3 Модели данных
Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними.
Модель данных — совокупность структур данных и операций их обработки.
СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве.
Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную.
3.1 Иерархическая модель
Иерархическая модель организует данные в виде древовидной структуры. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Дерево представляет собой иерархию элементов, называемых узлами. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На самом верхнем уровне иерархии имеется один и только один узел — корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемом исходным для данного узла. Ни один элемент не имеет более одного исходного. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне. Они называются порожденными.
В иерархической системе (построенной на основе иерархической модели) запись «потомок» должна иметь одного «предка». Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается.
Для БД определен полный порядок обхода — сверху вниз, слева направо.
3.2 Сетевая модель
Сетевые модели являются расширением иерархических. Сетевая модель организует данные в виде сетевой структуры. Структура называется сетевой, если в отношениях между данными порожденный элемент имеет более одного исходного.
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом.
В сетевой структуре данных «потомок» может иметь любое число «предков». Между ветвями могут существовать горизонтальные связи. «Наборы» соединяются при помощи записей-связок, образуя сложные цепочки.
Сложность практического использования иерархических и сетевых систем определила переход к реляционным БД.
3.3 Реляционная модель
3.3.1 Терминология и базовые понятия реляционных бд
Почти все программные продукты, созданные с конца 70-х г. основаны на реляционном подходе:
Данные представлены в двухмерных таблицах, организованных по определенным правилам.
Пользователю предоставляются операторы для работы с данными, с помощью которых генерируются новые таблицы на основе исходных – запросы.
Реляционные базы данных – единое хранилище данных, которое однозначно определяется, а затем используется многими пользователями. Изменение и добавление данных в БД не влияет на приложение.
Система управления базами данных – программный комплекс, с помощью которого пользователи могут определять и поддерживать БД, осуществлять контролируемый доступ.
Базовые понятия реляционных баз данных:
1. Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких, как «деньги»), а также специальных «темпоральных» данных (дата, время, временной интервал).
2. Реляционная модель основана на математическом понятии отношение, физическим представлением которого является таблица, то есть отношением можно назвать плоскую таблицу, состоящую из столбцов и строк.
3. Кортеж, соответствующий данной схеме отношения, — это множество пар , которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения.
4. Атрибут – столбец таблицы, поле файла БД. Значения атрибутов в таблице-отношении могут иметь только один определенный вид функциональной зависимости друг от друга, а именно все значения в произвольном кортеже должны по отдельности зависеть только от значений столбца или группы столбцов — одних для всего отношения. Такой столбец или группа столбцов называются ключевыми, а значения атрибутов в них — ключами.
5. Домен – набор допустимых значений одного или нескольких атрибутов.
6. Степень отношения определяется количеством атрибутов, которое оно содержит. Отношение с одним атрибутом имеет степень 1 и называется унарным отношением. Отношение с двумя атрибутами называется бинарным, отношение с тремя атрибутами – тернарным, а для отношения с большим количеством атрибутов используется термин n-арное.
7. Кардинальность отношений – количество кортежей, которое содержится в отношении. Эта характеристика меняется при каждом удалении или добавлении кортежей.
8. Исходя из вышеизложенного, реляционная база данных состоит из отношений, структура которых определяется с помощью особых методов, называемых нормализацией.
9. В отношении не должно быть повторяющихся кортежей, в связи с этим вводится понятие реляционных ключей для уникальной идентификации каждого отдельного кортежа отношения по значениям одного или нескольких атрибутов.
10. Суперключ – атрибут или множество атрибутов, которое единственным образом идентифицирует кортеж данного отношения.
11. Потенциальный ключ – суперключ, который не содержит подмножества, также являющегося суперключем данного отношения. Потенциальный ключ К для данного отношения R обладает двумя свойствами:
Уникальность. В каждом кортеже отношения R значение ключа К единственным образом идентифицирует этот кортеж.
Неприводимость. Никакое допустимое подмножество ключа К не обладает свойством уникальности.
