- TCP tuning
- [править] TCP Tuning в FreeBSD
- [править] TCP Tuning в Solaris
- [править] TCP Tuning в Windows
- [править] TCP Tuning в Mac OS X
- [править] Полезные программы
- [править] Дополнительная информация
- Тонкая настройка сетевого стека Linux (размер буферов) для повышения производительности сети
- Как настроить эти значения
TCP tuning
There are a lot of differences between Linux version 2.4 and 2.6, so first we’ll cover the tuning issues that are the same in both 2.4 and 2.6. To change TCP settings in, you add the entries below to the file /etc/sysctl.conf, and then run «sysctl -p».
Like all operating systems, the default maximum Linux TCP buffer sizes are way too small. I suggest changing them to the following settings:
# increase TCP max buffer size net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 # increase Linux autotuning TCP buffer limits # min, default, and max number of bytes to use net.ipv4.tcp_rmem = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216
Note: you should leave tcp_mem alone. The defaults are fine.
Another thing you can try that may help increase TCP throughput is to increase the size of the interface queue. To do this, do the following:
ifconfig eth0 txqueuelen 1000
I’ve seen increases in bandwidth of up to 8x by doing this on some long, fast paths. This is only a good idea for Gigabit Ethernet connected hosts, and may have other side effects such as uneven sharing between multiple streams. Linux 2.4
Starting with Linux 2.4, Linux has implemented a sender-side autotuning mechanism, so that setting the opitimal buffer size on the sender is not needed. This assumes you have set large buffers on the recieve side, as the sending buffer will not grow beyond the size of the recieve buffer.
However, Linux 2.4 has some other strange behavior that one needs to be aware of. For example: The value for ssthresh for a given path is cached in the routing table. This means that if a connection has has a retransmition and reduces its window, then all connections to that host for the next 10 minutes will use a reduced window size, and not even try to increase its window. The only way to disable this behavior is to do the following before all new connections (you must be root):
sysctl -w net.ipv4.route.flush=1
More information on various tuning parameters for Linux 2.4 are available in the Ipsysctl tutorial . Linux 2.6
Starting in Linux 2.6.7 (and back-ported to 2.4.27), BIC TCP is part of the kernel, and enabled by default. BIC TCP helps recover quickly from packet loss on high-speed WANs, and appears to work quite well. A BIC implementation bug was discovered, but this was fixed in Linux 2.6.11, so you should upgrade to this version or higher.
Linux 2.6 also includes and both send and receiver-side automatic buffer tuning (up to the maximum sizes specified above). There is also a setting to fix the ssthresh caching weirdness described above.
There are a couple additional sysctl settings for 2.6:
# don't cache ssthresh from previous connection net.ipv4.tcp_no_metrics_save = 1 # recommended to increase this for 1000 BT or higher net.core.netdev_max_backlog = 2500 # for 10 GigE, use this # net.core.netdev_max_backlog = 30000
Starting with version 2.6.13, Linux supports pluggable congestion control algorithms . The congestion control algorithm used is set using the sysctl variable net.ipv4.tcp_congestion_control, which is set to Reno by default. (Apparently they decided that BIC was not quite ready for prime time.) The current set of congestion control options are:
- reno: Traditional TCP used by almost all other OSes. (default)
- bic: BIC-TCP
- highspeed: HighSpeed TCP: Sally Floyd’s suggested algorithm
- htcp: Hamilton TCP
- hybla: For satellite links
- scalable: Scalable TCP
- vegas: TCP Vegas
- westwood: optimized for lossy networks
For very long fast paths, I suggest trying HTCP or BIC-TCP if Reno is not is not performing as desired. To set this, do the following:
sysctl -w net.ipv4.tcp_congestion_control=htcp
More information on each of these algorithms and some results can be found here.
Note: Linux 2.6.11 and under has a serious problem with certain Gigabit and 10 Gig ethernet drivers and NICs that support «tcp segmentation offload», such as the Intel e1000 and ixgb drivers, the Broadcom tg3, and the s2io 10 GigE drivers. This problem was fixed in version 2.6.12. A workaround for this problem is to use ethtool to disable segmentation offload:
This will reduce your overall performance, but will make TCP over LFNs far more stable.
More information on tuning parameters and defaults for Linux 2.6 are available in the file ip-sysctl.txt, which is part of the 2.6 source distribution.
