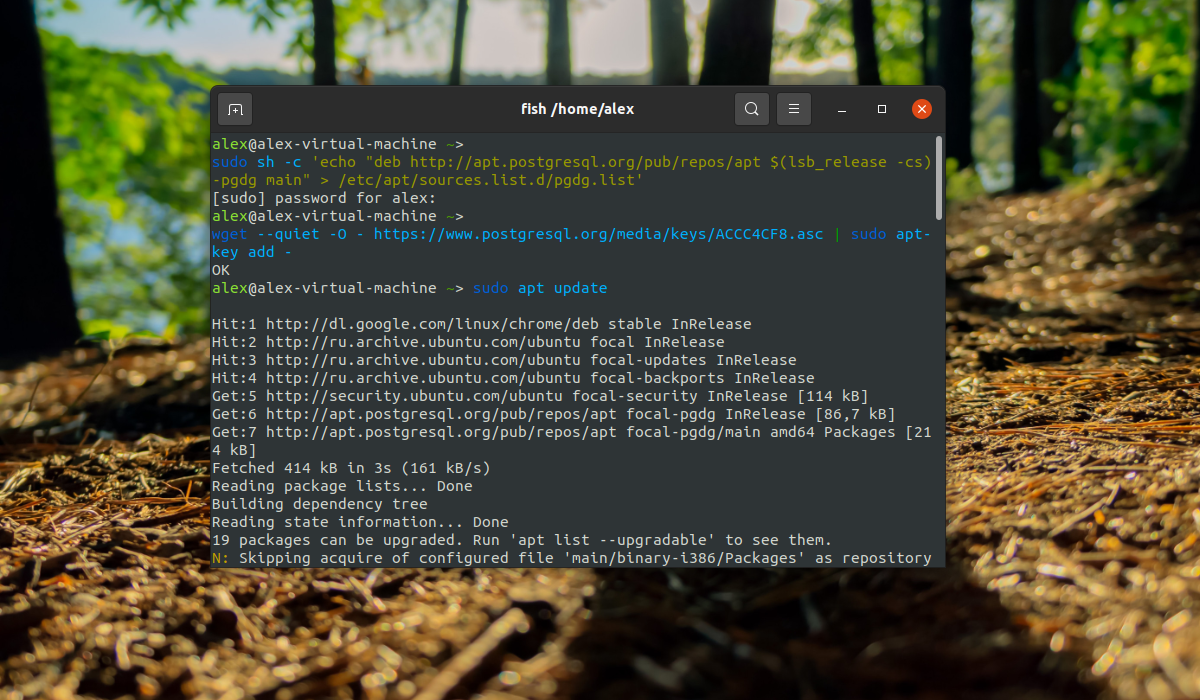
Далее обновите списки пакетов, чтобы получить самую новую доступную версию:
Установка PostgreSQL из PPA или официальных репозиториев выглядит одинаково:
sudo apt -y install postgresql
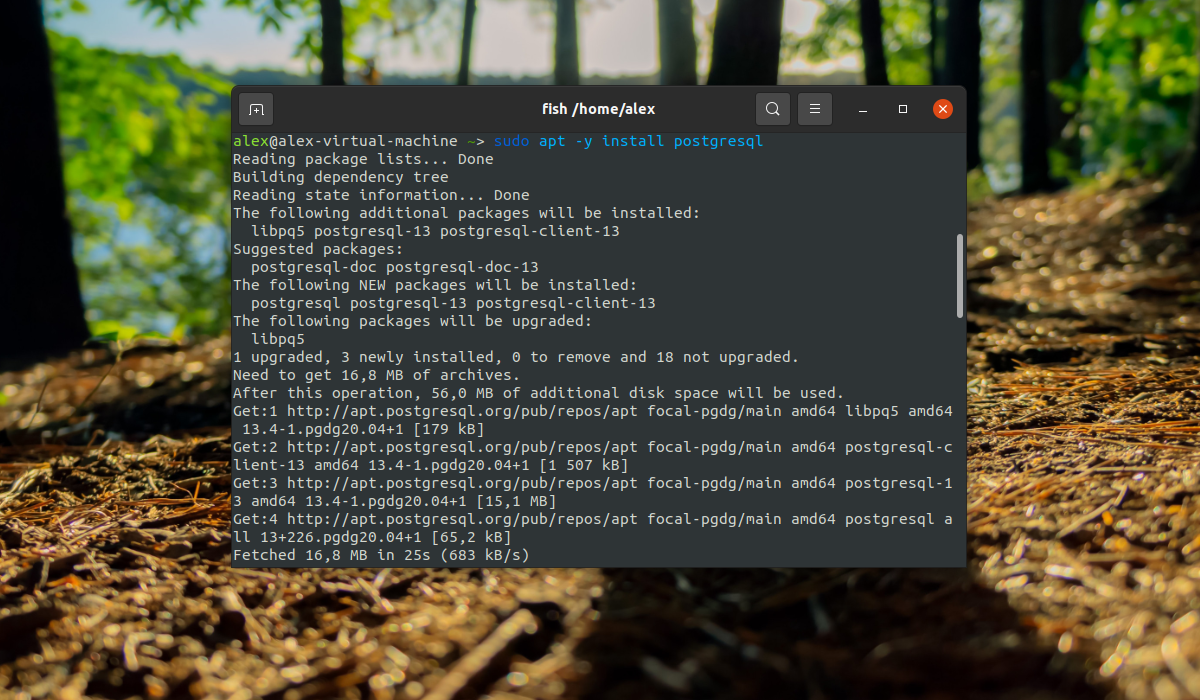
Настройка PostgreSQL в Ubuntu 20.04
