- Команда awk – примеры использования в Linux и Unix
- Что это за команда awk?
- Базовый синтаксис awk
- Создание образца файла
- Вывод всего содержимого файла
- Вывод конкретных столбцов
- Вывод конкретных строк столбца
- Вывод строк с заданным шаблоном
- Использование регулярных выражений
- Использование операторов сравнения
- Заключение
- Использование awk в Linux
- Синтаксис команды awk
- Использование awk в Linux
Команда awk – примеры использования в Linux и Unix

В этом базовом руководстве вы узнаете самые основы команды awk , а также увидите некоторые способы её использования при работе с текстом, включая вывод содержимого файла, а также его конкретных столбцов, строк и слов по указанным критериям. Приступим!
Что это за команда awk?
AWK – это скриптовый язык, который полезен при работе в командной строке и широко применяется для обработки текста.
При использовании awk вы можете выбирать данные – один или более отдельных фрагментов текста – на основе заданного критерия. Например, с помощью awk можно выполнять поиск конкретного слова или шаблона во фрагменте текста, а также выбирать определённую строку/столбец в файле.
Базовый синтаксис awk
Простейшая форма команды awk подразумевает описание основного действия в одинарных кавычках и фигурных скобках с указанием после него целевого файла.
Когда вам нужно найти текст, соответствующий конкретному шаблону, или же конкретное слово в тексте, команда принимает следующий вид:
awk '/regex pattern/' your_file_name.txtСоздание образца файла
Для создания файла в командной строке используется команда touch . Например: touch filename.txt , где filename – это произвольное имя файла.
Затем можно с помощью команды open ( open filename.txt ) запустить обработчик текста вроде TextEdit, который позволит внести в файл нужное содержимое.
Предположим, у вас есть текстовый файл information.txt, содержащий данные, разделённые по столбцам.
Выглядеть этот файл может так:
firstName lastName age city ID Thomas Shelby 30 Rio 400 Omega Night 45 Ontario 600 Wood Tinker 54 Lisbon N/A Giorgos Georgiou 35 London 300 Timmy Turner 32 Berlin N/AВ приведённом примере мы видим по одному столбцу для
firstName , lastName , age , city и ID .
В любой момент можно просмотреть вывод содержимого вашего файла, выполнив cat text_file , где text_file представляет имя файла.
Вывод всего содержимого файла
Для вывода всего содержимого файла в качестве действия в фигурных скобках нужно указать print $0 .
Сработает эта команда аналогично ранее упомянутой cat .
firstName lastName age city ID Thomas Shelby 30 Rio 400 Omega Night 45 Ontario 600 Wood Tinker 54 Lisbon N/A Giorgos Georgiou 35 London 300 Timmy Turner 32 Berlin N/AЕсли захотите добавить нумерацию строк, то нужно будет дополнить действие переменной NR :
1 firstName lastName age city ID 2 3 Thomas Shelby 30 Rio 400 4 Omega Night 45 Ontario 600 5 Wood Tinker 54 Lisbon N/A 6 Giorgos Georgiou 35 London 300 7 Timmy Turner 32 Berlin N/AВывод конкретных столбцов
При использовании awk можно указывать для вывода конкретные столбцы.
Вывод первого производится следующей командой:
Thomas Omega Wood Giorgos TimmyЗдесь $1 означает первое поле, то есть в данном случае первый столбец.
Для вывода второго столбца используется $2 :
lastName Shelby Night Tinker Georgiou TurnerПо умолчанию начало и конец каждого столбца awk определяет по пробелу.
Для вывода большего числа столбцов, например, первого и четвёртого, нужно выполнить:
firstName city Thomas Rio Omega Ontario Wood Lisbon Giorgos London Timmy BerlinЗдесь $1 представляет первое поле ввода (первый столбец), а $4 четвёртое. При этом они отделяются запятой, чтобы вывод разделялся пробелом и был более читаемым.
Для вывода последнего поля (последнего столбца) также можно использовать команду $NF , представляющую последнее поле записи:
Вывод конкретных строк столбца
Также можно указывать для вывода строку определённого столбца:
awk '' information.txt | head -1Разделим эту команду на две части. Сначала awk » information.txt выводит первый столбец. Затем её результат (который мы видели выше) с помощью символа | передаётся на обработку команде head , где аргумент -1 указывает на выбор первой строки столбца.
Для вывода двух строк команда будет такой:
awk '' information.txt | head -2Вывод строк с заданным шаблоном
Вы можете выводить строку, начинающуюся с заданной буквы. Например:
Omega Night 45 Ontario 600Эта команда выбирает все строки с текстом, начинающимся на O .
Действие команды начинается с символа ^ , который указывает на начало строки. После этого прописывается буква, с которой нужная вам строка должна начинаться.
По аналогичному принципу можно выводить строку, завершающуюся конкретным шаблоном:
Thomas Shelby 30 Rio 400 Omega Night 45 Ontario 600 Giorgos Georgiou 35 London 300Эта команда выводит строки, оканчивающиеся на 0 – здесь с помощью символа $ мы указываем, как должна заканчиваться нужная строка.
При этом её можно несколько изменить:
Символ ! используется в качестве приставки «НЕ», а значит, в этом случае будут выбраны строки, которые не оканчиваются на 0 .
firstName lastName age city ID Wood Tinker 54 Lisbon N/A Timmy Turner 32 Berlin N/A Использование регулярных выражений
Для вывода слов, содержащих определённые буквы, а также слов, соответствующих указанному шаблону, мы снова используем прямые слэши.
