Лекция 5 модели данных (продолжение)
Сетевые модели данных базируются на использовании графовой формы представления данных. Вершины графа используются для интерпретации типов объектов. При реализации вершины графа представляются совокупностью описаний экземпляров объемов соответствующего типа. Дуги графа (связи между вершинами) используются для интерпретации типов связей между типами объектов. Такое изображение структуры БД называется диаграммой Бохмана.
Сетевые МОД и соответствующие СУБД построены на основе предложений КОДАСИЛ с основными типами структур данных: элемент, агрегат, запись, набор, база. МОД допускает существование записей с простой (только из элементов) в сложной внутренней структурой.
Во втором случае запись имеет многоуровневую древовидную иерархическую структуру с использованием агрегатов. Типы наборов используются в МОД для представления типов связей между типами объектов и изображаются поименованной дугой, которая исходит из типа записи — владельца набора и заходит в тип записи — члена набора.
В модели КОДАСИЛ основным внутренним ограничением целостности является функциональная связь, т.е. с помощью наборов можно реализовать непосредственно связи типа 1:1, 1:М, М:1. В модели это внутреннее ограничение выражается утверждением: в конкретном экземпляре набора экземпляр записи — члена набора может иметь не более одного экземпляра записи — владельца набора. Отсюда следует второе внутреннее ограничение целостности — экземпляр записи может быть членом только одного экземпляра набора среди всех экземпляров набора одного типа (он может входить в состав двух и более экземпляров наборов, но разных типов).
Для представления связи типа М:М вводят вспомогательный тип записи и две функциональные связи типа 1:М ( рис. 1).
Еще одно внутреннее ограничение сетевой МОД — невозможность непосредственного представления данных, описывающих связи (между объектами), имеющие собственные атрибуты. В этом случае вводится вспомогательный тип записи.


Рис. 1. Пример представления связи типа «многие ко многим»
В модели можно представлять типы связей, заданных между несколькими типами объектов. Для этого используют многочленные наборы, которые представляют собой отношение между тремя или более типами записей, один из которых назначается владельцем набора, а остальные – членами набора (рис. 2)
Рис.2. Пример многочленного набора
В модели КОДАСИЛ еще сингулярный набор, владельцем которого является система. При его реализации возможен только один экземпляр набора этого типа. Это тип набора без записи – владельца (рис. 3).

Рис.3. Пример сингулярного типа набора
Сингулярный набор можно использовать для создания традиционного файла, состоящего из однотипных записей. Количество объявляемых сингулярных наборов произвольно. Один и тот же тип записи может быть объявлен членом сингулярного набора и одновременно владельцем либо членом других наборов. Сингулярный набор объявляется обычно для записи владельца набора, чтобы получить доступ ко всем экземплярам записей — владельцев некоторого типа, а следовательно, и ко всем экземплярам набора соответствующего типа (владельцем которого этот тип записи является).
Любой вводимый в схему БД тип набора представляет приклад-ному программисту соответствующий путь доступа к специфицированным в этом наборе записям. Необходимость введения какого-либо типа набора в схему БД полностью определяется необходимостью реализации соответствующего пути доступа к данным в БД.
Эталонный вариант сетевой модели данных впервые был описан в проекте КОДАСИЛ. Сетевые (и, как частный случай, иерархические)СУБД получили наибольшее распространение на больших и мини-ЭВМ. Для отечественных ЭВМ создано несколько СУБД, поддерживающих сетевые модели данных: система СЕТЬ, реализующая под-множество предложений КОДАСИЛ: система БАНК, родственная зарубежной системе IDS; системы семейства СЕТОР, имеющие версии для ЭВМ разных классов.
2. ИЕРАРХИЧЕСКАЯ МОДЕЛЬ ДАННЫХ
Здесь структура данных также определяется в терминах сетевой модели (элемент, агрегат, запись, групповое отношение, база данных) для графического обозначения структур используют диаграммы Бахмана. Отличие иерархической модели данных состоит в том, что БД может иметь только древовидную структуру.
Групповые отношения в иерархической модели данных не именуются, поскольку они определяются парой типов записей: владелец (исходная запись) — подчиненный. К каждой записи БД существует только один путь (иерархический) от корневой записи. Для упорядочения подчиненных записей в групповых отношениях могут использоваться разные способы, но наиболее употребляемый — сортировка по возрастающим значениям ключевого данного.
Корневая запись обязательно должна содержать ключевые данные (ключ) о уникальным значением. Ключи некорневых записей должны иметь уникальные значения только в экземплярах групповых от ношений. Каждая запись идентифицируется полным (сцепленным ключом про которым понимается совокупность ключей всех записей от корневой по иерархическому пути. Например, для записи МБ (рис. 4) полный сцепленный ключ представляет конкатенацию ключей записей А1, В3, М5.