После установки СУБД откройте терминал и переключитесь на пользователя postgres с помощью команды:
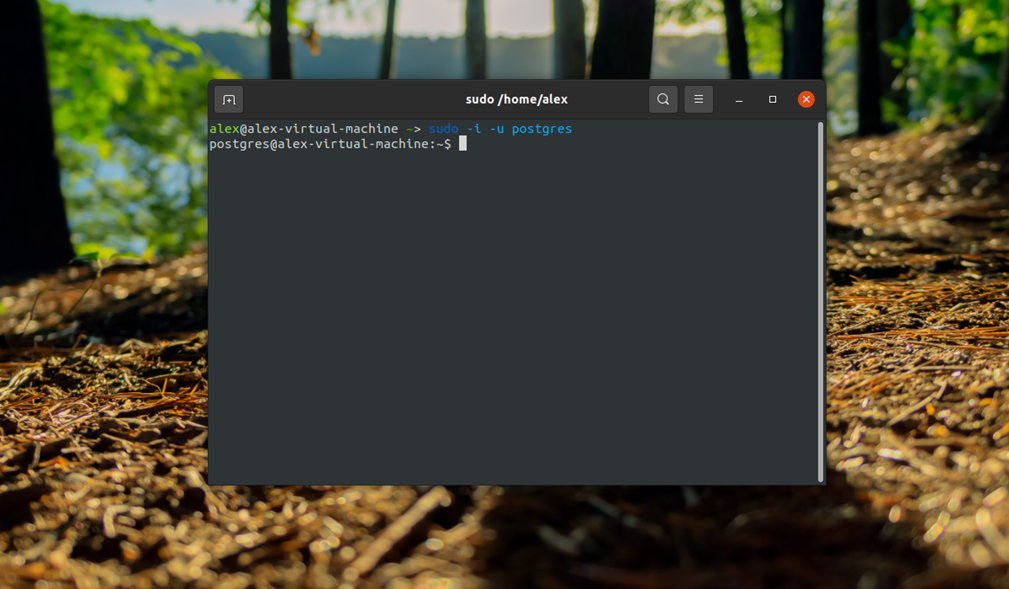
Эта учетная запись создается во время установки программы и на данный момент вы можете получить доступ к системе баз данных только с помощью нее. По умолчанию PostgreSQL использует концепцию ролей для аутентификации и авторизации.