К примеру, если нас интересуют слова, содержащие io , мы пишем:
Thomas Shelby 30 Rio 400 Omega Night 45 Ontario 600 Giorgos Georgiou 35 London 300Мы получили строки, в которых содержатся слова, содержащие io .
Теперь предположим, что в файле есть дополнительный столбец department :
firstName lastName age city ID department Thomas Shelby 30 Rio 400 IT Omega Night 45 Ontario 600 Design Wood Tinker 54 Lisbon N/A IT Giorgos Georgiou 35 London 300 Data Timmy Turner 32 Berlin N/A EngineeringДля поиска всей информации о людях, работающих в IT , нужно указать искомую строку между // :
Thomas Shelby 30 Rio 400 IT Wood Tinker 54 Lisbon N/A ITА что, если мы хотим увидеть только имена и фамилии сотрудников из IT ?
Тогда можно указать столбец так:
Thomas Shelby Wood TinkerВ этом случае отобразятся только первый и второй столбцы строк, содержащих IT .
При поиске слов, содержащих конкретный шаблон, бывают случаи, когда требуется использовать экранирующий символ:
Wood Tinker 54 Lisbon N/A Timmy Turner 32 Berlin N/AЯ хотела найти строки, оканчивающиеся на N/A . Поэтому при указании критериев поиска в ‘ // ‘ , как это показывалось выше, мне пришлось использовать между N/A символ перехода \ . В противном случае возникла бы ошибка.
Использование операторов сравнения
Если вы, предположим, захотите найти всю информацию о сотрудниках в возрасте до 40 лет, то нужно будет использовать оператор сравнения < так:
Thomas Shelby 30 Rio 400 Giorgos Georgiou 35 London 300 Timmy Turner 32 Berlin N/AВ выводе представлена информация о людях моложе 40.
Заключение
Вот и всё. Теперь у вас есть необходимая основа для начала работы с awk и управления текстовыми данными.
Благодарю за чтение и успехов вам в обучении!

Использование awk в Linux
Текст это сердце Unix. Философия «все есть файл» полностью пронизывает всю систему и разработанные для нее инструменты. Вот почему работа с текстом является одним из обязательных навыков не только системного администратора, но и обычного пользователя Linux, который хочет поглубже разобраться в этой операционной системе.
Команда awk — один из самых мощных инструментов для обработки и фильтрации текста, доступный даже для людей никак не связных с программированием. Это не просто утилита, а целый язык разработанный для обработки и извлечения данных. В этой статье мы разберемся как пользоваться awk.
Синтаксис команды awk
Сначала надо понять как работает утилита. Она читает документ по одной строке за раз, выполняет указанные вами действия и выводит результат на стандартный вывод. Одна из самых частых задач, для которых используется awk — это выборка одной из колонок. Все параметры awk находятся в кавычках, а действие, которое надо выполнить — в фигурных скобках. Вот основной её синтаксис:
$ awk опции ‘ условие < действие >‘
$ awk опции ‘ условие < действие >условие < действие >‘
С помощью действия можно выполнять преобразования с обрабатываемой строкой. Об этом мы поговорим позже, а сейчас давайте рассмотрим опции утилиты:
- -F, —field-separator — разделитель полей, используется для разбиения текста на колонки;
- -f, —file — прочитать данные не из стандартного вывода, а из файла;
- -v, —assign — присвоить значение переменной, например foo=bar;
- -b, —characters-as-bytes — считать все символы однобайтовыми;
- -d, —dump-variables — вывести значения всех переменных awk по умолчанию;
- -D, —debug — режим отладки, позволяет вводить команды интерактивно с клавиатуры;
- -e, —source — выполнить указанный код на языке awk;
- -o, —pretty-print — вывести результат работы программы в файл;
- -V, —version — вывести версию утилиты.
Это далеко не все опции awk, однако их вам будет достаточно на первое время. Теперь перечислим несколько функций-действий , которые вы можете использовать:
- print(строка) — вывод чего либо в стандартный поток вывода;
- printf(строка) — форматированный вывод в стандартный поток вывода;
- system(команда) — выполняет команду в системе;
- length(строка) — возвращает длину строки;
- substr(строка, старт, количество) — обрезает строку и возвращает результат;
- tolower(строка) — переводит строку в нижний регистр;
- toupper(строка) — переводить строку в верхний регистр.
Функций намного больше, но чтобы не загромождать статью я привел только те, которые мы будем использовать сегодня, а также ещё несколько для чтобы вы могли оценить масштаб возможностей утилиты.
В функциях-действиях можно использовать различные переменные и операторы, вот несколько из них:
- FNR — номер обрабатываемой строки в файле;
- FS — разделитель полей;
- NF — количество колонок в данной строке;
- NR — общее количество строк в обрабатываемом тексте;
- RS — разделитель строк, по умолчанию символ новой строки;
- $ — ссылка на колонку по номеру.
Кроме этих переменных, есть и другие, а также можно объявлять свои.
Условие позволяет обрабатывать только те строки, в которых содержатся нужные нам данные, его можно использовать в качестве фильтра, как grep. А ещё условие позволяет выполнять определенные блоки кода awk для начала и конца файла, для этого вместо регулярного выражения используйте директивы BEGIN (начало) и END (конец). Там ещё есть очень много всего, но на сегодня пожалуй достаточно. Теперь давайте перейдем к примерам.
Использование awk в Linux
Простейшая и часто востребованная задача — выборка полей из стандартного вывода. Вы не найдете более подходящего инструмента для решения этой задачи, чем awk. По умолчанию awk разделяет поля пробелами. Если вы хотите напечатать первое поле, вам нужно просто использовать функцию print и передать ей параметр $1, если функция одна, то скобки можно опустить:
echo ‘one two three four’ | awk »
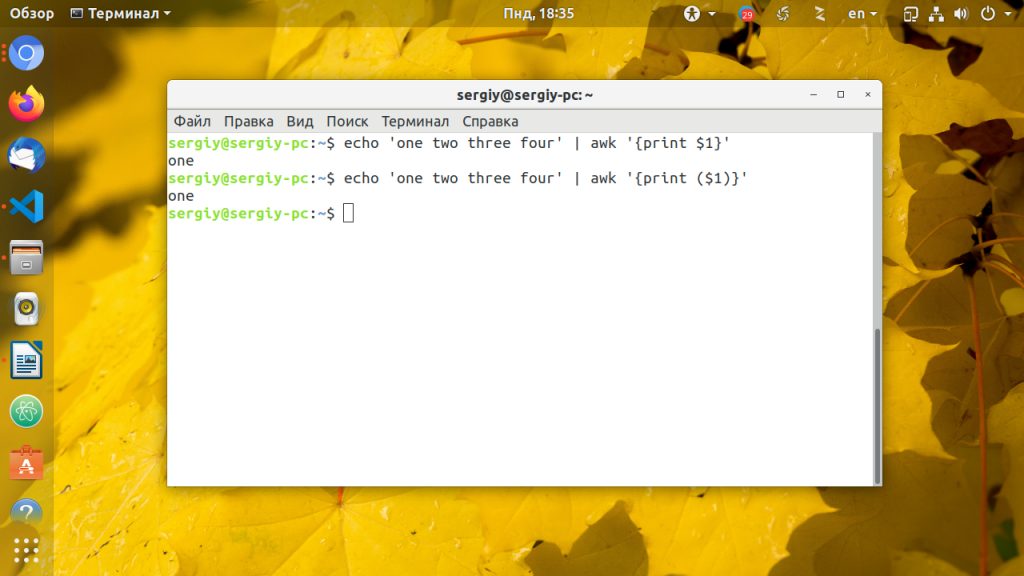
Да, использование фигурных скобок немного непривычно, но это только в первое время. Вы уже догадались как напечатать второе, третье, четвертое, или другие поля? Правильно это $2, $3, $4 соответственно.
echo ‘one two three four’ | awk »
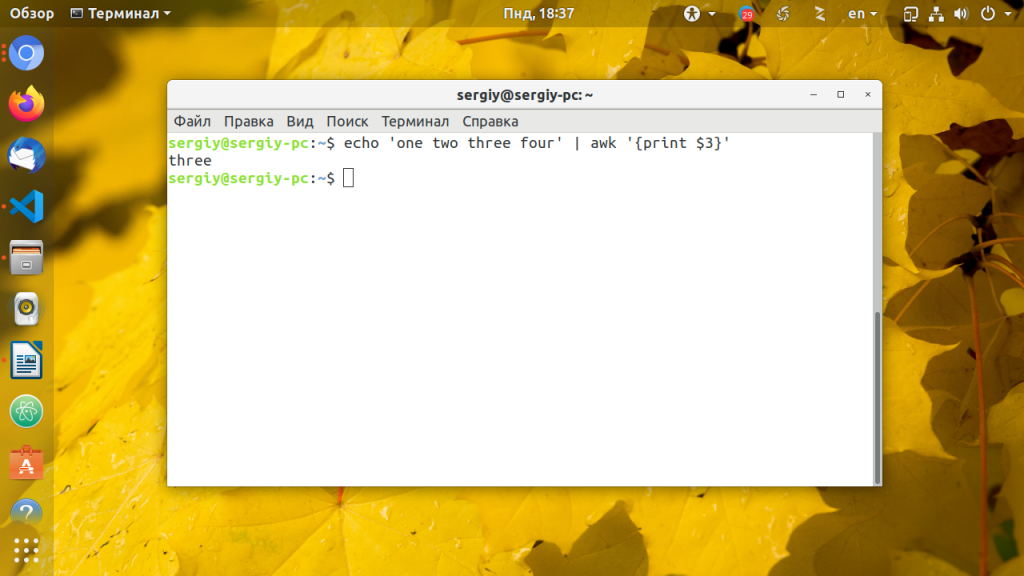
Иногда необходимо представить данные в определенном формате, например, выбрать несколько слов. AWK легко справляется с группировкой нескольких полей и даже позволяет включать статические данные:
echo ‘one two three four’ | awk »
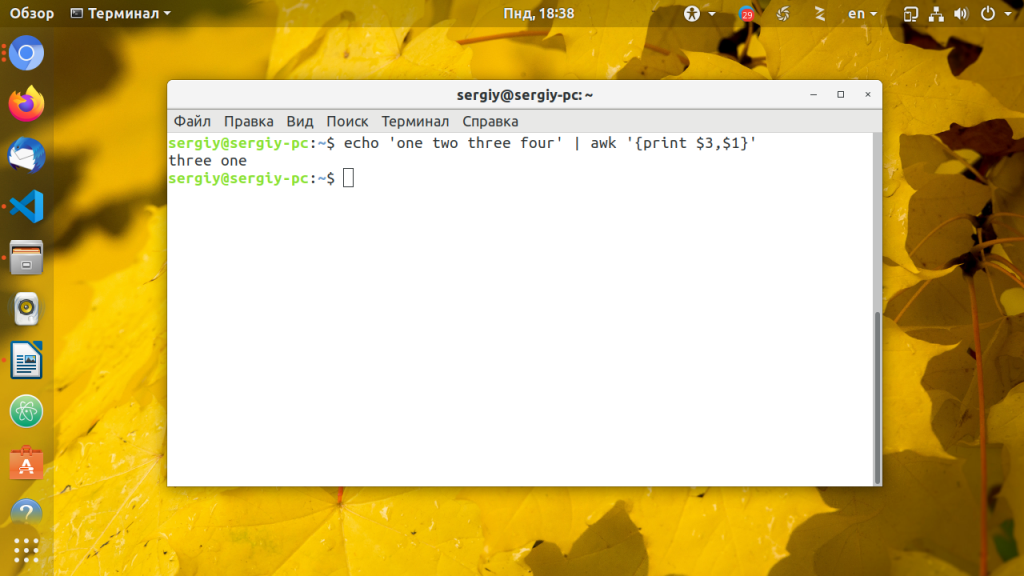
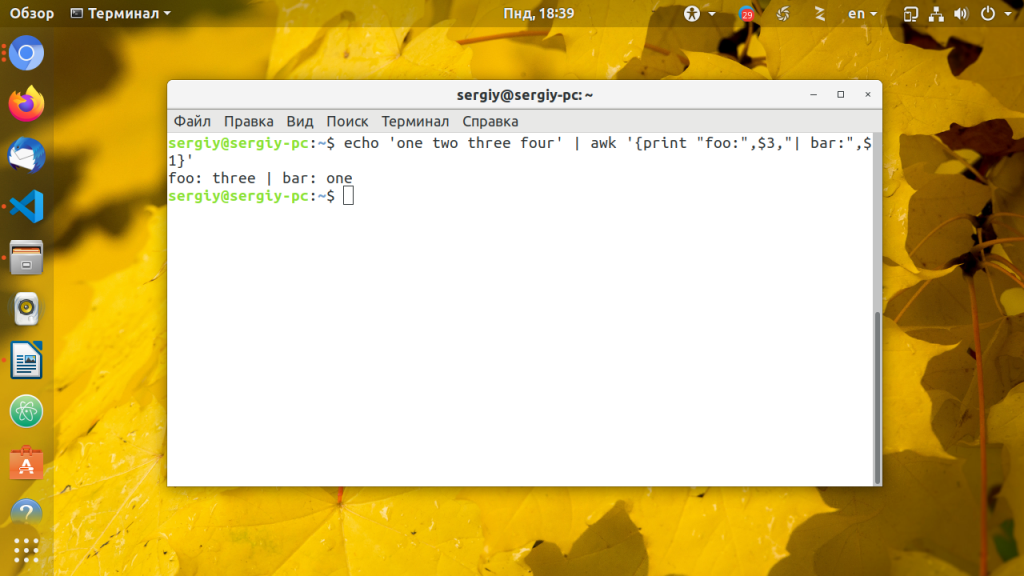
Если поля разделены не пробелами, а другим разделителем, просто укажите в параметре -F нужный разделитель в кавычках, например «:» :
echo ‘one mississippi:two mississippi:three mississippi:four mississippi’ | awk -F»:» »
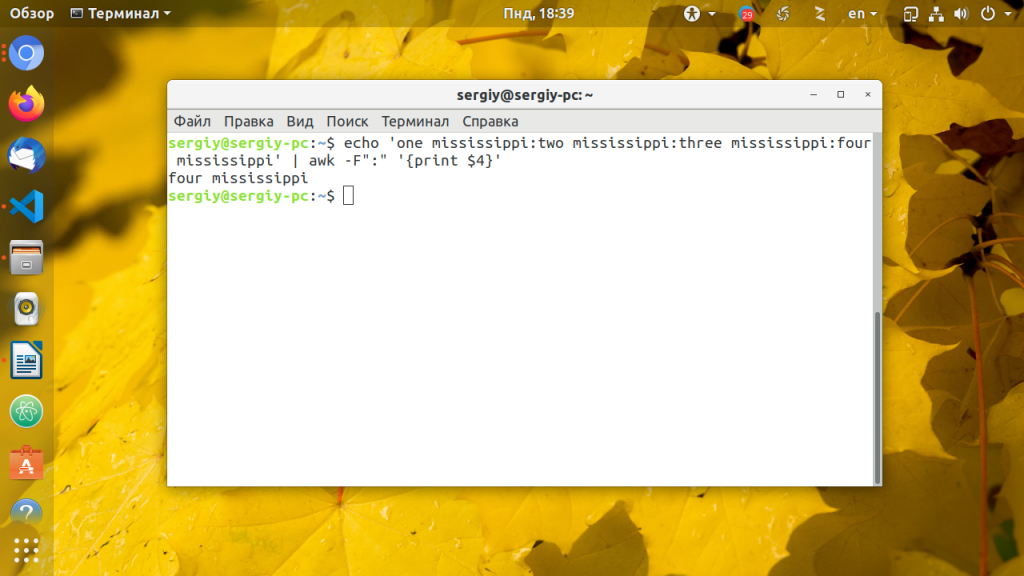
Но разделитель не обязательно заключать в кавычки. Следующий вывод аналогичен предыдущему:
echo ‘one mississippi:two mississippi:three mississippi:four mississippi’ | awk -F: »
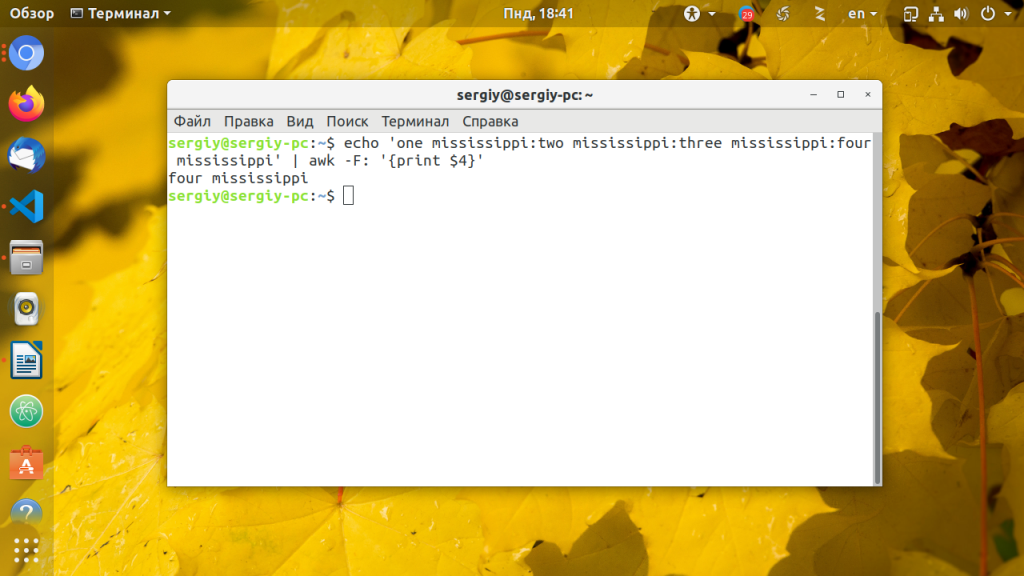
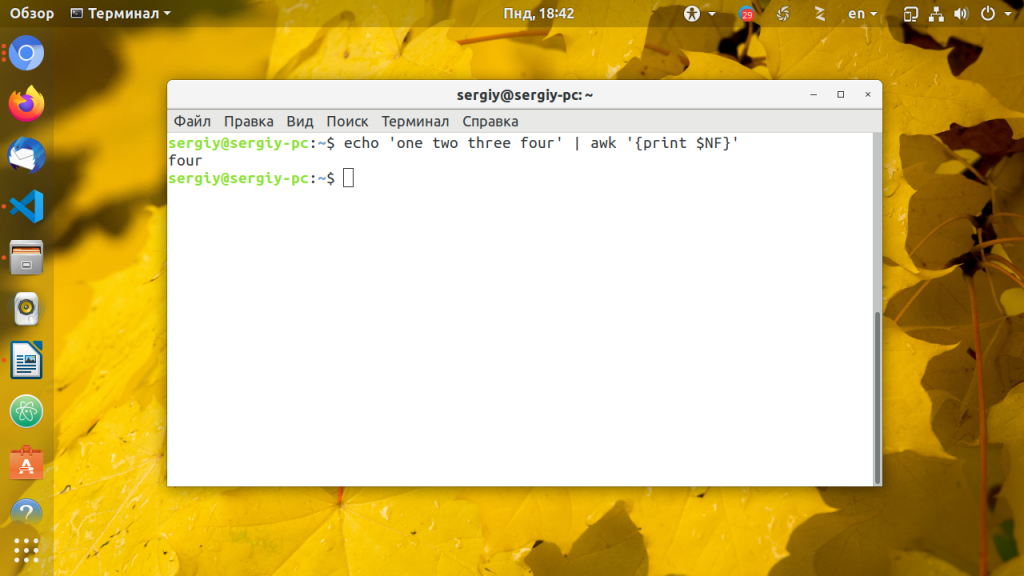
Иногда нужно обработать данные с неизвестным количеством полей. Если вам нужно выбрать последнее поле можно воспользоваться переменной $NF. Вот так вы можете вывести последнее поле:
echo ‘one two three four’ | awk »
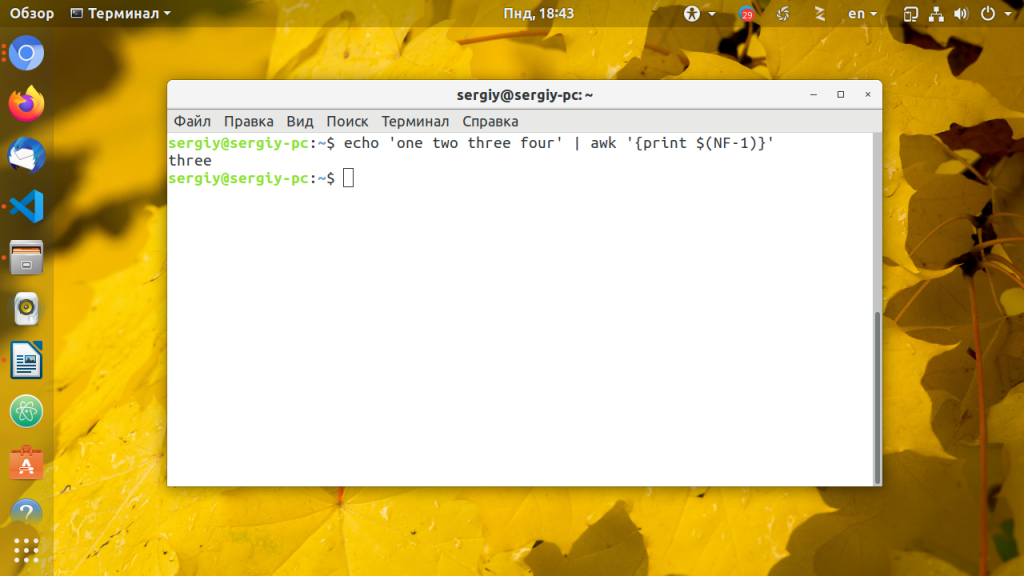
Также вы можете использовать переменную $NF для получения предпоследнего поля:
echo ‘one two three four’ | awk »
echo ‘one two three four five’ | awk »
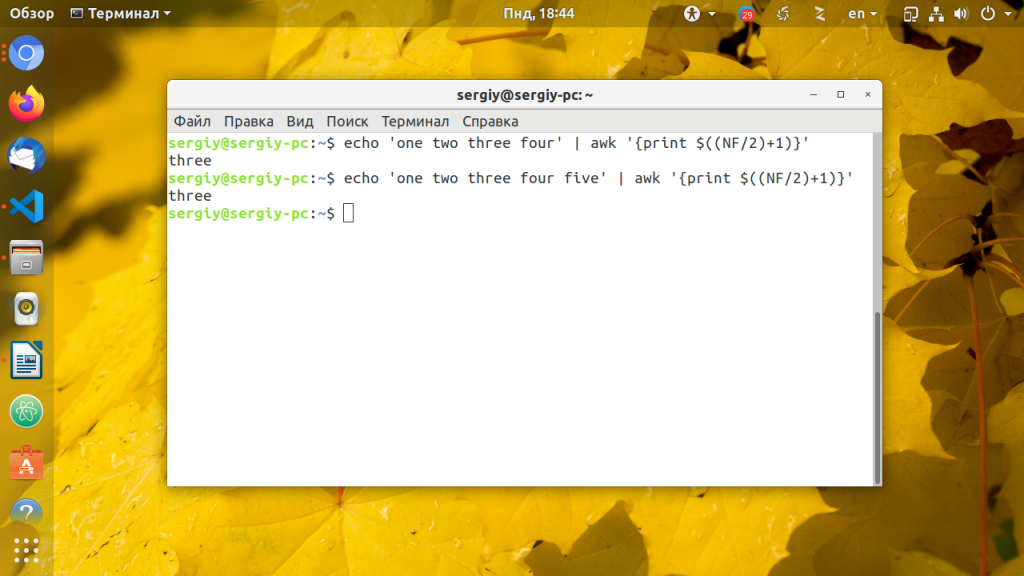
Все это можно сделать с помощью таких утилит как sed, cut и grep но это будет намного сложнее.
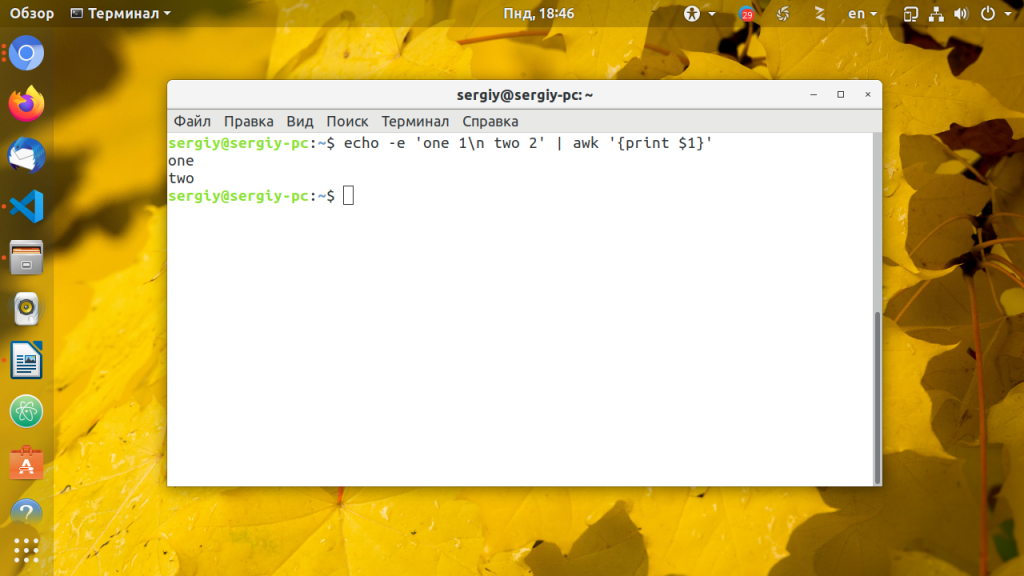
Как я рассказывал выше, awk обрабатывает одну строку за раз, вот этому подтверждение:
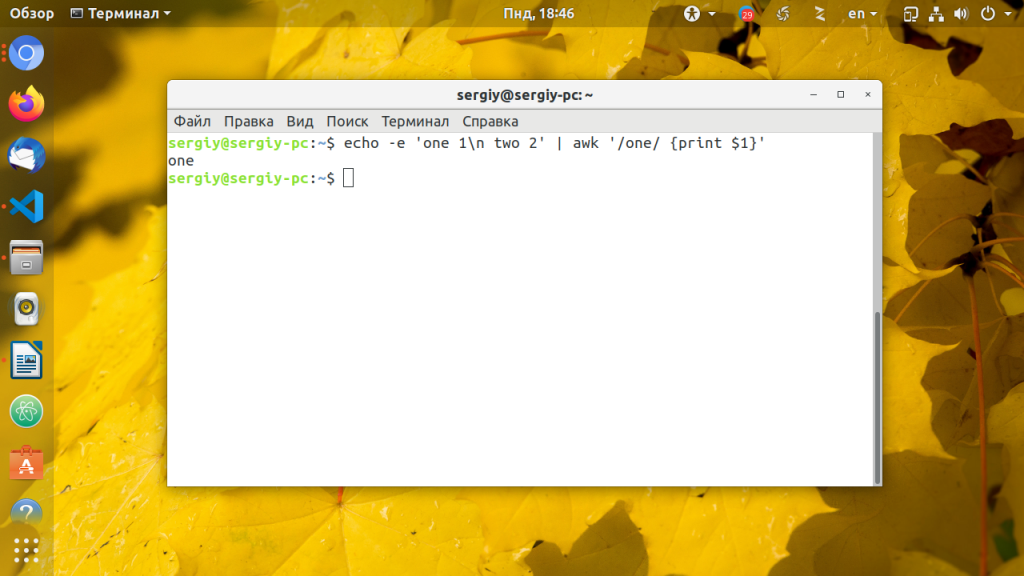
А вот пример фильтрации с помощью условия, выведем только строку, в которой содержится текст one:
echo -e ‘one 1\n two 2’ | awk ‘/one/ ‘
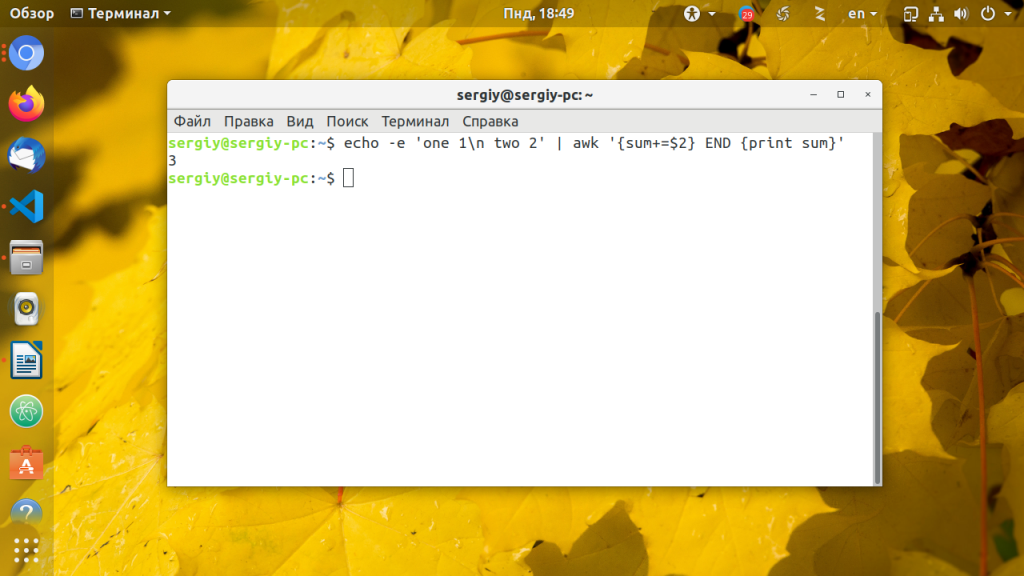
А вот пример использования операций с переменными:
echo -e ‘one 1\n two 2’ | awk ‘ END ‘
Это означает что мы должны выполнять следующий блок кода для каждой строки. Это можно использовать, например, для подсчета количества переданных данных по запросам из журнала веб-сервера.
