- sysctl Command in Linux | Explained
- How to Use the sysctl Command in Linux?
- Example 1: Display All Kernel Parameters
- Example 2: Check the Value of a Single Parameter
- Example 3: Modify Kernel Parameters Temporarily
- Example 4: Modify Kernel Parameters Permanently
- Conclusion
- What do ‘real’, ‘user’ and ‘sys’ mean in the output of time(1)?
- 8 Answers 8
- More accurate equivalent for «time» command in Linux, regarding sys- and usertime?
- 3 Answers 3
sysctl Command in Linux | Explained
The system administrator is the one who takes care of the computers, which includes the network, user & rights management, and a few other essential jobs. To do that, the sysctl command is helpful. It allows the user to modify the kernel parameters on the Linux system at runtime.
These kernel parameters can be set at three instances: kernel building, system boot, and run time. The “/proc/sys” contains all the kernel parameters. This article will explain the following about the sysctl command in Linux.
- How to Use the sysctl Command in Linux?
- Example 1: Display All Kernel Parameters
- Example 2: Check the Value of a Single Parameter
- Example 3: Modify Kernel Parameters Temporarily
- Example 4: Modify Kernel Parameters Permanently
How to Use the sysctl Command in Linux?
The primary purpose of the sysctl command is to modify the kernel parameters. The syntax followed by this command is provided below.
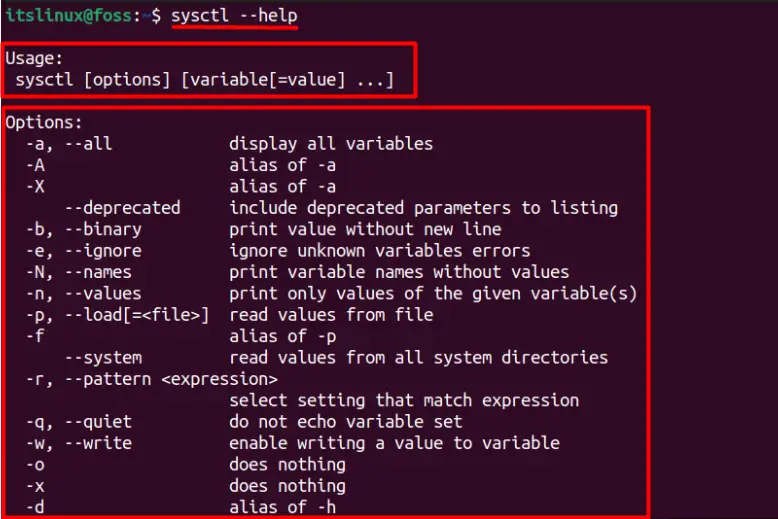
The “sysctl” usage depends on the variety of options offered by it. The details about the options and the basic syntax can be obtained using the below command.

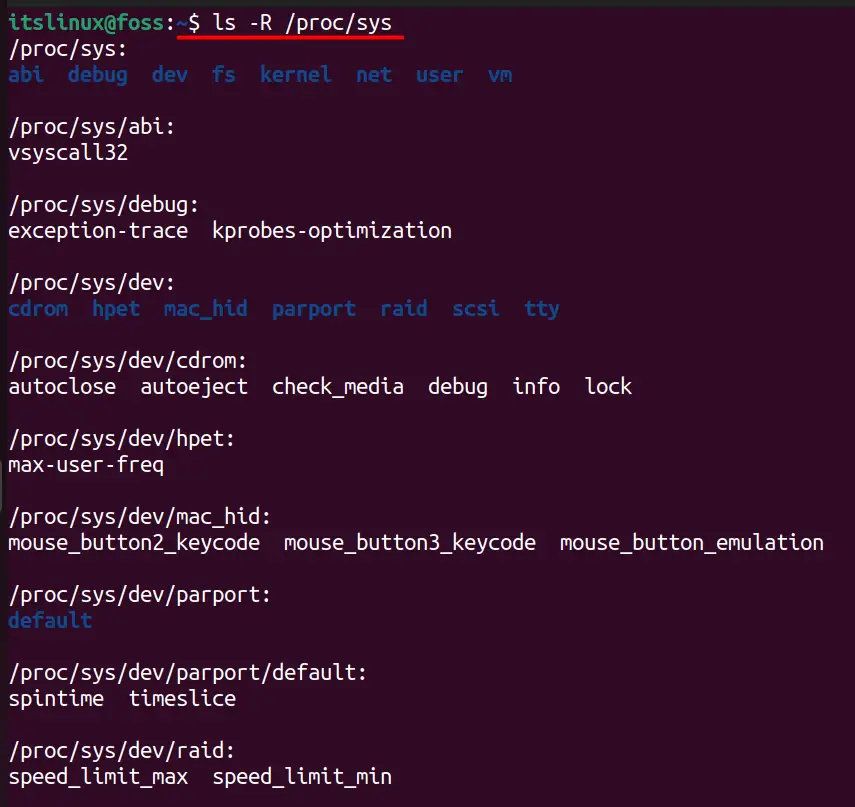
The “/proc/sys” directory is used by the sysctl command to modify the kernel parameters, and the directory’s contents can be listed using the following command.