Это очень похоже на учетные записи Unix, но программа не различает пользователей и групп, есть только роли. Сразу после установки PostgreSQL пытается связать свои роли с системными учетными записями, если для имени системной учетной записи существует роль, то пользователь может войти в консоль управления и выполнять позволенные ему действия. Таким образом, после переключения на пользователя postgres вы можете войти в консоль управления:
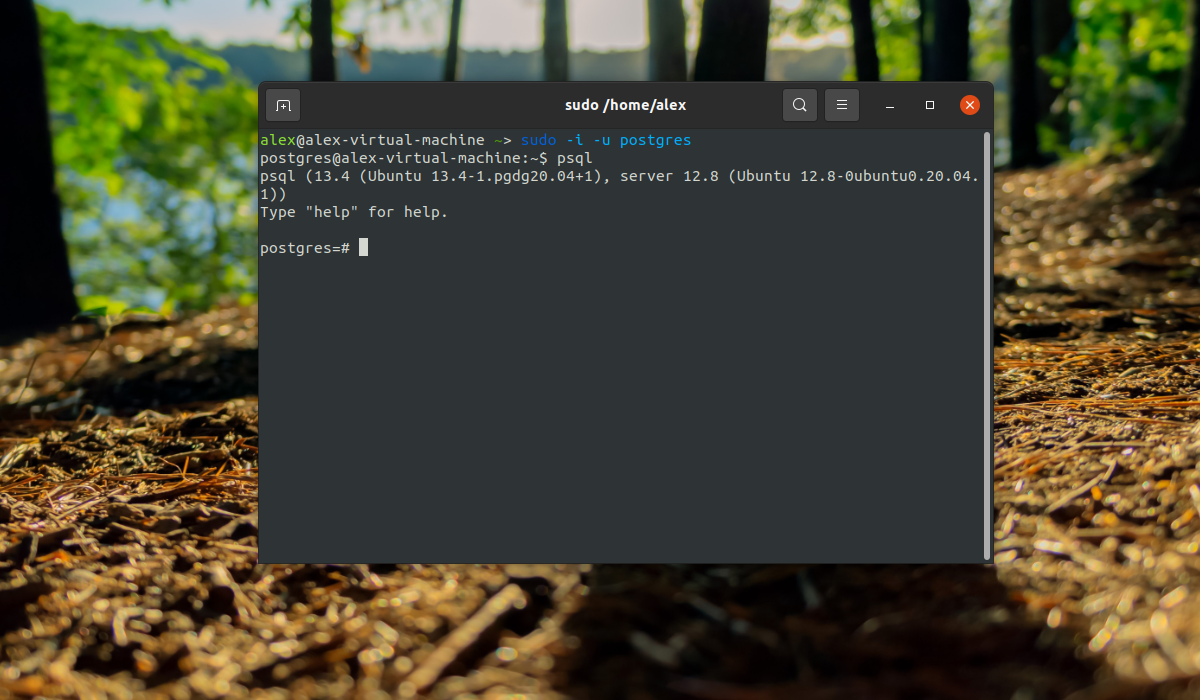
И посмотреть информацию о соединении:
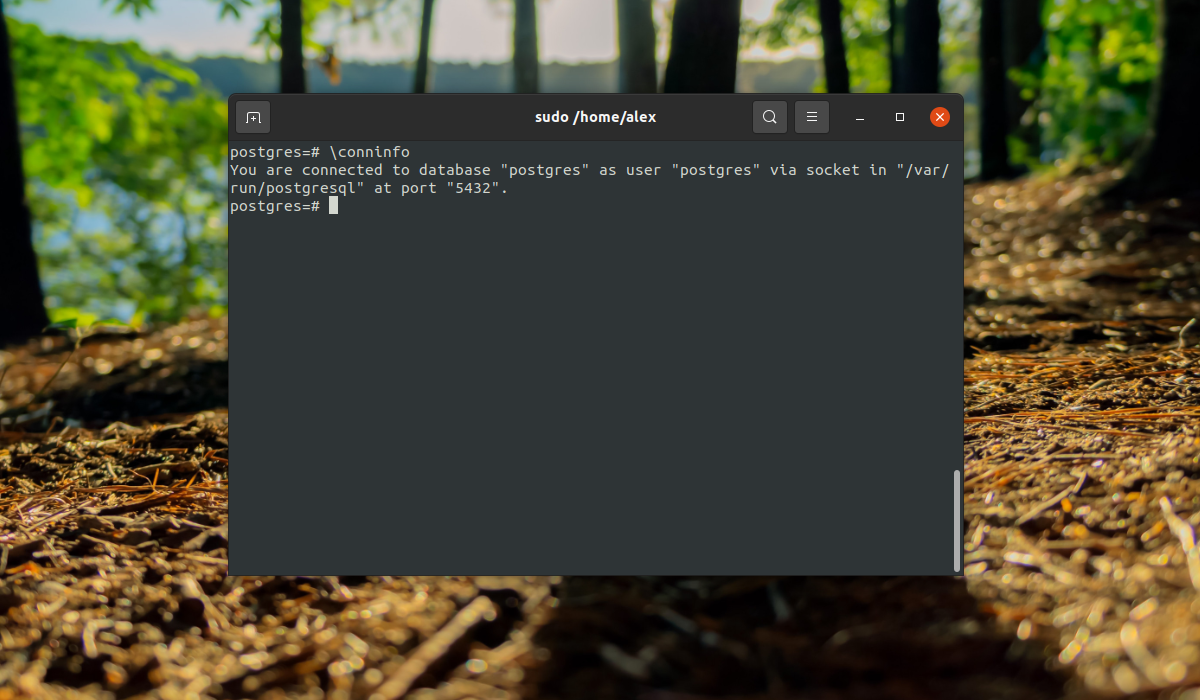
Теперь рассмотрим, как создать другие роли и базы данных.
Создание роли postgresql
Вы уже можете полноценно работать с базой данных с помощью учетной записи postgres, но давайте создадим дополнительную роль. Учетная запись postgres является администратором, поэтому имеет доступ к функциям управления. Для создания пользователя выполните команду:
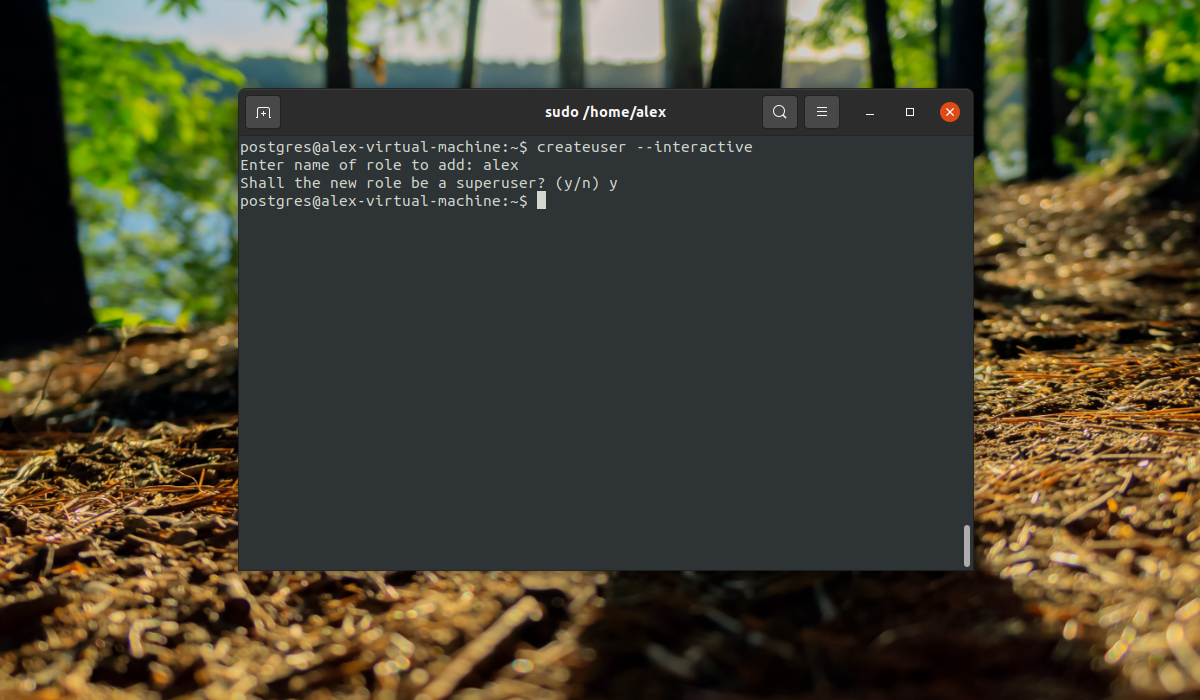
Скрипт задаст лишь два вопроса, имя новой роли и нужно ли делать ее суперпользователем.
