- Install Apache Spark on Ubuntu 22.04|20.04|18.04
- Install Apache Spark on Ubuntu 22.04|20.04|18.04
- Step 1: Install Java Runtime
- Step 2: Download Apache Spark
- Set Spark environment
- Step 3: Start a standalone master server
- Step 4: Starting Spark Worker Process
- Step 5: Using Spark shell
- YOU CAN SUPPORT OUR WORK WITH A CUP OF COFFEE
- Spark Installation on Linux Ubuntu
- Prerequisites:
- Java Installation On Ubuntu
- Python Installation On Ubuntu
- Apache Spark Installation on Ubuntu
- Spark Environment Variables
- Test Spark Installation on Ubuntu
- Spark Shell
- Spark Web UI
- Spark History server
- Conclusion
- Related Articles
- You may also like reading:
- Naveen (NNK)
Install Apache Spark on Ubuntu 22.04|20.04|18.04
Welcome to our guide on how to install Apache Spark on Ubuntu 22.04|20.04|18.04. Apache Spark is an open-source distributed general-purpose cluster-computing framework. It is a fast unified analytics engine used for big data and machine learning processing.
Spark provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Install Apache Spark on Ubuntu 22.04|20.04|18.04
Before we install Apache Spark on Ubuntu 22.04|20.04|18.04, let’s update our system packages.
sudo apt update && sudo apt -y full-upgradeConsider a system reboot after upgrade is required.
[ -f /var/run/reboot-required ] && sudo reboot -fNow use the steps shown next to install Spark on Ubuntu 22.04|20.04|18.04.
Step 1: Install Java Runtime
Apache Spark requires Java to run, let’s make sure we have Java installed on our Ubuntu system.
sudo apt install curl mlocate default-jdk -yVerify Java version using the command:
$ java -version openjdk version "11.0.14.1" 2022-02-08 OpenJDK Runtime Environment (build 11.0.14.1+1-Ubuntu-0ubuntu1.20.04) OpenJDK 64-Bit Server VM (build 11.0.14.1+1-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)Step 2: Download Apache Spark
Download the latest release of Apache Spark from the downloads page.
wget https://dlcdn.apache.org/spark/spark-3.2.1/spark-3.2.1-bin-hadoop3.2.tgzExtract the Spark tarball.
tar xvf spark-3.2.1-bin-hadoop3.2.tgzMove the Spark folder created after extraction to the /opt/ directory.
sudo mv spark-3.2.1-bin-hadoop3.2/ /opt/spark Set Spark environment
Open your bashrc configuration file.
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinStep 3: Start a standalone master server
You can now start a standalone master server using the start-master.sh command.
$ start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu.outThe process will be listening on TCP port 8080.
$ sudo ss -tunelp | grep 8080 tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=8033,fd=238)) ino:41613 sk:5 v6only:0 
The Web UI looks like below.
My Spark URL is spark://ubuntu:7077.
Step 4: Starting Spark Worker Process
The start-slave.sh command is used to start Spark Worker Process.
$ start-slave.sh spark://ubuntu:7077 starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu.outIf you don’t have the script in your $PATH, you can first locate it.
$ sudo updatedb $ locate start-slave.sh /opt/spark/sbin/start-slave.shYou can also use the absolute path to run the script.
Step 5: Using Spark shell
Use the spark-shell command to access Spark Shell.
$ /opt/spark/bin/spark-shell 21/04/27 08:49:09 WARN Utils: Your hostname, ubuntu resolves to a loopback address: 127.0.1.1; using 10.10.10.2 instead (on interface eth0) 21/04/27 08:49:09 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.1.1.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release 21/04/27 08:49:10 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform. using builtin-java classes where applicable Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://10.10.10.2:4040 Spark context available as 'sc' (master = local[*], app session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3.2.1 /_/ Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 11.0.14.1) Type in expressions to have them evaluated. Type :help for more information. scala>If you’re more of a Python person, use pyspark.
$ /opt/spark/bin/pyspark Python 3.8.10 (default, Jun 2 2021, 10:49:15) [GCC 9.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.2.1.jar) to constructor java.nio.DirectByteBuffer(long,int) WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 22/04/17 20:38:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform. using builtin-java classes where applicable Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 3.2.1 /_/ Using Python version 3.8.10 (default, Jun 2 2021 10:49:15) Spark context Web UI available at http://ubuntu-20-04-02:4040 Spark context available as 'sc' (master = local[*], app available as 'spark'.Easily shut down the master and slave Spark processes using commands below.
$ SPARK_HOME/sbin/stop-slave.sh
$ SPARK_HOME/sbin/stop-master.shThere you have it. Read more on Spark Documentation.
YOU CAN SUPPORT OUR WORK WITH A CUP OF COFFEE
As we continue to grow, we would wish to reach and impact more people who visit and take advantage of the guides we have on our blog. This is a big task for us and we are so far extremely grateful for the kind people who have shown amazing support for our work over the time we have been online.
Thank You for your support as we work to give you the best of guides and articles. Click below to buy us a coffee.
Spark Installation on Linux Ubuntu
Let’s learn how to do Apache Spark Installation on Linux based Ubuntu server, same steps can be used to setup Centos, Debian e.t.c. In real-time all Spark application runs on Linux based OS hence it is good to have knowledge on how to Install and run Spark applications on some Unix based OS like Ubuntu server.
Though this article explains with Ubuntu, you can follow these steps to install Spark on any Linux-based OS like Centos, Debian e.t.c, I followed the below steps to setup my Apache Spark cluster on Ubuntu server.
Prerequisites:
- Ubuntu Server running
- Root access to Ubuntu server
- If you wanted to install Apache Spark on Hadoop & Yarn installation, please Install and Setup Hadoop cluster and setup Yarn on Cluster before proceeding with this article.
If you just wanted to run Spark in standalone, proceed with this article.
Java Installation On Ubuntu
Apache Spark is written in Scala which is a language of Java hence to run Spark you need to have Java Installed. Since Oracle Java is licensed here I am using openJDK Java. If you wanted to use Java from other vendors or Oracle please do so. Here I will be using JDK 8.
sudo apt-get -y install openjdk-8-jdk-headless Post JDK install, check if it installed successfully by running java -version

