- How to remove the last character from a bash grep output
- 14 Answers 14
- Убрать символы файлов linux
- Команда tr и ее синтаксис
- 1) Заменить все строчные буквы на заглавные
- 2) Удаление символов с помощью tr
- 3) Удаление ила змена символов НЕ в наборе
- 4) Замена пробелов на табуляцию
- 5) Удаление повторений символов
- 6) Заменить символы из набора на перенос строки
- 7) Генерируем список уникальных слов из файла
- 8) Кодируем символы с помошью ROT
- Вывод
- How can I remove the last character of a file in unix?
- 9 Answers 9
How to remove the last character from a bash grep output
What I want to do is I want to remove the trailing «;» as well. How can i do that? I am a beginner to bash. Any thoughts or suggestions would be helpful.
For the problem at hand, it could have been solve with just grep: COMPANY_NAME=$(grep -Po ‘(?<=company_name=)"[^"]*"' file.txt)
14 Answers 14
This will remove the last character contained in your COMPANY_NAME var regardless if it is or not a semicolon:
echo "$COMPANY_NAME" | rev | cut -c 2- | rev COMPANY_NAME=`cat file.txt | grep "company_name" | cut -d '=' -f 2 | sed 's/;$//'` @Anony-Mousse Yes, I know there are at least two ways to avoid cat here. I left in the cat in order to avoid changing the command line from the question beyond what was actually necessary to make it work.
@Anony-Mousse Not really in all cases, simply grep without cat -v will hide invisible (e.g. malicious) characters, unix.stackexchange.com/questions/202198/…
foo="hello world" echo $ hello worl This just made my day because I was trying to make a quick and dirty list of websites we had TLS keys for. for L in `ls *key` ; do echo $
I’d use head —bytes -1 , or head -c-1 for short.
COMPANY_NAME=`cat file.txt | grep "company_name" | cut -d '=' -f 2 | head --bytes -1` head outputs only the beginning of a stream or file. Typically it counts lines, but it can be made to count characters/bytes instead. head —bytes 10 will output the first ten characters, but head —bytes -10 will output everything except the last ten.
NB: you may have issues if the final character is multi-byte, but a semi-colon isn’t
I’d recommend this solution over sed or cut because
- It’s exactly what head was designed to do, thus less command-line options and an easier-to-read command
- It saves you having to think about regular expressions, which are cool/powerful but often overkill
- It saves your machine having to think about regular expressions, so will be imperceptibly faster
I’ve tested the other suggested solution and this seems as the best one (and a simple one!) for my use case. Thanks!
I believe the cleanest way to strip a single character from a string with bash is:
but I haven’t been able to embed the grep piece within the curly braces, so your particular task becomes a two-liner:
COMPANY_NAME=$(grep "company_name" file.txt); COMPANY_NAME=$
This will strip any character, semicolon or not, but can get rid of the semicolon specifically, too. To remove ALL semicolons, wherever they may fall:
To remove only a semicolon at the end:
Or, to remove multiple semicolons from the end:
For great detail and more on this approach, The Linux Documentation Project covers a lot of ground at http://tldp.org/LDP/abs/html/string-manipulation.html
Using sed , if you don’t know what the last character actually is:
$ grep company_name file.txt | cut -d '=' -f2 | sed 's/.$//' "Abc Inc" Don’t abuse cat s. Did you know that grep can read files, too?
The canonical approach would be this:
grep "company_name" file.txt | cut -d '=' -f 2 | sed -e 's/;$//' the smarter approach would use a single perl or awk statement, which can do filter and different transformations at once. For example something like this:
COMPANY_NAME=$( perl -ne '/company_name=(.*);/ && print $1' file.txt ) don’t have to chain so many tools. Just one awk command does the job
COMPANY_NAME=$(awk -F"=" '/company_name/' file.txt) you can strip the beginnings and ends of a string by N characters using this bash construct, as someone said already
$ fred=abcdefg.rpm $ echo $ bcdefg HOWEVER, this is not supported in older versions of bash.. as I discovered just now writing a script for a Red hat EL6 install process. This is the sole reason for posting here. A hacky way to achieve this is to use sed with extended regex like this:
$ fred=abcdefg.rpm $ echo $fred | sed -re 's/^.(.*). $/\1/g' bcdefg In Bash using only one external utility:
IFS='= ' read -r discard COMPANY_NAME Assuming the quotation marks are actually part of the output, couldn’t you just use the -o switch to return everything between the quote marks?