The above image is cropped, and you will see a long list when executing the command.
Example 1: Display All Kernel Parameters
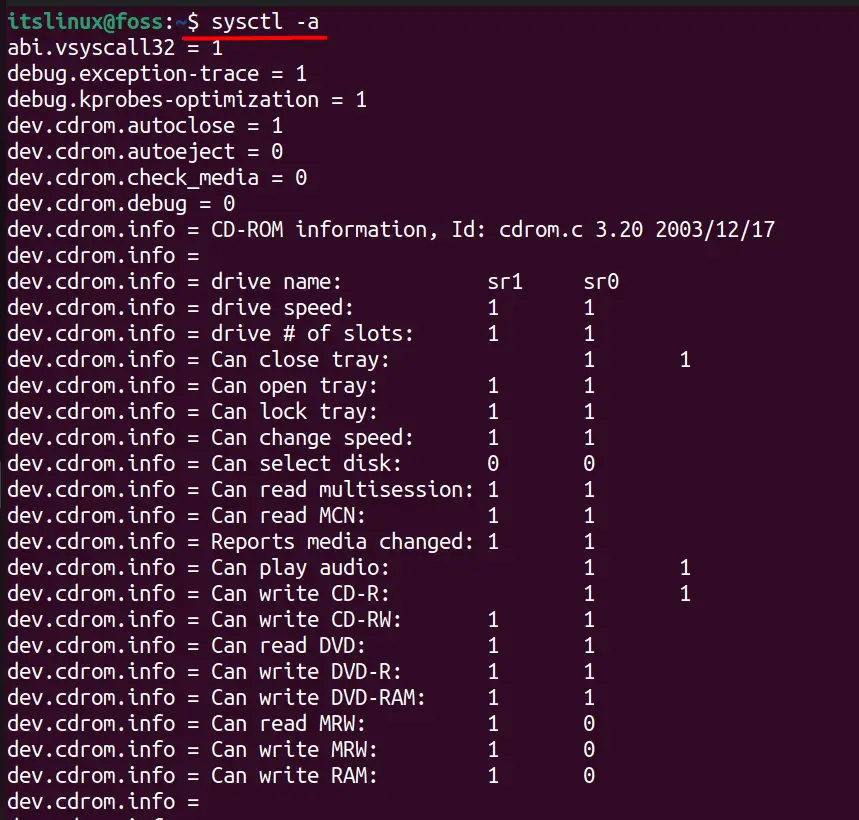
To get a complete list of all configured kernel parameters, the “-a” or “-all” flag is used in the following syntax.
And the above list goes entirely down below.