Python Installation On Ubuntu
You can skip this section if you wanted to run Spark with Scala & Java on an Ubuntu server.
Python Installation is needed if you wanted to run PySpark examples (Spark with Python) on the Ubuntu server.
Apache Spark Installation on Ubuntu
In order to install Apache Spark on Linux based Ubuntu, access Apache Spark Download site and go to the Download Apache Spark section and click on the link from point 3, this takes you to the page with mirror URL’s to download. copy the link from one of the mirror site.

If you wanted to use a different version of Spark & Hadoop, select the one you wanted from the drop-down (point 1 and 2); the link on point 3 changes to the selected version and provides you with an updated link to download.
Use wget command to download the Apache Spark to your Ubuntu server.
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz 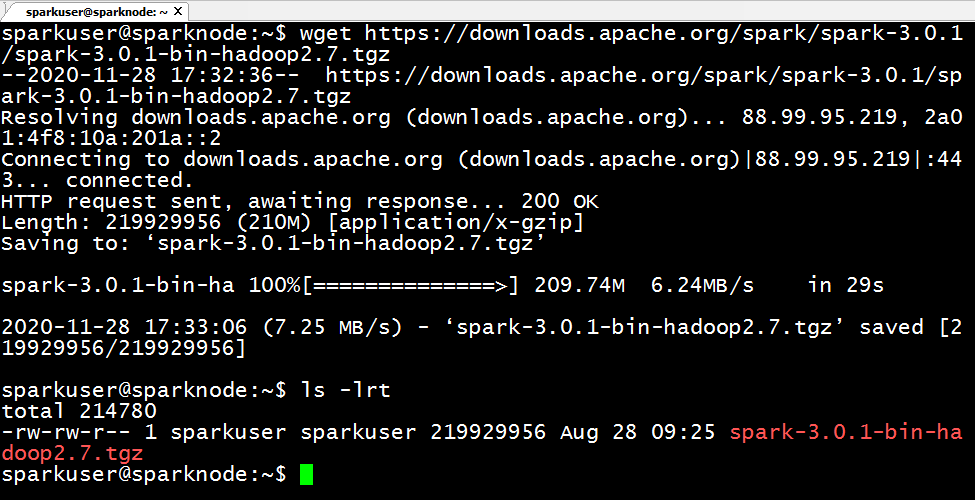
Once your download is complete, untar the archive file contents using tar command, tar is a file archiving tool. Once untar complete, rename the folder to spark.
tar -xzf spark-3.0.1-bin-hadoop2.7.tgz mv spark-3.0.1-bin-hadoop2.7 spark TODO - Add Python environment Spark Environment Variables
Add Apache Spark environment variables to .bashrc or .profile file. open file in vi editor and add below variables.
[email protected]:~$ vi ~/.bashrc # Add below lines at the end of the .bashrc file. export SPARK_HOME=/home/sparkuser/spark export PATH=$PATH:$SPARK_HOME/bin Now load the environment variables to the opened session by running below command
In case if you added to .profile file then restart your session by closing and re-opening the session.
Test Spark Installation on Ubuntu
With this, Apache Spark Installation on Linux Ubuntu completes. Now let’s run a sample example that comes with Spark binary distribution.
Here I will be using Spark-Submit Command to calculate PI value for 10 places by running org.apache.spark.examples.SparkPi example. You can find spark-submit at $SPARK_HOME/bin directory.
spark-submit --class org.apache.spark.examples.SparkPi spark/examples/jars/spark-examples_2.12-3.0.1.jar 10 
Spark Shell
Apache Spark binary comes with an interactive spark-shell. In order to start a shell to use Scala language, go to your $SPARK_HOME/bin directory and type “ spark-shell “. This command loads the Spark and displays what version of Spark you are using.

Note: In spark-shell you can run only Spark with Scala. In order to run PySpark, you need to open pyspark shell by running $SPARK_HOME/bin/pyspark . Make sure you have Python installed before running pyspark shell.

By default, spark-shell provides with spark (SparkSession) and sc (SparkContext) object’s to use. Let’s see some examples.
Spark-shell also creates a Spark context web UI and by default, it can access from http://ip-address:4040.
Spark Web UI

Apache Spark provides a suite of Web UIs (Jobs, Stages, Tasks, Storage, Environment, Executors, and SQL) to monitor the status of your Spark application, resource consumption of Spark cluster, and Spark configurations. On Spark Web UI, you can see how the Spark Actions and Transformation operations are executed. You can access by opening http://ip-address:4040/ . replace ip-address with your server IP.
Spark History server
Create $SPARK_HOME/conf/spark-defaults.conf file and add below configurations.
# Enable to store the event log spark.eventLog.enabled true #Location where to store event log spark.eventLog.dir file:///tmp/spark-events #Location from where history server to read event log spark.history.fs.logDirectory file:///tmp/spark-events Create Spark Event Log directory. Spark keeps logs for all applications you submitted.
Run $SPARK_HOME/sbin/start-history-server.sh to start history server.
[email protected]:~$ $SPARK_HOME/sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /home/sparkuser/spark/logs/spark-sparkuser-org.apache.spark.deploy.history.HistoryServer-1-sparknode.out 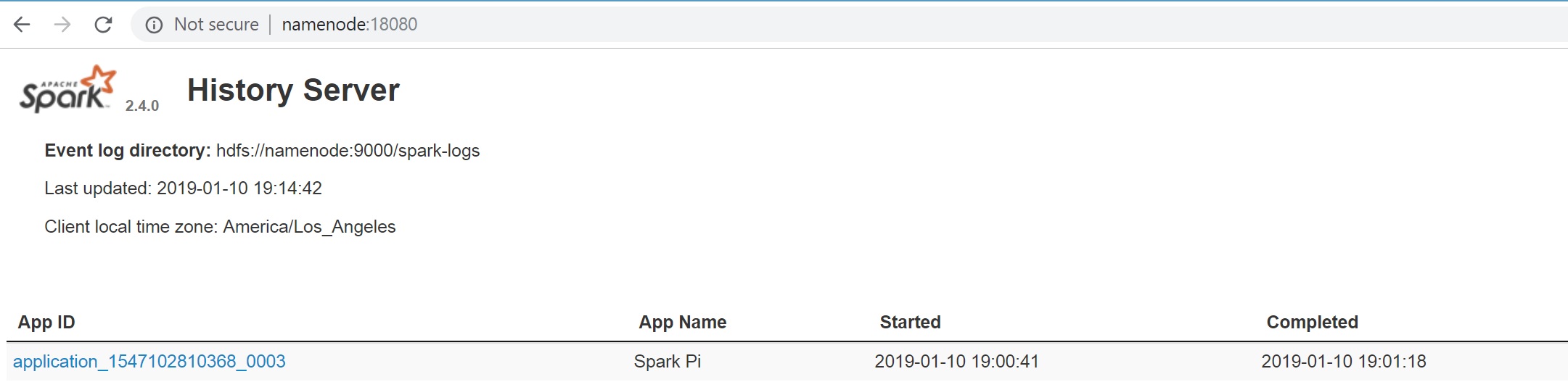
As per the configuration, history server by default runs on 18080 port.
Run PI example again by using spark-submit command, and refresh the History server which should show the recent run.
Conclusion
In Summary, you have learned steps involved in Apache Spark Installation on Linux based Ubuntu Server, and also learned how to start History Server, access web UI.
Related Articles
You may also like reading:
Naveen (NNK)
SparkByExamples.com is a Big Data and Spark examples community page, all examples are simple and easy to understand and well tested in our development environment Read more ..