And finally a warning for both 2.4 and 2.6: for very large BDP paths where the TCP window is > 20 MB, you are likely to hit the Linux SACK implementation problem. If Linux has too many packets in flight when it gets a SACK event, it takes too long to located the SACKed packet, and you get a TCP timeout and CWND goes back to 1 packet. Restricting the TCP buffer size to about 12 MB seems to avoid this problem, but clearly limits your total throughput. Another solution is to disable SACK. Linux 2.2
If you are still running Linux 2.2, upgrade! If this is not possible, add the following to /etc/rc.d/rc.local
echo 8388608 > /proc/sys/net/core/wmem_max echo 8388608 > /proc/sys/net/core/rmem_max echo 65536 > /proc/sys/net/core/rmem_default echo 65536 > /proc/sys/net/core/wmem_default
[править] TCP Tuning в FreeBSD
Add these to /etc/sysctl.conf and reboot.
kern.ipc.maxsockbuf=16777216 net.inet.tcp.rfc1323=1 net.inet.tcp.sendspace=1048576 net.inet.tcp.recvspace=1048576
For more info see the: FreeBSD Network Tuning Performance Tuning Guide
FreeBSD version before 4.10 don’t have SACK implemented, which limits its throughput considerably compared to other operating systems. You should upgrade to 4.10 or higher.
[править] TCP Tuning в Solaris
For Solaris create a boot script similar to this (e.g.: /etc/rc2.d/S99ndd)
- !/bin/sh
- increase max tcp window
- Rule-of-thumb: max_buf = 2 x cwnd_max (congestion window)
ndd -set /dev/tcp tcp_max_buf 4194304 ndd -set /dev/tcp tcp_cwnd_max 2097152
ndd -set /dev/tcp tcp_xmit_hiwat 65536 ndd -set /dev/tcp tcp_recv_hiwat 65536
[править] TCP Tuning в Windows
Change the following using the Windows Registry editor:
- turn on window scale and timestamp option: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Tcp1323Opts=3
- set default TCP window size (default = 16KB): HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpWindowSize=131400
- and maybe set this too: (default = not set): HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\GlobalMaxTcpWindowSize=16777216
The default for Tcp1323 is «No value»; the default behavior is do not initiate options, but if requested provide them.
You can use setsockopt() in your program to set your buffers to any size up to GlobalMaxTcpWindowSize, or you can use TcpWindowSize to set the default send and receive buffers for ALL sockets to this size. Its probably not a good idea to set this too large, but setting it up to 128K should be OK.
More information is available in the following Microsoft Documents:
# TCP Configuration Parameters # TCP/IP Implementation Details
This article may also be useful:
# Windows 2000/XP Registry Tweaks
[править] TCP Tuning в Mac OS X
Mac OSX tuning is similar to FreeBSD.
sysctl -w kern.ipc.maxsockbuf=16777216 sysctl -w net.inet.tcp.sendspace=1048576 sysctl -w net.inet.tcp.recvspace=1048576
Apple also provides a Broadband Tuner patch that does a less agressive version of this for Mac OS X 10.4 and above.
[править] Полезные программы
Some useful Network Measurement Tools
- Iperf : nice tool for measuring end-to-end TCP/UDP performance
- pathrate/pathload : tools to measure available bandwidth and capacity
- pipechar: hop-by-hop bottleneck analysis tool
- UDPmon: Network performance measurement tool
- synack: ping replacement for sites that block ping
Some useful Network Testing Tools
- NDT: Web100 based Network Configuration Tester
- tcpdump: dump all TCP header information for a specified source/destination
- tcptrace: format tcpdump output for analysis using xplot
- NLANR TCP Testrig : Nice wrapper for tcpdump and tcptrace tools
[править] Дополнительная информация
Тонкая настройка сетевого стека Linux (размер буферов) для повышения производительности сети
У меня два сервера, расположенных в двух разных центрах обработки данных. Оба сервера имеют дело с множеством одновременных передач больших файлов. Но производительность сети очень низкая для больших файлов, и снижение производительности происходит с большими файлами. Как мне настроить TCP под Linux, чтобы решить эту проблему?
По умолчанию сетевой стек Linux не настроен для высокоскоростной передачи больших файлов по каналам WAN. Это сделано для экономии ресурсов памяти. Вы можете легко настроить сетевой стек Linux, увеличив размер сетевых буферов для высокоскоростных сетей, которые соединяют серверные системы для обработки большего количества сетевых пакетов.