12. Первичный ключ – потенциальный ключ, который выбран для уникальной идентификации кортежей внутри отношения, остальные невыбранные ключи являются альтернативными. Если первичный ключ состоит из одного поля, он называется простым, если из нескольких полей — составным.
13. Вторичный (внешний) ключ (ВК) — это одно или несколько атрибутов внутри отношения, которые соответствуют потенциальному ключу некоторого отношения и выполняют роль поисковых или группировочных признаков. В отличие от первичного значение вторичного ключа может повторяться в нескольких записях файла, то есть он не является уникальным. Если по значению первичного ключа может быть найден один единственный экземпляр записи, то по вторичному — несколько.
14. Отношение — это множество кортежей, соответствующих одной схеме отношения.
15. Базовое отношение – отношение, кортежи которого физически хранятся в базе данных.
16. Представления – динамический результат одной или нескольких реляционных операций над базовыми отношениями с целью создания некоторого иного отношения. Представление является виртуальным отношением, которое реально в базе данных не существует, но создается по требованию отдельного пользователя в момент поступления этого требования. Представления позволяют достичь более высокой защищенности данных и предоставляют проектировщику средства настройки пользовательской модели.
17. Фундаментальные свойства отношений:
Отношение имеет имя, которое отличается от имен всех других отношений в реляционной схеме.
Каждая ячейка отношения содержит только одно элементарное (неделимое) значение.
Каждый атрибут имеет уникальное имя.
Значения атрибута берутся из одного и того же домена.
Каждый кортеж является уникальным, т.е. дубликатов кортежей быть не может.
Порядок следования атрибутов не имеет значения.
Теоретически порядок следования кортежей в отношении не имеет значения. (Но практически этот порядок может существенно повлиять на эффективность доступа к ним.)
Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
1. Структура модели основывается на нормализованных отношениях с учетом базовых понятий реляционной БД.
2. В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД — реляционная алгебра и реляционное исчисление.
3. Целостность (от англ. integrity – нетронутость, неприкосновенность, сохранность, целостность) понимается как правильность данных в любой момент времени.
2.14. Средства поддержки бд
Взаимодействие пользователя с базами данных обеспечивается соответствующими средствами аппаратной и программной поддержки. Их можно разделить на три группы. Первая группа — средства ввода-вывода данных, к которым относятся: клавиатура, магнитный диск, сканер, дигитайзер, лазерный диск, видеокамера, принтер, плоттер, видеоэкран и др. с соответствующими программными средствами.
Сканер обеспечивает считывание информации с твердых носителей, чаще с бумажных, путем сплошной оцифровки рабочей поверхности. Дигитайзер предназначен для оцифровывания заданных последовательностей точек в двух- или трехмерном представлении. Плоттер — это устройство вывода на твердый носитель графической информации.
Во вторую группу выделяются средства передачи данных: локальные вычислительные сети с операционной системой и аппаратными средствами, включающими рабочие станции (РС), файл-сервер (ФС), сетевые адаптеры, сетевой кабель; глобальные вычислительные сети (ГВС) с соответствующим программным обеспечением и аппаратными средствами, включающими модем (МД), телефонную линию, спутниковую связь.
Рабочие станции представляют собой ПК, подключенные к ЛВС, оборудованные необходимыми периферийными средствами, предназначенные для решения задач пользователя. Файл-сервер — это наиболее мощный ПК в сети, который концентрирует в своей памяти всю информацию, циркулирующую в ЛВС между РС. Модем в ГВС предназначен для сопряжения РС с линией сетевой связи, он обеспечивает кодирование и декодирование с проверкой и исправлением ошибок передаваемой информации.
Средства манипулирования данными в БнД включены в третью группу. Она включает СУБД, язык запросов, например, SQL, программы пользователей.
2.15. Виды моделей данных для бд
При разработке прикладных программ, или приложений, для пользователей БД удобно ориентироваться на заранее проработанные и рекомендованные типовые модели данных, т.е. некоторые стандартные модели, структуры которых удовлетворяют заранее определенным требованиям.