COMPANY_NAME="\"ABC Inc\";" | echo $COMPANY_NAME | grep -o "\"*.*\"" Some refinements to answer above. To remove more than one char you add multiple question marks. For example, to remove last two chars from variable $SRC_IP_MSG, you can use:
cat file.txt | grep "company_name" | cut -d '=' -f 2 | cut -d ';' -f 1 as linus torvalds says, one of the most difficult things to find in a programmer is «good taste», which is difficult to define. but since you would benefit from it i will do so in this case: because of the initial cat every element of the pipeline that does real work operates on its standard input and its standard output. the benefit is that you can replace the cat with some other pipeline that produces output similar to file.txt and you don’t have to change even a single character in the functional part of the pipeline. this allows drop-in pipeline reusability.
@Det fyb above (forgot to tag you, just like somebody might forget to remove the input argument when composing pipelines and wonder why the output isn’t as expected)
@randomstring, while I don’t really see this as you giving me a «piece of your mind» (I lol’d by the way) it’s rather extreme reusability to preserve the use of cat just to give you the possibility of changing it to something else later on. The only thing I could see it worth for is simplicity. If a user types grep pattern file , then I’m pretty damn sure he understands it’s that first part which reads the file and where he starts piping it.
Убрать символы файлов linux

Команда tr (translate) используется в Linux в основном для преобразования и удаления символов. Она часто находит применение в скриптах обработки текста. Ее можно использовать для преобразования верхнего регистра в нижний, сжатия повторяющихся символов и удаления символов.
Команда tr требует два набора символов для преобразований, а также может использоваться с другими командами, использующими каналы (пайпы) Unix для расширенных преобразований.
В этой статье мы узнаем, как использовать команду tr в операционных системах Linux и рассмотрим некоторые примеры.
Команда tr и ее синтаксис
Ниже приведен синтаксис команды tr. Требуется, как минимум, два набора символов и опции.
SET1 и SET2 это группы символов. are a group of characters. Необходимо перечислить необходимые символы или указать последовательность.
\NNN -> восмеричные (OCT) символы NNN (1 до 3 цифр)
\\ -> обратный слеш (экранированный)
\t -> табуляция (horizontal tab)
[:cntrl:] -> все управляющие символы (control)
[:lower:] -> все буквы в нижнем регистре (строчные)
[:upper:] -> все буквы в верхнем регистре (заглавные)
Примеры использования команды tr:
echo "something to translate" | tr "SET1" "SET2"
-c , -C , —complement -> удалить все символы, кроме тех, что в первом наборе
-d , —delete -> удалить символы из первого набора
-s , —squeeze-repeats -> заменять набор символов, которые повторяются, из указанных в последнем наборе знаков
1) Заменить все строчные буквы на заглавные
Мы можем использовать tr для преобразования нижнего регистра в верхний или наоборот.
Просто используем наборы [:lower:] [:upper:] или «a-z» «A-Z» для замены всех символов.
Вот пример, как преобразовать в Linux с помощью команды tr все строчные буквы в заглавные:
$ echo "hello linux world" | tr [:lower:] [:upper:] HELLO LINUX WORLD
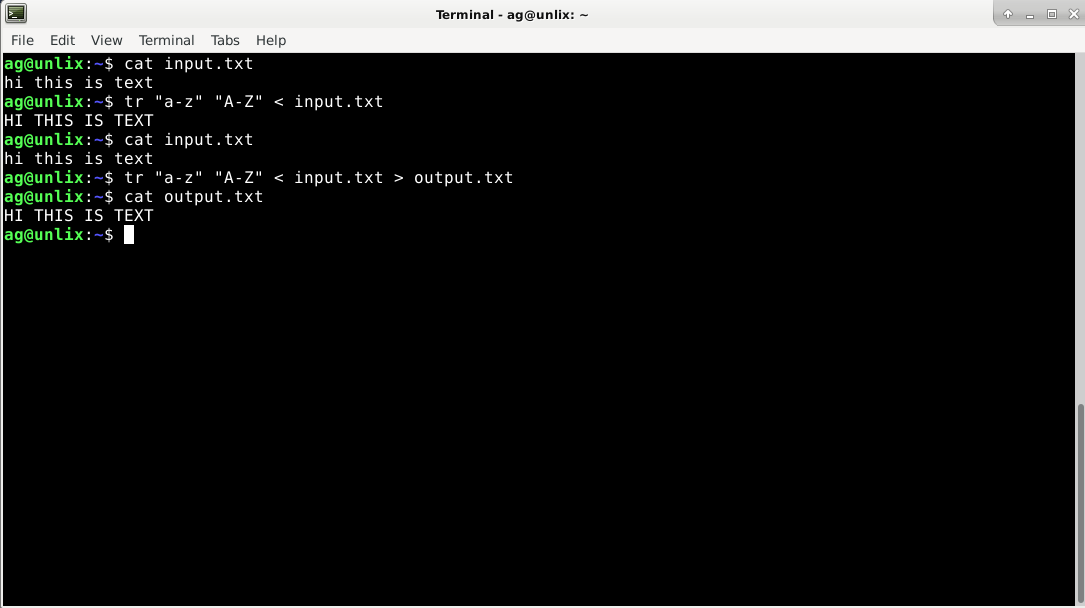
А сейчас сделаем замену из файла input.txt
$ cat input.txt hi this is text $ tr "a-z" "A-Z" < input.txt HI THIS IS TEXT $ cat input.txt hi this is text
Как мы видим, в файле ничего не изменилось, осталось все строчными буквами. Чтобы изменения были в файле, на необходимо перевести вывод в новый файл. Например, в output.txt
$ tr "a-z" "A-Z" < input.txt >output.txt $ cat output.txt HI THIS IS TEXT
Кстати, в команде sed есть опция y которая делает то же самое (sed ‘y/SET1/SET2’)
2) Удаление символов с помощью tr
Опция -d используется для удаления всех символов, которые указаны в наборе символов.
Следующая команда удалит все символы из этого набора ‘aei’.
$ echo "hi this is example text" | tr -d "aei" h ths s xmpl txt
Следующая команда удалит все цифры в тексте. Будем использовать набор [:digit:] , чтобы определить все цифры.
$ echo "1 please 2 remove 3 all 4 digits" | tr -d [:digit:] please remove all digits
А вот пример команд, которыми можно удалить переносы на новые строки
3) Удаление ила змена символов НЕ в наборе
С помощью параметра -c Вы можете сказать tr заменить все символы, которые Вы не указали в наборе. Приведем пример.
$ echo "a1b2c3d4" | tr -c 'abcd' '0' a0b0c0d0
А вот пример удаления, просто укажем опцию -d и только один набор (символы которого удалять НЕ надо, а остальные удалить)
$ echo "12345 abcd 67890 efgh" | tr -cd [:digit:] 1234567890

4) Замена пробелов на табуляцию
Для указания пробелов используем – [:space:] , а для табуляции – \t.
$ echo "1 2 3 4" | tr [:space:] '\t' 1 2 3 4
5) Удаление повторений символов
Это делает параметр -s . Рассмотрим пример удаления повторов знаков.
$ echo "many spaces here" | tr -s " " many spaces here
Или заменим повторения на символ решетки
$ echo "many spaces here" | tr -s '[:space:]' '#' many#spaces#here
6) Заменить символы из набора на перенос строки
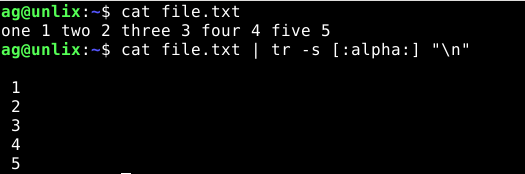
Сделаем так, чтобы все буквы были заменены на перенос новой строки:
$ cat file.txt one 1 two 2 three 3 four 4 five 5 $ cat file.txt | tr -s "[:alpha:]" "\n" 1 2 3 4 5
7) Генерируем список уникальных слов из файла
Это иногда очень полезная команда, когда необходимо определить количество повторений и вывести уникальные слова из файла:
$ cat file.txt word1 word1 word2 word3 word4 word4 $ cat file.txt | tr -cs "[:alnum:]" "\n" | sort | uniq -c | sort -rn 2 word4 2 word1 1 word3 1 word2
8) Кодируем символы с помошью ROT
ROT (Caesar Cipher) – это тип криптографии, в котором кодирование выполняется путем перемещения букв в алфавите к его следующей букве.
Давайте проверим, как использовать tr для шифрования.
В следующем примере каждый символ в первом наборе будет заменен соответствующим символом во втором наборе.
Первый набор [a-z] (это значит abcdefghijklmnopqrstuvwxyz). Второй набор [n-za-m] (который содержит pqrstuvwxyzabcdefghijklmn).
Простая команда для демонстрации вышеуказанной теории:
Полезно при шифровании электронных адресов:
$ echo 'cryptography@example.com' | tr 'A-Za-z' 'N-ZA-Mn-za-m pelcgbtencul@rknzcyr.pbz
Вывод
tr – это очень мощная команда линукс при использовании пайпов Unix и очень часто используется в скриптах. Дополнительную информацию об этой утилите всегда можно найти в man.
Если у Вас есть какие-либо дополнения, не стесняйтесь пишите в комментариях.
How can I remove the last character of a file in unix?
How can I remove only the last character (the e, not the newline or null) of the file without making the text file invalid?
Listing a bunch of garbage sed and awk commands that strip the last character off of every line didn't feel terribly constructive. Heh, knew I was going to get dinged for that one. Still, couldn't bring myself to leave in the sentence "I tried a bunch of sed and awk, but could only strip out every line's last char in a variety of ways".
9 Answers 9
A simpler approach (outputs to stdout, doesn't update the input file):
- $ is a Sed address that matches the last input line only, thus causing the following function call ( s/.$// ) to be executed on the last line only.
- s/.$// replaces the last character on the (in this case last) line with an empty string; i.e., effectively removes the last char. (before the newline) on the line.
. matches any character on the line, and following it with $ anchors the match to the end of the line; note how the use of $ in this regular expression is conceptually related, but technically distinct from the previous use of $ as a Sed address. - Example with stdin input (assumes Bash, Ksh, or Zsh):
To update the input file too (do not use if the input file is a symlink):
- On macOS, you'd have to use -i '' instead of just -i ; for an overview of the pitfalls associated with -i , see the bottom half of this answer.
- If you need to process very large input files and/or performance / disk usage are a concern and you're using GNU utilities (Linux), see ImHere's helpful answer.
Removes one (-1) character from the end of the same file. Exactly as a >> will append to the same file.
The problem with this approach is that it doesn't retain a trailing newline if it existed.
if [ -n "$(tail -c1 file)" ] # if the file has not a trailing new line. then truncate -s-1 file # remove one char as the question request. else truncate -s-2 file # remove the last two characters echo "" >> file # add the trailing new line back fi This works because tail takes the last byte (not char).
It takes almost no time even with big files.
Why not sed
The problem with a sed solution like sed '$ s/.$//' file is that it reads the whole file first (taking a long time with large files), then you need a temporary file (of the same size as the original):
sed '$ s/.$//' file > tempfile rm file; mv tempfile file And then move the tempfile to replace the file.