Example 2: Check the Value of a Single Parameter
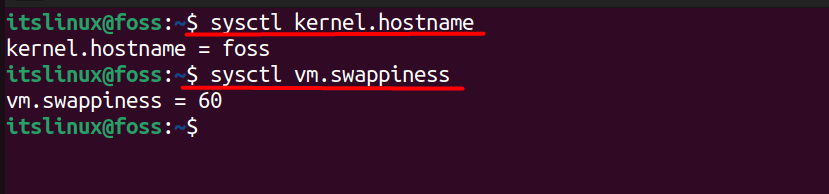
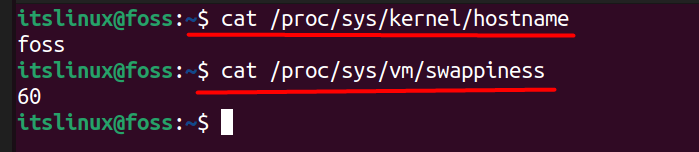
you’ll find it a bit difficult to find what you’re looking for, so check the value of a single parameter. We will test it by getting the kernel hostname’s name and knowing how often the system uses the swap space (a portion of virtual memory on the hard disk used by the system when RAM is full.)
The following syntax is used to check the value of a single parameter.
If you’re having problems with the above command, then you need to use the following command to retrieve the file’s contents.
$ cat /proc/sys/kernel/hostname $ cat /proc/sys/vm/swappiness
Example 3: Modify Kernel Parameters Temporarily
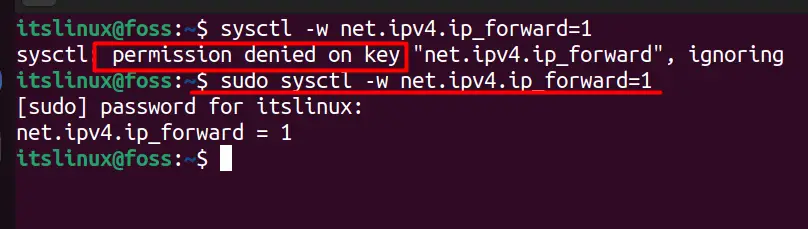
An administrator can use the sysctl command to modify a kernel parameter (temporarily) in the following syntax.
$ sudo sysctl -w parameter=value
The above command requires “sudo,” which gives the current user elevated privileges, and we enabled IPv4 packet forwarding by changing its value to “1,” and if you wish to disable it, use “0.” Although these changes are immediately in effect, you may need to reboot the system.
Modifying the kernel parameters without knowledge about what you are doing may lead to an unstable kernel which means random system crashes and some unbearable bugs, which could be troublesome.
Example 4: Modify Kernel Parameters Permanently
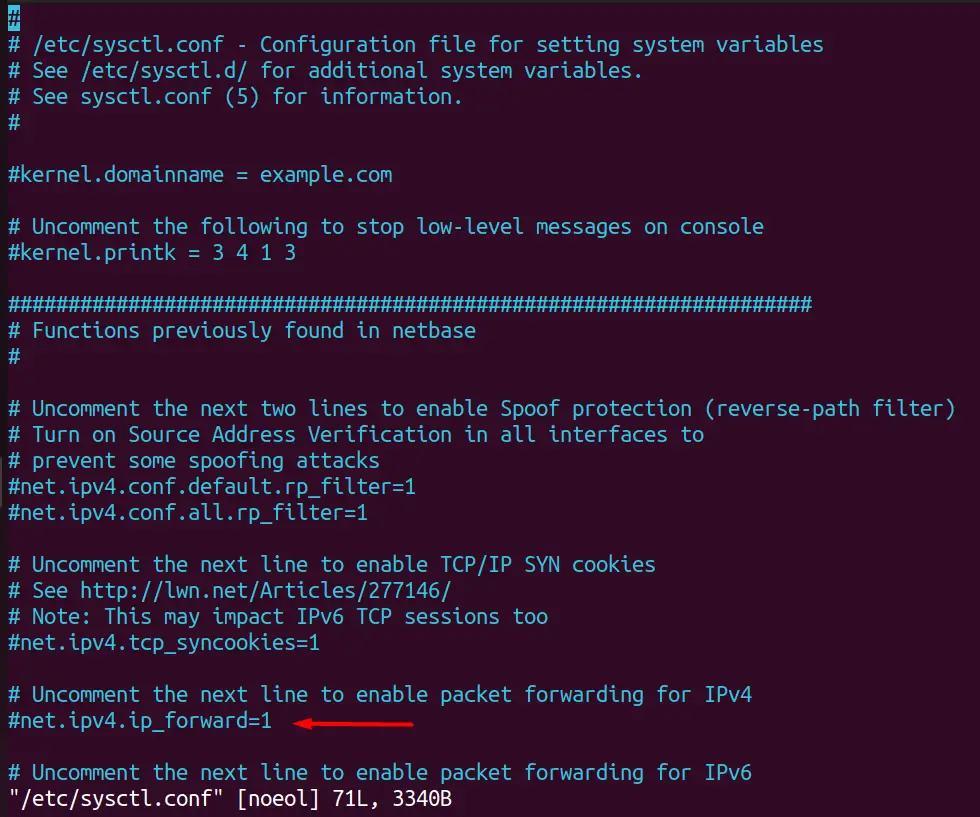
To permanently modify a kernel parameter using the sysctl command, the administrator must write changes to the file opened after executing this command.
