NFS Client Tuning on Linux
In some of my previous posts, I spent some time attempting to squeeze out the best NFS performance as possible from OpenBSD. This time, I wanted to run a similar test, but on Linux and see if the same findings were applicable.
I found the results rather interesting, as they show that Linux is capable of faster transfer speeds than OpenBSD, with much less work. Of course, this doesn’t make me dislike OpenBSD any less (obviously), as the OS is still capable of fast transfers, and I am not building any supercomputers at my home.
I know there are plenty of articles out there which go into great detail on achieving the best possible NFS performance. However, most of the articles only highlighted possible settings to use, but none of them offered a way for anyone to test those settings. The script at the bottom of this article should enable admins to automate the process of finding the proper NFS values for their servers.
First off, I did some research and have tweaked my original NFS testing script used in earlier articles to do away with rsync, and switch to using dd with special flags to bypass the RAM cache Linux uses. This is done to test the raw transfer speeds, and not have results skewed by buffering.
Also, RHEL7/CentOS7 recommends to use TCP, and not UDP, as read here.
For this reason, I am only running my tests using TCP. Also, when I did do some testing using UDP on the CentOS server, I saw massive speed degradation, that was not seen when using TCP.
Also, the script has been modified to run read, as well as write tests.
Top 30 Read Results:
Direction Sync Protocol Mount Buffer Transfer Size Transfer Time Transfer Speed read sync tcp soft 131072 4096 36.5489 118MB/s read sync tcp soft 131072 2048 18.2744 118MB/s read sync tcp soft 131072 1024 9.13749 118MB/s read sync tcp hard 131072 4096 36.5475 118MB/s read sync tcp hard 131072 2048 18.2746 118MB/s read sync tcp hard 131072 1024 9.13775 118MB/s read async tcp soft 131072 4096 36.5473 118MB/s read async tcp soft 131072 2048 18.2741 118MB/s read async tcp soft 131072 1024 9.13767 118MB/s read async tcp hard 131072 4096 36.5479 118MB/s read async tcp hard 131072 2048 18.2747 118MB/s read async tcp hard 131072 1024 9.13783 118MB/s read sync tcp soft 65536 4096 36.6083 117MB/s read sync tcp soft 65536 2048 18.3038 117MB/s read sync tcp soft 65536 1024 9.15332 117MB/s read sync tcp soft 32768 4096 36.6747 117MB/s read sync tcp soft 32768 2048 18.3372 117MB/s read sync tcp soft 32768 1024 9.17016 117MB/s read sync tcp hard 65536 4096 36.6055 117MB/s read sync tcp hard 65536 2048 18.3032 117MB/s read sync tcp hard 65536 1024 9.15207 117MB/s read sync tcp