Рис. 4. Графическое изображение иерархической БД
В иерархической МОД действуют более жесткие внутренние ограничения на представление связей между объектами, чем в сетевой модели: 1) все типы связей функциональные, т.е. 1 : 1, 1 : М, М:1; 2) структура связей древовидная.
Иерархическая древовидная структура, ориентированная от корня, удовлетворяет следующим условиям (рис 5):
— иерархия всегда начинается о корневого узла;
— «на первом (верхнем) уровне ( i = 1) может находиться только один узел — корневой;
— на нижних уровнях (i=2,3. n) находятся порожденные (зависимые) узлы;
— каждый исходный узел может иметь один или несколько непосредственно порожденных (подобных) узлов;
— каждый порожденный узел i-го уровня связан только с одним непосредственно исходным (родительским) узлом (i-1)-го уровня иерархии дерева;
— доступ к каждому порожденному узлу выполняется через его непосредственно исходный узел;
— существует единственный линейный иерархический путь доступа к любому узлу, начиная от корня дерева.

Рис.5. Пример схемы иерархической базы данных
Каждую сетевую структуру (с небольшими изменениями) можно представить средствами иерархической модели. В этом случае запись сетевой структуры будет представлена несколькими записями иерархической модели данных, а сама сеть – одной или несколькими древовидными структурами
Рассмотрим пример (рис. 6) . В сетевой модели данных можно перейти от некоторой записи-владельца к подчиненной записи, а от нее к владельцу другого группового отношения.

Рис. 5. Преобразование сетевой структуры в иерархическую
Так от записи ПОЛИКЛИНИКА, просматривая запись ЖИТЕЛЬ, можно для каждого жителя извлекать запись ОРГАНИЗАЦИЯ, Для обеспечения такой возможности при использовании иерархической модели данных необходимо дополнительное дублирование данных, так, в записи ПАЦИЕНТ следует хранить ключ записи ОРГАНИЗАЦИЯ. Поэтому после преобразования исходной сетевой модели в три иерархические модели сведения о жителе будут содержаться в трех записях: ПАЦИЕНТ, СОТРУДНИК, НАЛАДЧИК. Состав данных в этих записях будет различным (у пациента – медицинские данные, у сотрудника – производственные), но часть сведений будет дублироваться (например, фамилия, адрес и т.п.). Такие записи часто называются парными. Ответственность за поддержание соответствия между парными записями ложится на пользователя (модель данных этого соответствия не обеспечивает).
Сетевые структуры могут быть простыми ( отсутствуют связи «многие ко многим») и сложными (допускаются связи N:M). С помощью введения избыточности можно переходить от сложной сети к простой, от простой к древовидной. При упрощении сложной сети простым повторением информации не обойтись. В этом случае создается новый узел вместо связи N:M, который составляется как сцепление первичных ключей соединяемых записей. Этот узел выполняет роль соотношения N:M.
Сетевая модель данных
Сетевая модель данных является развитием иерархической модели. В сетевой модели, так же как и в иерархической модели, есть понятие элемента данных и связи, которая может быть именована. Главное отличие сетевой модели от иерархической заключается в том, что к каждому элементу может идти связь не от одного элемента (“родителя”), а от нескольких.
Например, генеалогическое дерево, построенное только по мужской линии (или, только по материнской), является древовидной, иерархической структурой — у каждого человека (элемента), есть только один родитель. Если же включать в генеалогическое дерево всех родителей, то такое дерево с точки зрения структур данных будет уже не деревом, а сетью:
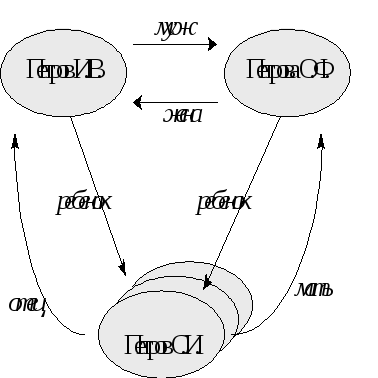
Рис.2.3. Представление фрагмента генеалогического дерева на основе сетевой модели данных
На данном рисунке представлены элементы только одно класса — описание людей, и на этом множестве для некоторых конкретных пар людей существуют связи, именуемые “муж”, “жена”, “отец”, “мать”, “ребенок”. Поэтому с точки зрения графического представления схемы этой базы данных (а не конкретных данных о семье Петровых), можно использовать следующий рисунок:
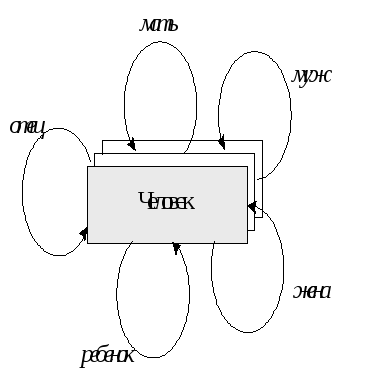
Рис.2.4. Представление схемы базы данных генеалогического дерева на основе сетевой модели данных
Сетевая модель данных основывается на понятии элемента данных и связей, задающих логику взаимоотношениями между данными. Связи от каждого элемента могут быть направлены на произвольное количество других элементов. На каждый элемент могут быть направлены связи от произвольного числа других элементов. Каждый элемент данных описывает некоторое понятие из предметной области и характеризуется некоторыми атрибутами. Для каждого элемента данных (элемент — это часть схемы) в реальной базе данных может существовать несколько экземпляров этого элемента. С каждым конкретным экземпляром по конкретной связи может быть связано разное число экземпляров другого элемента (например, у каждого человека разное число детей), но число видов связи одинаково для всех экземпляров одного элемента.
Если мы вернемся к нашему примеру про издательства тематических сборников (этот пример рассматривался в разделе про иерархические СУБД) и попытаемся расширить его, для того чтобы он более полно соответствовал реальным взаимоотношениям, то схема базы данных будет выглядеть следующим образом:
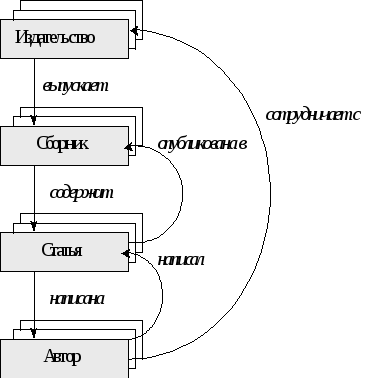
Рис.2.5. Представление расширенной схемы базы данных для описания издательств на основе сетевой модели
К достоинствам сетевой модели относится очень высокая скорость поиска и возможность адекватно представлять многие задачи в самых разных предметных областях. Высокая скорость поиска основывается на классическом способе физической реализации сетевой модели — на основе списков.
Главным недостатком сетевой модели, как, впрочем, и иерархической, является ее жесткость. Поиск данных, доступ к ним, возможен только по тем связям, которые реально существуют в данной конкретной модели. При поиске данных сетевая СУБД требует перемещаться только по существующим, заранее предусмотренным связям.