В современных информационных системах наиболее распространены три вида моделей данных:
Иерархическая модель данных
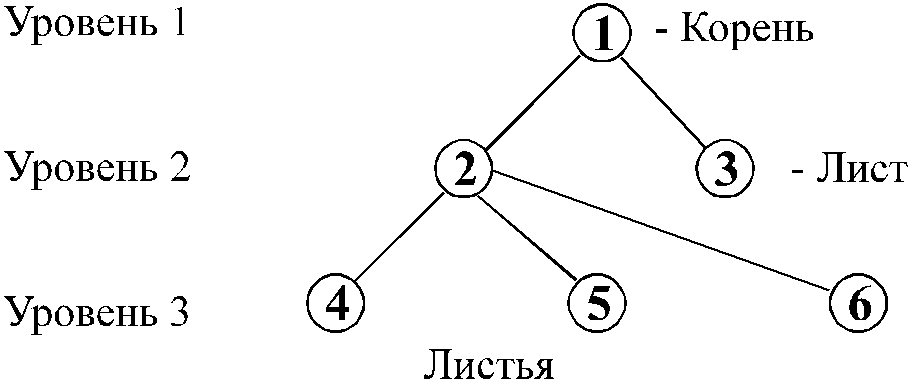
Иерархическая модель данных – это модель, имеющая древовидную графовую структуру (Рис. 0 .13), представляющую собой иерархию элементов, называемых вершинами (или узлами), соединенных между собой дугами (или ветвями). На верхнем уровне иерархии, называемом первым, находится единственный узел, называемый корнем. Узлы следующего более низкого уровня порождаются предыдущими узлами. Каждый узел более высокого уровня может породить один или несколько узлов следующего уровня. Узлы, не имеющие порожденных, называются листьями. Иерархическая структура используется как для логического, так и для физического описания данных. Файлы с записями, связанными древовидной структурой, называются иерархическими. Рис. 0.13
Сетевая модель данных
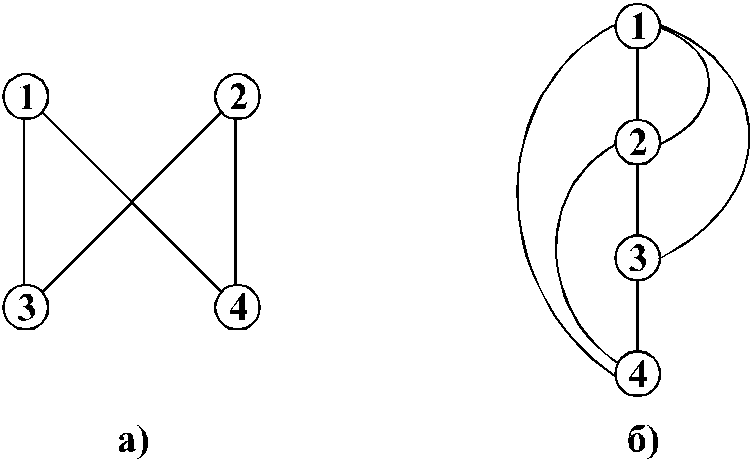
Сетевой моделью данных называется структура, в которой порожденный элемент может иметь больше одного исходного элемента. На Рис. 0 .14,а каждый порожденный элемент 3 и 4 имеет по два исходных: элементы 1 и 2. На Рис. 0 .14,б нижний элемент 4 имеет три исходных: элементы 1, 2, 3. Рис. 0.14 Для сетевых моделей данных, как и для иерархических, рассматривается уровневость. Так, структура на рис.2.14,а является двухуровневой, а на Рис. 0 .14,б — четырехуровневая. В зависимости от уровней связи сетевые модели разделяются на два вида структур:
- сетевые модели простой структуры — при наличии связей типа 1:1 и 1:М;
- сетевые модели сложной структуры — при наличии связей типа М: М.