hard 32768 4096 36.6751 117MB/s read sync tcp hard 32768 1024 9.16981 117MB/s read async tcp soft 65536 4096 36.6052 117MB/s read async tcp soft 65536 2048 18.3035 117MB/s read async tcp soft 65536 1024 9.15207 117MB/s read async tcp soft 32768 4096 36.6767 117MB/s read async tcp soft 32768 2048 18.3374 117MB/s read async tcp soft 32768 1024 9.16966 117MB/s read async tcp hard 65536 4096 36.6047 117MB/s Top 30 Write Results:
Direction Sync Protocol Mount Buffer Transfer Size Transfer Time Transfer Speed write sync tcp soft 65536 1024 12.7614 84.1MB/s write sync tcp soft 32768 4096 51.0877 84.1MB/s write sync tcp soft 32768 2048 25.5335 84.1MB/s write sync tcp soft 32768 1024 12.7988 83.9MB/s write sync tcp soft 131072 2048 25.6036 83.9MB/s write async tcp soft 32768 2048 25.5911 83.9MB/s write async tcp soft 32768 1024 12.8041 83.9MB/s write async tcp hard 65536 2048 25.5911 83.9MB/s write async tcp hard 32768 2048 25.5999 83.9MB/s write sync tcp hard 65536 2048 25.6387 83.8MB/s write async tcp soft 32768 4096 51.2749 83.8MB/s write async tcp hard 32768 4096 51.2585 83.8MB/s write sync tcp soft 65536 2048 25.6436 83.7MB/s write sync tcp hard 65536 4096 51.3207 83.7MB/s write async tcp hard 65536 1024 12.8344 83.7MB/s write async tcp hard 65536 4096 51.3744 83.6MB/s write sync tcp soft 65536 4096 51.4253 83.5MB/s write sync tcp hard 65536 1024 12.8609 83.5MB/s write sync tcp hard 32768 4096 51.4328 83.5MB/s write async tcp hard 32768 1024 12.8662 83.5MB/s write sync tcp hard 32768 1024 12.8715 83.4MB/s write sync tcp hard 131072 2048 25.7637 83.4MB/s write async tcp soft 131072 4096 51.5276 83.4MB/s write async tcp soft 65536 1024 12.8935 83.3MB/s write sync tcp hard 131072 1024 12.9163 83.1MB/s write async tcp soft 65536 2048 25.8834 83.0MB/s write async tcp hard 131072 1024 12.9441 83.0MB/s write async tcp soft 65536 4096 51.8221 82.9MB/s write async tcp soft 131072 1024 12.9866 82.7MB/s write async tcp hard 131072 2048 26.0415 82.5MB/s This go-around, I ran the results through Minitab, which was able to generate these plots for further analysis, and yes, synchronous is misspelled:
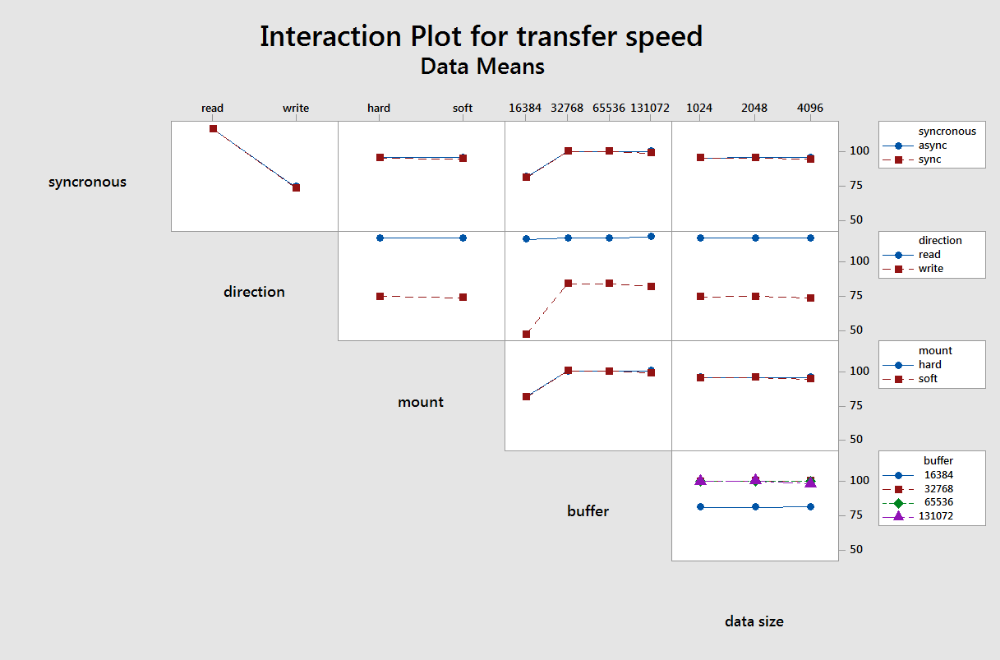
My interpretation of this plot is that Linux is overall very good at transferring data over NFSv3 with a majority of settings. As long as the buffer size was larger than 16384, the transfer speeds were pretty consistent for both reading and writing.
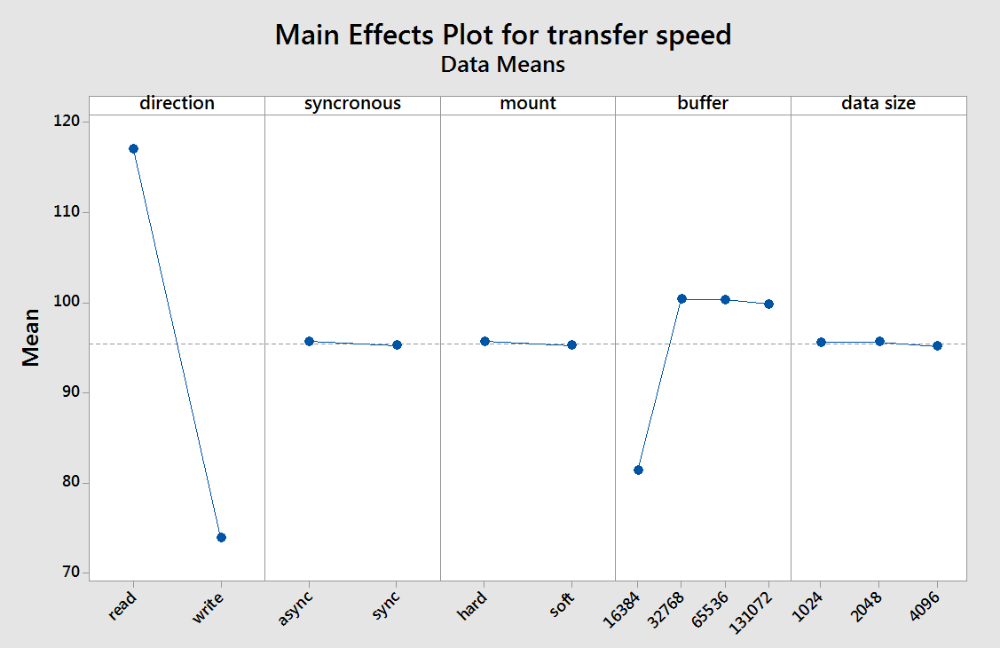
My comments for this plot echo what was said regarding the previous plot. A majority of settings have little affect on the speed on NFS. It does look here that async and hard settings yielded slightly higher results, but barely.
1. sync vs async
2. TCP vs UDP, ignoring since UDP sucks in my tests on linux
3. soft vs hard
3. r/w size: 16384 32768 65536 131072
Записки *NIX Админа
Столкнулся с небольшой производительностью nfs сервера, начал ковырять, и узнавать, что же можно улучшить?
Я уже рассматривал раньше работу NFS на FreeBSD, там же есть и базовая теория, как это работает.
Так что повторяться не буду.
Итак
Тюнинг сервера
Лучше использовать tcp, т.к. гарантирует доставку, даже при очень высокой нагрузке на сервер, правда несет за собой дополнительные накладные расходы в виде повышения нагрузки на CPU и уменьшения скорости передачи.
Количество процессов nfsd
Для Red Hat
#cat /etc/sysconfig/nfs . RPCNFSDCOUNT=32 . — число ставить приблизительно в расчёте 2 демона на одну ноду.
#cat /etc/conf.d/nfs . # Number of servers to be started up by default OPTS_RPC_NFSD="32" . Тюнинг клиента
Здесь перечислены некоторые опции, которые вы должны рассмотреть сразу, добавляя их в файл настроек.
Они управляют способом, которым клиент NFS отрабатывает прекращение работы сервера или отключение сети.
Одно из свойств NFS в том, что он может изящно обрабатывать эти неполадки, если вы правильно установите клиента.
Существует два различающихся режима обработки ошибок:
soft
NFS клиент будет сообщать об ошибке программе, которая пытается получить доступ к файлу расположенному на файловой системе, смонтированной через NFS.
Некоторые программы довольно хорошо обрабатыают такого рода ошибки, но большинство программ не делают это.
Я не рекомендую использование этой опции, она может привести к появлению испорченных файлов и потерянных данных. Вы особенно не должны использовать эту опцию для дисков, используемых для почты, если ваша почта что-то значит для вас.
hard
Программа осуществляющая доступ к файлу на смонтированной по NFS файловой системе просто приостановит выполнение при разрыве связи с сервером. Процесс не может быть прерван или убит до тех пор, пока вы явно не укажите опцию intr. Когда сервер NFS будет запущен заново, то программа продолжит безмятежно продолжать работу с прерванного места. Это скорее всего то, что вам нужно. Я рекомендую использовать опции hard,intr на всех файловых системах смонтированных через NFS.
Продолжая предыдущий пример, теперь в нашем файле fstab запись будет выглядеть так:
# device mountpoint fs-type options dump fsckorder . test:/mnt/test /mnt nfs rsize=1024,wsize=1024,hard,intr 0 0 . rsize и wsize
Обычно, если не заданы опции rsize и wsize, то NFS будет читать и писать блоками по 4096 или по 8192 байтов.
Некоторые комбинации ядер Linux и сетевых карт не могут обрабатывать такие большие блоки, и это может быть не оптимально.
Так что нам нужно поэкспериментировать и найти значения rsize и wsize, которые работают так быстр,о насколько это возможно.
На современных системах как правило оптимальными будут значения rsize=32768,wsize=32768. Т.е увеличиваем буфера чтения и записи , что уменьшает сетевые издержки
noatime — не обновлять обращения на чтение
defaults — равно rw, suid, dev, exec, auto, nouxer, async
В конечном итоге должно быть что-то типа этого
# device mountpoint fs-type options dump fsckorder . test:/mnt/test /mnt nfs defaults,nosuid,nolock,noatime,bg,vers=3,rsize=32768,wsize=32768,hard,intr 0 0 .