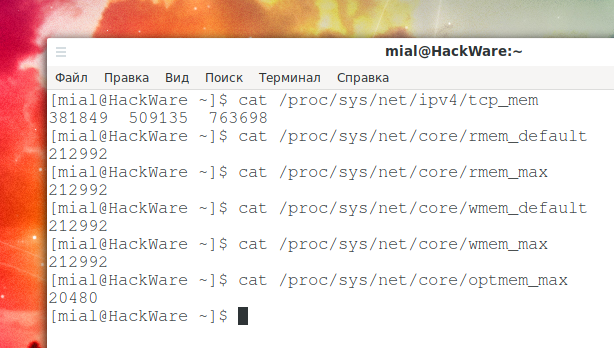
Максимальный размер буфера TCP в Linux по умолчанию слишком мал. Память TCP рассчитывается автоматически на основе системной памяти; вы можете найти фактические значения, введя следующие команды:
cat /proc/sys/net/ipv4/tcp_mem
Объём для принимающей памяти сокета по умолчанию и максимальный:
cat /proc/sys/net/core/rmem_default cat /proc/sys/net/core/rmem_max
По умолчанию и максимальный объём памяти для сокета отправки:
cat /proc/sys/net/core/wmem_default cat /proc/sys/net/core/wmem_max
Максимальный объём опциональных буферов памяти:
cat /proc/sys/net/core/optmem_max
Как настроить эти значения
Внимание: значение по умолчанию для rmem_max и wmem_max составляет около 208 КБ в большинстве дистрибутивов Linux, что может быть достаточно для сетевой среды общего назначения с низкой задержкой или для таких приложений, как DNS/веб-сервер. Однако, если задержка велика, размер по умолчанию может быть слишком маленьким. Обратите внимание, что следующие настройки увеличивают использование памяти на вашем сервере.
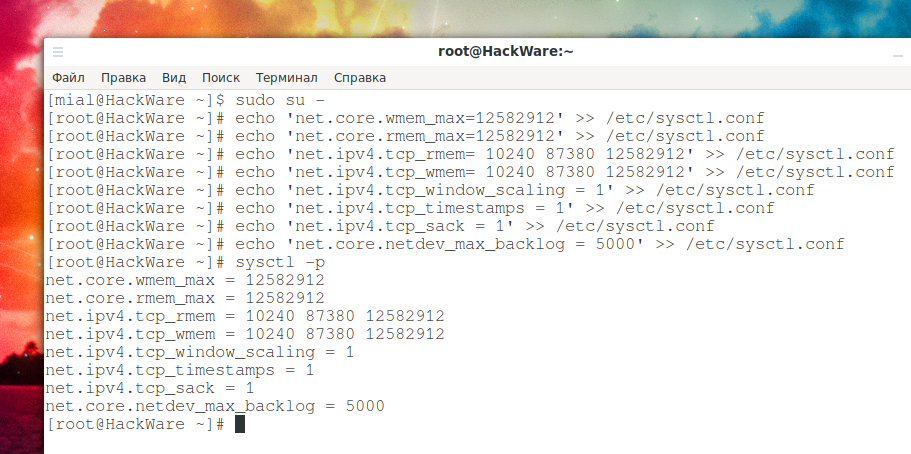
Установите максимальный размер буфера отправки (wmem) ОС и размер буфера приёма (rmem) равным 12 МБ для очередей по всем протоколам. Другими словами, установите объём памяти, который выделяется для каждого сокета TCP, когда он открывается или создаётся при передаче файлов:
sudo su - echo 'net.core.wmem_max=12582912' >> /etc/sysctl.conf echo 'net.core.rmem_max=12582912' >> /etc/sysctl.conf
Вам также необходимо установить минимальный размер, начальный размер и максимальный размер в байтах:
echo 'net.ipv4.tcp_rmem= 10240 87380 12582912' >> /etc/sysctl.conf echo 'net.ipv4.tcp_wmem= 10240 87380 12582912' >> /etc/sysctl.conf
Включите масштабирование окна, которое может быть опцией увеличения окна передачи:
echo 'net.ipv4.tcp_window_scaling = 1' >> /etc/sysctl.conf
Включите отметки времени, как определено в RFC1323:
echo 'net.ipv4.tcp_timestamps = 1' >> /etc/sysctl.conf
Включить выбор подтверждений:
echo 'net.ipv4.tcp_sack = 1' >> /etc/sysctl.conf
По умолчанию TCP сохраняет различные метрики соединения в кэше маршрута при закрытии соединения, так что соединения, установленные в ближайшем будущем, могут использовать их для установки начальных условий. Обычно это увеличивает общую производительность, но иногда может вызывать снижение производительности. Если установлено, TCP не будет кэшировать метрики при закрытии соединений.
echo 'net.ipv4.tcp_no_metrics_save = 1' >> /etc/sysctl.conf
Установите максимальное количество пакетов, помещаемых в очередь на стороне INPUT, когда интерфейс получает пакеты быстрее, чем ядро может их обработать.
echo 'net.core.netdev_max_backlog = 5000' >> /etc/sysctl.conf
Теперь перезагрузите изменения:
Используйте tcpdump для просмотра изменений для eth0: