Сравнение сетевых и иерархических моделей
В строго иерархических моделях, как правило, любой объект (запись, сегмент) может подчиняться только одному объекту вышестоящего уровня. В сетевых моделях – любой объект (запись, файл) может быть подчинен нескольким объектам. Отличие в топологии иерархической и сетевой модели схематически иллюстрирует рис.10.2.
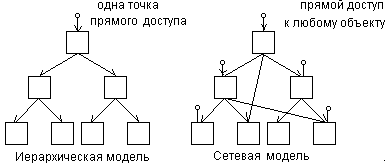
Рис.2. Иллюстрация особенностей моделей по топологии и доступу
В иерархических моделях непосредственный доступ по ключу, как правило, возможен только к объекту самого высокого уровня, который не подчинен другим объектам. К другим объектам доступ осуществляется по связям от объекта на вершине модели. В сетевых моделях непосредственный доступ по ключу может обеспечиваться к любому объекту независимо от его уровня в модели. Возможен также доступ по связям от любой точки доступа.
Структура объекта (записи, файла) в сетевых моделях чаще бывает линейной и реже имеет иерархическую структуру. Объект линейной структуры состоит только из простых и ключевых атрибутов. Структуры данных более низкого уровня также могут иметь свою специфику и названия. Например, атрибут – аналог элемента данных. Структура объекта (записи, сегмента) в иерархических моделях может быть иерархической (см. рис.10.1.) или линейной.
Сетевая модель на примере базы данных, содержащей справочные данные о цехах, складах, изделиях, плановые данные выпуска изделий цехами и учетные данные о сдаче выпущенных цехами изделий на склад, приведена на рис.10.3. Объекты в этой модели являются линейными.
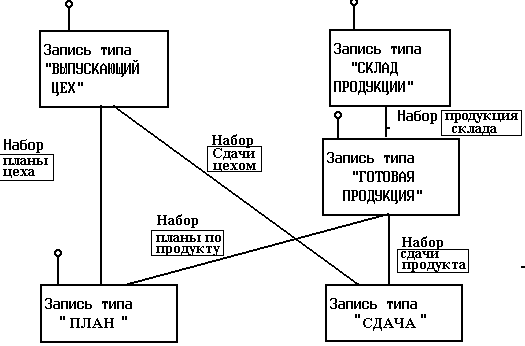
Рис. 3. Пример базы данных, реализованной сетевой моделью
Достоинством сетевых моделей является отсутствие дублирования данных в различных объектах модели. Кроме того, технология работы с сетевыми моделями является удобной для пользователя, так как доступ к данным практически не имеет ограничений и возможен непосредственно к объекту любого уровня. Допустимы всевозможные запросы. Сетевые модели позволяют отображать также иерархические взаимосвязи данных.
В соответствии со структурами данных, используемыми в модели данных, каждая сетевая или иерархическая СУБД имеет свой язык описания данных – язык декларативных команд. Язык манипулирования данными также специфичен для каждой СУБД и зависит от типов структур данных модели. Такие отличия в используемых языковых средствах затрудняют освоение СУБД, поддерживающих сетевые и иерархические модели. Генерация описания схемы БД делает программы зависимыми от структуры БД.
Реляционная модель данных
Концепция реляционной модели принадлежит американскому ученому Е. Кодду. Реляционные модели данных (РМД), в отличие от рассмотренных выше сетевых и иерархических, характеризуются простотой структуры данных, удобным для пользователя табличным представлением и доступом к данным.
Возможность использования формального аппарата алгебры отношений и реляционного исчисления для обработки реляционной модели данных обеспечивает использование типовых простых средств обработки в различных реляционных СУБД. К таким средствам относится, например, реляционный язык структурированных запросов SQL.
Реляционная модель данных является совокупностью простейших двумерных реляционных таблиц-отношений. Связи между двумя логически связанными таблицами в реляционной модели устанавливаются по равенству значений одинаковых атрибутов таблиц-отношений. Таблица-отношение является универсальным объектом реляционных моделей. Это обеспечивает возможность унификации обработки данных в различных СУБД, поддерживающих реляционную модель. Операции обработки реляционных моделей основаны на использовании универсального аппарата алгебры отношений и реляционного исчисления.
Преимущества реляционных моделей. К достоинствам реляционной модели относятся простота представления данных реляционной модели благодаря табличной форме и минимальная избыточность данных при нормализации таблиц-отношений. В реляционных моделях обеспечивается независимость приложений пользователя от данных, допускающая включение или удаление отношений, изменение атрибутного состава отношений. В отличие от иерархических и сетевых, реляционные базы данных не требуют описания схемы данных и ее генерации, т.е. не требуется настройка СУБД на конкретную структуру БД. Универсальность процедур обработки данных является основой типовых средств в различных реляционных СУБД.
39.Иерархический и сетевой подходы.
Иерархические СУБД, частично реализующие и элементы сетевого подхода, широко распространены в связи со сравнительно малым временем поиска данных. Реляционные БД можно перестроить в иерархические и наоборот. Иерархическая модель данных основана на понятии деревьев, состоящих из вершин и ребер. Вершина дерева ставится в соответствие совокупности атрибутов данных, характеризующих некоторый объект. Вершины и ребра дерева как бы образуют иерархическую древовидную структуру, состоящую из n уровней.(рис.5,4) Первую вершину в дереве называют корневой вершиной иерархической древовидной структуры. Она удовлетворяет семи условиям:
1. Иерархия начинается с корневой вершины.
2. Каждая вершина соответствует одному или нескольким атрибутам. 3. На уровнях с большим номером находятся зависимые вершины. Вершина предшествующего уровня является начальной для новых зависимых вершин.
4. Каждая вершина, находящаяся на уровне i, соединена с одной и только одной вершиной уровня i–1, за исключением корневой вершины.
5. Корневая вершина может быть связана с одной или несколькими зависимыми вершинами.
6. Доступ к каждой вершине происходит через корневую по единственному пути.
7. Существует произвольное количество вершин каждого уровня. Иерархическая модель данных состоит из нескольких деревьев, т.е. является лесом.
Каждая корневая вершина образует начало записи логической базы данных. В иерархических БД обеспечивается удобный и быстрый поиск, если запрос строится по первичным ключам, в соответствии с которыми выбрана структура дерева. Если в запросе фигурируют другие атрибуты, то поиск может свестись к полному просмотру БД и, следовательно, резко замедлиться. В сетевой модели данных элементарные данные и отношения между ними представляются в виде ориентированной сети (вершины – данные, дуги – отношения). База данных, описываемая сетевой моделью, состоит из нескольких областей. Область содержит записи. Одна запись состоит из нескольких полей. Набор, состоящий из записей, может размещаться в одной или нескольких областях (рис. 5,5). В сетевой модели данных объекты предметной области объединяются в сеть. Графически сетевая модель описывается прямоугольниками и стрелками. Каждый тип записи может содержать множество атрибутов. Важное отличие сетевой модели данных от иерархической состоит в том, что в сетевой модели каждая запись может быть в любом числе наборов и может находиться как на верхнем, так и на нижнем иерархическом уровне. Следовательно, любая запись может быть задана как точка входа. Основные достоинства сетевой модели данных – наличие реализованных СУБД, обеспечивающих эту модель, простота реализации отношений «многие ко многим». Основной недостаток – ее сложность. При реорганизации БД возможна потеря независимости данных.
40.Организация базы данных на физическом уровне.
В реляционных БД организуется обычное хранение информации в виде двумерных таблиц. В иерархических БД структура данных – список, в котором система указателей позволяет просматривать дерево сверху вниз и слева.. Поиск нужной информации по заданному ключу выполняется с помощью индексного файла, в который вынесены значения ключей и соответствующих им адресов памяти, по которым хранятся записи. Индексный файл – это отношение между значениями первичного ключа и адресами. Разнохарактерность проектных процедур в САПР обусловливает разнообразие типов и структур данных, которыми обмениваются пользователи и прикладные программы через БД. База данных САПР должна быть приспособлена для хранения: сведений справочного характера об используемых материалах, комплектующих деталях и приборах, инструменте, оборудовании, оснастке, которые первоначально имеют форму таблиц; информации о чертежах и схемах, требующих для своего представления в ЭВМ специального кодирования; текстовых документов типа пояснительных записок, описаний программ и др. При создании конкретных САПР возникает проблема выбора и оценки АБД. Правильность выбора АБД во многом определяет эффективность создания и удобство функционирования САПР. Таким образом, эта проблема затрагивает не только разработчиков, но и пользователей САПР. В настоящее время ИО САПР строится, как правило, по принципам, выработанным и апробированным при использовании АБД в информационных системах общего назначения. АБД относятся к инвариантным средствам САПР. Поэтому создатели САПР обычно не разрабатывают специальные АБД, а выбирают из готовых общего назначения и адаптируют их к целям конкретной САПР. Выбор СУБД для разрабатываемых САПР должен быть направлен главным образом на удовлетворение требований и потребностей пользователей–проектировщиков. Факторы, определяющие СУБД, разбиваются на две группы: характеризующие предполагаемое применение СУБД; характеризующие функциональные возможности СУБД. В характеристику применения обычно включают: классификацию и характеристику конечных пользователей и обслуживающего персонала СУБД; сложность и форму запросов; режим работы; эволюционные характеристики; характеристики данных; характеристики ресурсов. Функциональные возможности можно характеризовать следующими факторами: назначение СУБД; поддерживаемые структуры данных; используемое оборудование; *164используемое ПО; трудности освоения и эксплуатации. При разработке концепции САПР следует учитывать не только положительные стороны АБД, но и “плату” за реализацию возможностей: затраты на управление автоматизированным банком данных: требуются значительные ресурсы для функционирования СУБД и операционной системы ЭВМ;трудности соблюдения разработчиками и пользователями прикладных программ тех ограничений, которые положены в основу СУБД; необходимость создания специального административного подразделения, ответственного за эксплуатацию автоматизированный банк данных; угроза безопасности данных, связанная с большой их централизацией: неисправности в технических средствах и ошибки в прикладных программах Таким образом, в арсенале специалистов имеется большое количество СУБД, которые могут быть использованы в практике проектирования САПР.