Представьте себе, у нас есть журнал доступа, который выглядит так:
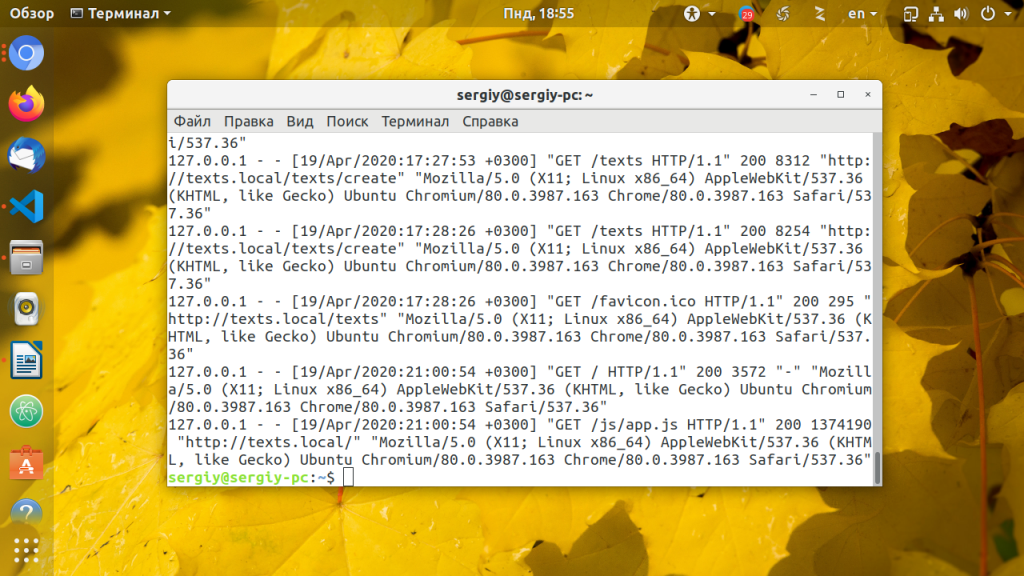
Мы можем подсчитать, что количество переданных байт, это десятое поле. Дальше идёт User-Agent пользователя и он нам не интересен:
cat /var/log/apache2/access.log | awk »
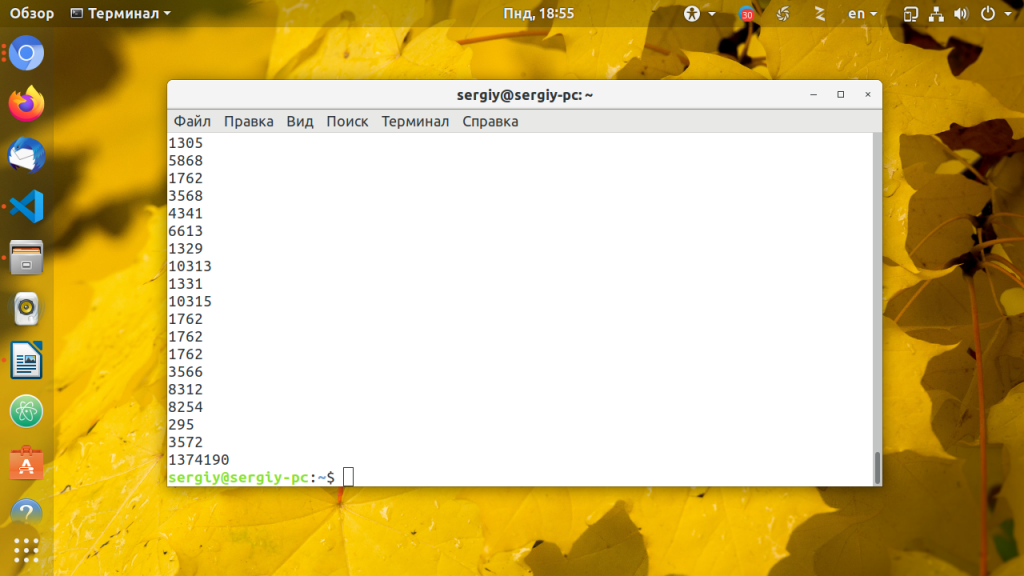
Вот так можно подсчитать количество байт:
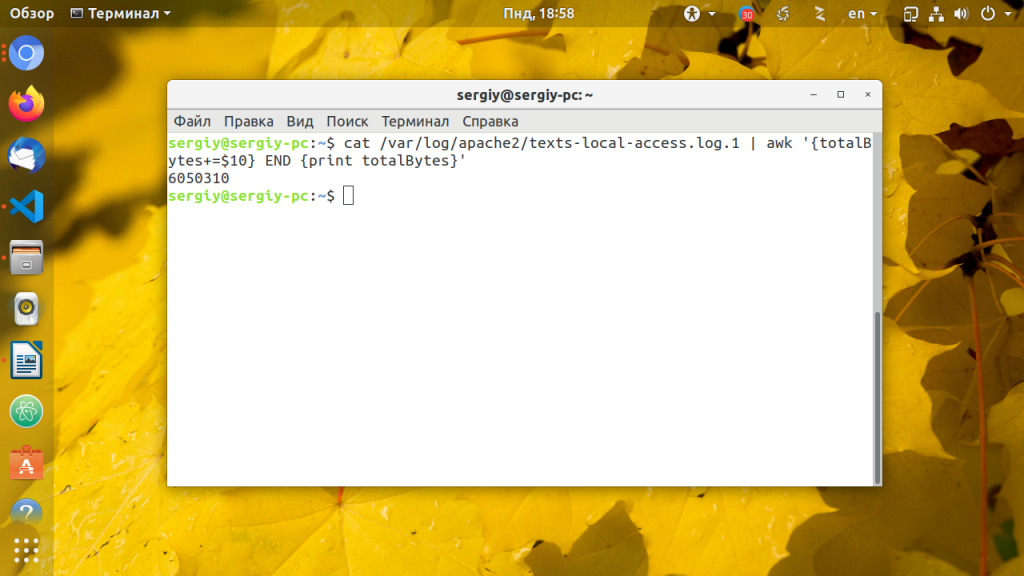
Это только несколько примеров показывающих использование awk в Linux , освоив awk один раз в получите очень мощный и полезный инструмент на всю жизнь.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.