Создание базы данных
Точно также как имена ролей сопоставляются с системными пользователями, имя базы данных будет подбираться по имени пользователя. Например, если мы создали пользователя alex, то по умолчанию система попытается получить доступ к базе данных alex. Мы можем ее очень просто создать:
Дальше, чтобы подключиться к этой базе данных нам нужно войти от имени одноименного пользователя:
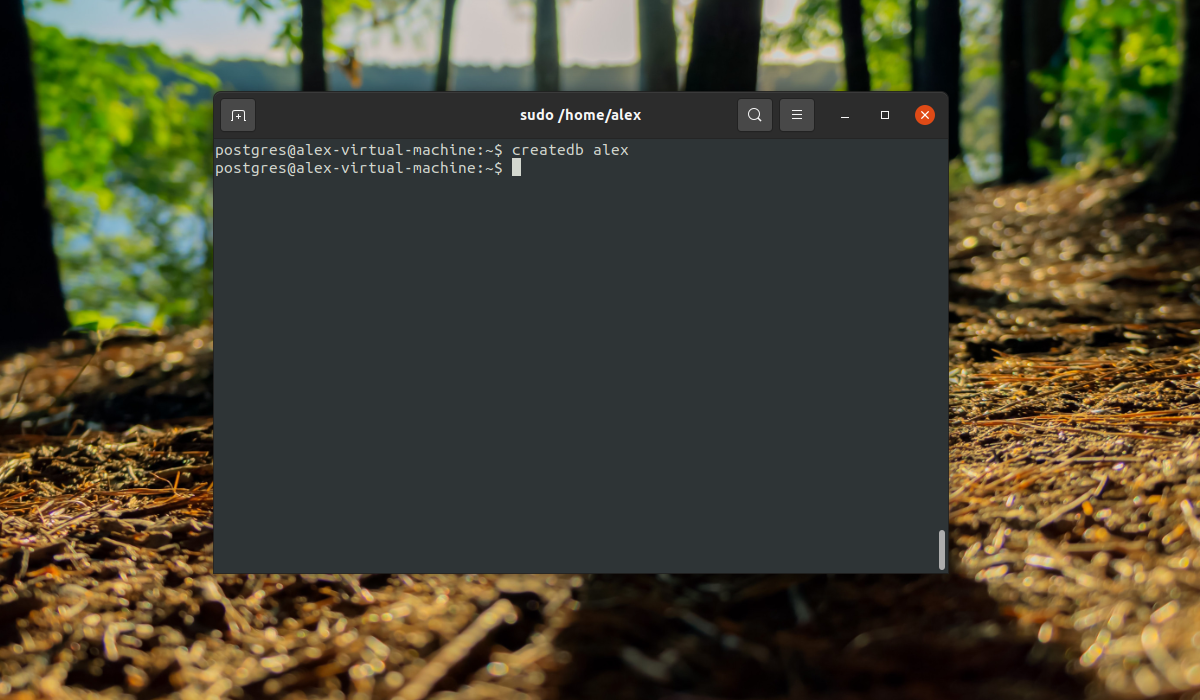
Заходим в консоль и смотрим информацию о подключении:
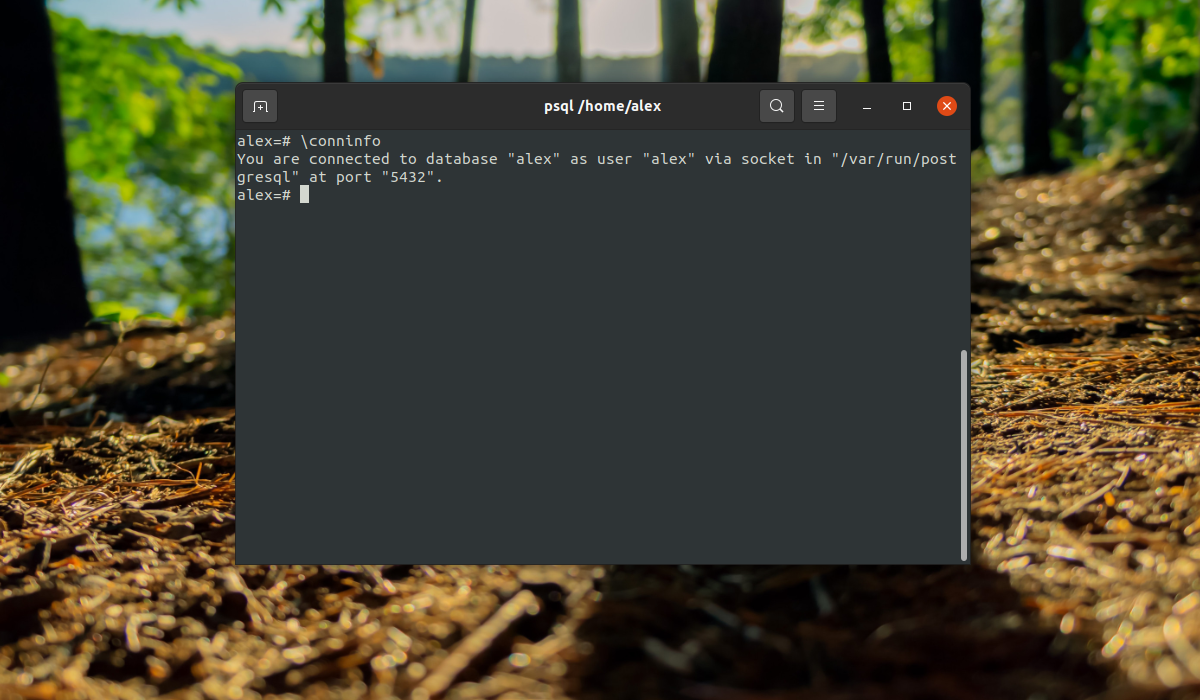
Все верно сработало. Мы подключились с помощью роли alex к базе alex. Если нужно указать другую базу данных, вы можете сделать это с помощью опции -d, например:

Все сработало верно, при условии, что все компоненты были настроены как описано выше.
Создание таблиц
Теперь, когда вы знаете, как подключится к базе данных PostgreSQL, давайте рассмотрим, как выполняются основные задачи. Сначала разберем создание таблиц для хранения некоторых данных. Для создания таблицы PostgreSQLиспользуется такой синтаксис:
CREATE TABLE имя_таблицы (имя_колонки1 тип_колонки (длина) ограничения, имя_колонки2 тип_колонки (длина), имя_колонки3 тип_колонки (длина));
Как видите, сначала мы задаем имя таблицы, затем описываем каждый столбец. Столбец должен иметь имя, тип и размер, также можно задать ограничения для данных, которые там будут содержаться. Например:
CREATE TABLE playground (equip_id serial PRIMARY KEY, type varchar (50) NOT NULL, color varchar (25) NOT NULL, location varchar(25) check (location in (‘north’, ‘south’, ‘west’, ‘east’, ‘northeast’, ‘southeast’, ‘southwest’, ‘northwest’)), install_date date );
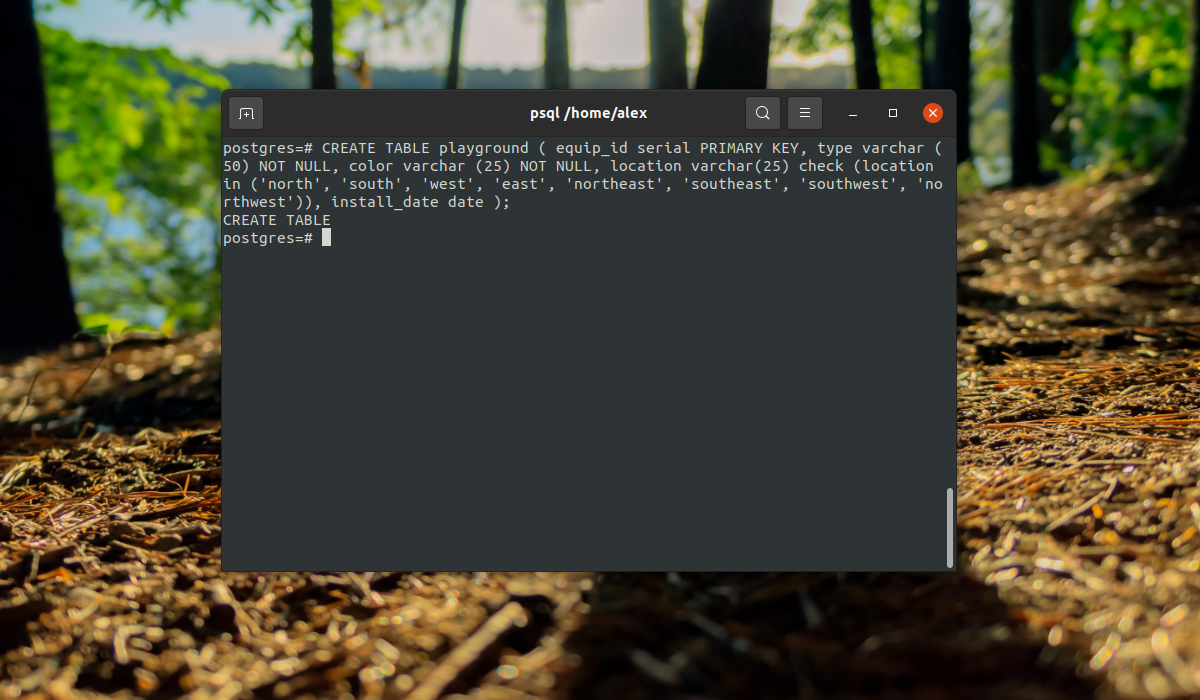
Мы создали таблицу детской площадки для описания оборудования, которое на ней есть. Сначала идет идентификатор equip_id, который имеет тип serial, это значит, что его значение будет автоматически увеличиваться, ключ primary key значит, что значения должны быть уникальны.
Следующие колонки — обычные строки, для них мы задаем длину поля, они не могут быть пустыми (NOT NULL). Следующий столбец тоже строка, но она может содержать только одно из указанных значений, последний столбец — дата создания.