As you can see, we have made permanent changes to sysctl.conf file for ipv4.ip_forward=1, as pointed out in the above image.
Note: To execute all the commands we’ve discussed above, you must have root privileges, and a user password may be needed.
Conclusion
The Linux system is powered by its kernel. To modify its parameters, the system administrators often prefer the sysctl command. While making any changes to Kernel parameters, make sure you are well aware of the change; otherwise, misusing can harm the system’s overall functionality. This post has briefly explained the working and usage of the sysctl command in Linux.
What do ‘real’, ‘user’ and ‘sys’ mean in the output of time(1)?
What do real , user and sys mean in the output of time? Which one is meaningful when benchmarking my app?
If your program exits that fast, none of them are meaningful, it’s all just startup overhead. If you want to measure the whole program with time , have it do something that will take at least a second.
It is really important to note that time is a bash keyword. So typing man time is not giving you a man page for the bash time , rather it is giving the man page for /usr/bin/time . This has tripped me up.
8 Answers 8
Real, User and Sys process time statistics
One of these things is not like the other. Real refers to actual elapsed time; User and Sys refer to CPU time used only by the process.
- Real is wall clock time — time from start to finish of the call. This is all elapsed time including time slices used by other processes and time the process spends blocked (for example if it is waiting for I/O to complete).
- User is the amount of CPU time spent in user-mode code (outside the kernel) within the process. This is only actual CPU time used in executing the process. Other processes and time the process spends blocked do not count towards this figure.
- Sys is the amount of CPU time spent in the kernel within the process. This means executing CPU time spent in system calls within the kernel, as opposed to library code, which is still running in user-space. Like ‘user’, this is only CPU time used by the process. See below for a brief description of kernel mode (also known as ‘supervisor’ mode) and the system call mechanism.
User+Sys will tell you how much actual CPU time your process used. Note that this is across all CPUs, so if the process has multiple threads (and this process is running on a computer with more than one processor) it could potentially exceed the wall clock time reported by Real (which usually occurs). Note that in the output these figures include the User and Sys time of all child processes (and their descendants) as well when they could have been collected, e.g. by wait(2) or waitpid(2) , although the underlying system calls return the statistics for the process and its children separately.
Origins of the statistics reported by time (1)
The statistics reported by time are gathered from various system calls. ‘User’ and ‘Sys’ come from wait (2) (POSIX) or times (2) (POSIX), depending on the particular system. ‘Real’ is calculated from a start and end time gathered from the gettimeofday (2) call. Depending on the version of the system, various other statistics such as the number of context switches may also be gathered by time .
On a multi-processor machine, a multi-threaded process or a process forking children could have an elapsed time smaller than the total CPU time — as different threads or processes may run in parallel. Also, the time statistics reported come from different origins, so times recorded for very short running tasks may be subject to rounding errors, as the example given by the original poster shows.
A brief primer on Kernel vs. User mode
On Unix, or any protected-memory operating system, ‘Kernel’ or ‘Supervisor’ mode refers to a privileged mode that the CPU can operate in. Certain privileged actions that could affect security or stability can only be done when the CPU is operating in this mode; these actions are not available to application code. An example of such an action might be manipulation of the MMU to gain access to the address space of another process. Normally, user-mode code cannot do this (with good reason), although it can request shared memory from the kernel, which could be read or written by more than one process. In this case, the shared memory is explicitly requested from the kernel through a secure mechanism and both processes have to explicitly attach to it in order to use it.
The privileged mode is usually referred to as ‘kernel’ mode because the kernel is executed by the CPU running in this mode. In order to switch to kernel mode you have to issue a specific instruction (often called a trap) that switches the CPU to running in kernel mode and runs code from a specific location held in a jump table. For security reasons, you cannot switch to kernel mode and execute arbitrary code — the traps are managed through a table of addresses that cannot be written to unless the CPU is running in supervisor mode. You trap with an explicit trap number and the address is looked up in the jump table; the kernel has a finite number of controlled entry points.
The ‘system’ calls in the C library (particularly those described in Section 2 of the man pages) have a user-mode component, which is what you actually call from your C program. Behind the scenes, they may issue one or more system calls to the kernel to do specific services such as I/O, but they still also have code running in user-mode. It is also quite possible to directly issue a trap to kernel mode from any user space code if desired, although you may need to write a snippet of assembly language to set up the registers correctly for the call.
More about ‘sys’
There are things that your code cannot do from user mode — things like allocating memory or accessing hardware (HDD, network, etc.). These are under the supervision of the kernel, and it alone can do them. Some operations like malloc or fread / fwrite will invoke these kernel functions and that then will count as ‘sys’ time. Unfortunately it’s not as simple as «every call to malloc will be counted in ‘sys’ time». The call to malloc will do some processing of its own (still counted in ‘user’ time) and then somewhere along the way it may call the function in kernel (counted in ‘sys’ time). After returning from the kernel call, there will be some more time in ‘user’ and then malloc will return to your code. As for when the switch happens, and how much of it is spent in kernel mode. you cannot say. It depends on the implementation of the library. Also, other seemingly innocent functions might also use malloc and the like in the background, which will again have some time in ‘sys’ then.
More accurate equivalent for «time» command in Linux, regarding sys- and usertime?
I am in the following situation: I want to determine the sys- and usertime of little snippets of (PHP- and C++) code. Obviously, I could use the «time» binary in Linux, but given the fact that these snippets run so fast, the normal (or even verbose) output of «time» wont suffice my purpose. The accuracy of «time» goes to milliseconds, while I need microseconds. Or even better: nanoseconds. Can anyone point me to a piece of software that can do this for me? I found stuff for walltime, but it is sys- and usertime that I am interested at. Thanks in advance! BTW: Im running Ubuntu 10.10 64-bit
3 Answers 3
There is no method that’s going to give you any equivalent of sys or usertime as reported by the time command that’s going to be any more precise. Much of the apparent precision of the time command is false precision as it is.
The technique for handling this is to put these snippets of code in tight loops that call them thousands of times and figuring out how long a given loop takes from that. And even then you should repeat the experiment a few times and pick the lowest time.
Here’s an analogy describing why the precision is false, and what I mean by that. Suppose you have someone using a stopwatch to time a race by manually hitting the button when the race started and when the person being timed crosses the finish line. Supposedly your stopwatch is accurate to the 100th of a second. But that precision is false because its dwarfed by the errors introduced by the reaction time of the person hitting the button.
This is pretty closely analogous to why time gives you accuracy that’s supposedly in microseconds, but is really significantly less precise. There is a lot going on in any given system at any given point in time, and all of those things introduce error into the calculations. The interrupts from network IO, or disk IO, the timer interrupts for running the scheduler, what other processes do to the L1 or L2 CPU cache. It all adds up.
Using something like valgrind that runs your program on a simulated CPU can give you numbers that are seemingly accurate to the number of CPU cycles. But that precision isn’t what you’ll be experiencing in the real world. It’s better to use the technique I originally described and just accept that these timings can be fuzzy.