Вы можете вывести все таблицы, выполнив команду:
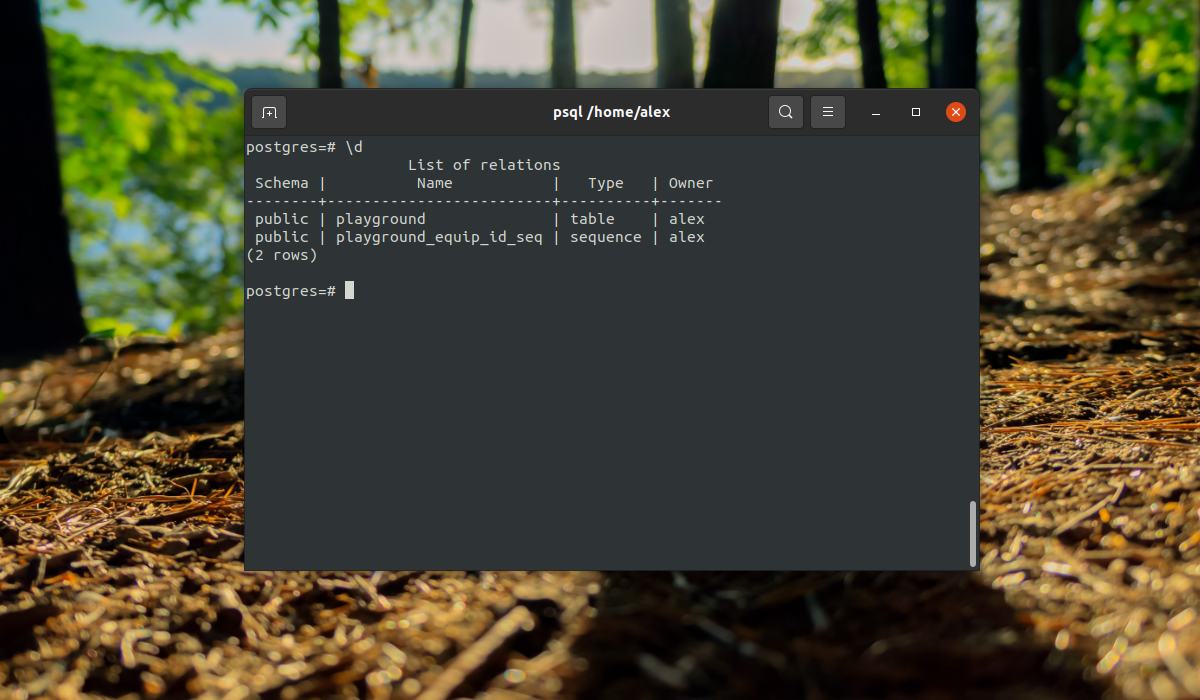
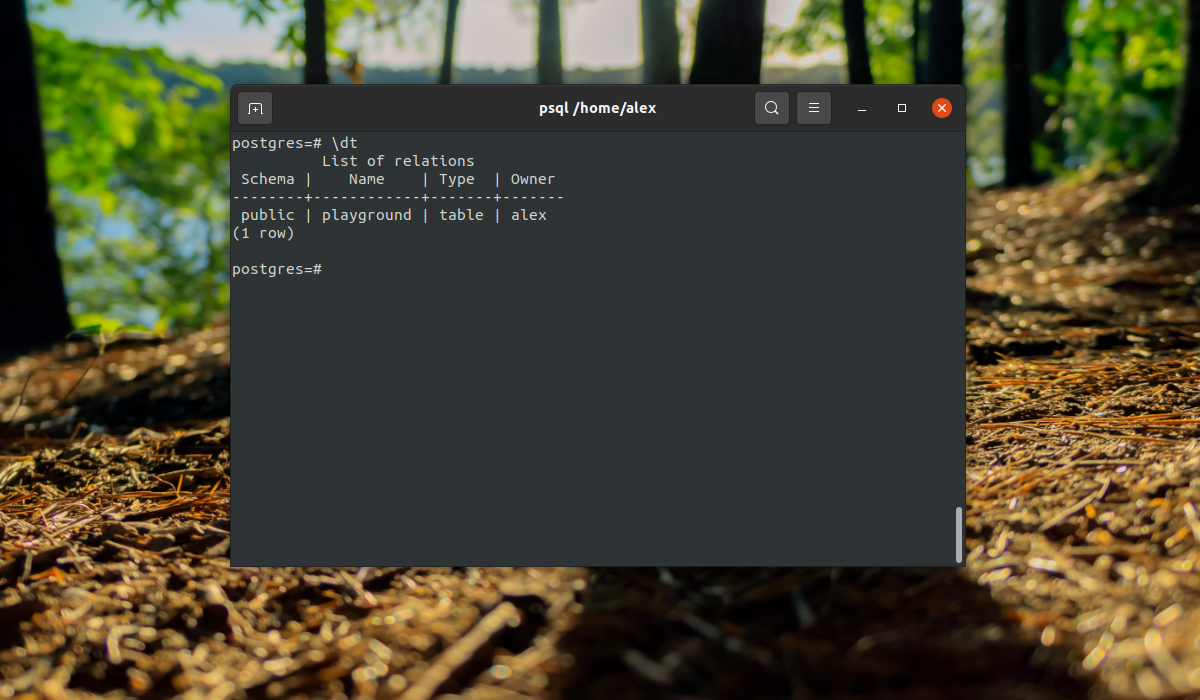
Здесь мы видим, что кроме нашей таблицы, существует еще одна переменная -playground_equip_id_seq. В ней содержится последнее значение этого поля. Если нужно вывести только таблицы, выполните:
Выводы
Теперь установка Postgresql в Ubuntu 20.04 завершена, и вы прошли краткий экскурс в синтаксис PgSQL, который очень похож на привычный нам MySQL, но имеет некоторые отличия. Если у вас остались вопросы, спрашивайте в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.