2.11. Типы моделей представления данных
Эта тема посвящена типовым моделям представления данных, используемым в практике описания экстенсиональной информации: реляционной, иерархической и сетевой модели. Они основаны на ранее рассмотренных табличных и графовых представлениях. Эти типовые модели лежат в основе большинства баз данных, реализуемых в ЭВМ.
2.11.1. Реляционная модель
Реляционная модель данных основана на представлении данных в виде реляционных таблиц (отношений). Интенсионал такой модели представляет собой множество так называемых реляционных схем (схем отношений). Каждая такая реляционная схема задается именем соответствующего отношения и списком имен его атрибутов. Например,
ПОСТАВЩИК(Номер, Имя, Адрес).
Такая схема не только указывает на атрибуты, составляющие отношение, но и фиксирует их последовательность. В реляционной модели в виде отношений представляются как типы объектов, так и типы связей: каждой схеме отношения соответствует реляционная таблица. Поэтому экстенсионал всей модели – это множество реляционных таблиц, каждая из которых представляет экстенсионал соответствующего типа объекта или типа связи.

Это означает, что ключевой атрибут одного из типов объекта добавляется в другой тип, где используется для отражения связей. Например, функциональная связь между отношениями
БОЛЬНИЦА(Код больницы, Название больницы, Адрес) и
ПАЛАТА(Код палаты, Тип, Код больницы)
выражена включением в схему отношения ПАЛАТА ключа Код больницы. В первом типе объекта этот атрибут необходим для описания больниц, а во втором типе этот же атрибут используется для отражения связей между палатами и больницами.
Обычно взаимно однозначные и функциональные связи представляются неявным образом в отношениях, соответствующих связанным типам объектов. Для этого используются ключи. Такой способ представления связей называется распространением ключа. Тип связи “многие–ко–многим” представляется отдельными отношениями.
2.11.2. Иерархическая модель
В повседневной жизни мы часто имеем дело с иерархическими структурами. Например, на каждом предприятии есть руководители и подчиненные. В зависимости от положения сотрудника в иерархической структуре подчиненности изменяется и круг его обязанностей.

Рассмотрим иерархическую модель данных на примере базы медицинских данных. Определим следующие типы объектов: БОЛЬНИЦА, ЛАБОРАТОРИЯ, ПАЛАТА, ПЕРСОНАЛ, ПАЦИЕНТ, ВРАЧ. Тогда иерархическая модель может быть следующей.

Здесь корневым является узел БОЛЬНИЦА, остальные узлы – зависимые. Узлы ПЕРСОНАЛ и ПАЦИЕНТ – порождены узлом ПАЛАТА и находятся на втором уровне.
Иерархическая модель представляет собой граф в виде древовидной структуры. Узлы (вершины) сопоставляются типам объектов, а дуги – типам связи. Наивысший узел называется корнем или корневым узлом (например, руководитель предприятия). Корень в иерархической модели должен быть единственным, зависимые узлы располагаются на более низких уровнях иерархии. Уровень, на котором находится узел, определяется “расстоянием” от корневого узла, измеряемым количеством узлов высшей иерархии. Узел, находящийся на каком-либо уровне, называется исходным для связанных с ним узлов следующего уровня. Узлы называются порожденными (зависимыми) узлом, находящимся на предыдущем уровне, если они связаны с ним. Узлы, не имеющие порожденных, называются листьями.

Иерархическую модель можно схематично представить в виде перевернутого дерева: корень находится вверху, а ветви направлены вниз.

Каждый узел в этой модели связан только с одним узлом, находящимся на предыдущем уровне. И каждый узел может быть связан с одним или несколькими узлами, находящимися на более низком уровне.
Иерархическую модель можно схематично представить в виде перевернутого дерева: корень находится вверху, а ветви направлены вниз. Доступ к каждому узлу, за исключением корневого, происходит только через исходный узел. В связи с этим в такой модели пути доступа к каждому узлу являются уникальными. Поэтому иерархическая модель обеспечивает только линейные пути доступа. С помощью иерархической модели удобно представлять данные, связанные отношениями “класс–подкласс”, “общее–частное” и т.п.



Эту модель допустимо использовать в том случае, если типы объектов связаны связью “один–ко–многим” и “один-к-одному”. В этой модели можно реализовать связи “многие–ко–многим”, но это делается искусственно включением дополнительных узлов и приводит к тому, что структура БД становится громоздкой. Другим недостатком является то, что в ней затруднены операции удаления и включения узлов.
При описании интенсионала каждая вершина соответствует типу объекта, а дуга – типу связи. Экстенсионал каждой вершины может быть представлен реляционной таблицей или таблицей записей. Экстенсионал связи “исходный-порожденный” можно представить множеством соединений между экземплярами таблиц.
3.2. Сетевая модель данных
Сеть образуется двумя типами данных, различающихся в программе пользователя: вершинами и дугами. В отличие от дерева вершина может иметь произвольное количество входных и выходных дуг. Дерево – частный случай сети. В сетевой модели можно непосредственно организовать связь «многие к одному» и «многие ко многим». По сравнению с иерархической моделью расширено понятие главного и подчиненного объекта. Аналогично иерархической модели, при работе с данными осуществляется обход сети. Но канонического алгоритма обхода нет, т.к. сеть имеет произвольную конфигурацию.
Большое внимание к сетевой модели возникло после публикации работ DBTG CODASYL (DBTG – Data Base Task Group, CODASYL – Conference on Data System Languages). В одном из отчетов этой неформальной организации была предложена спецификация, на основе которой по настоящее время создаются все СУБД, поддерживающие сетевую модель данных.
Основными компонентами сетевой модели являются – записи (узлы графа) и наборы (дуги). Графически все это представляется с помощью диаграмм Бахмана (рис. 3.2). Записи – прямоугольники, наборы – стрелки. Аналогично иерархической модели различают тип и экземпляр записи. Описание происходит на уровне типов. Поиск ведется на уровне экземпляров. Стрелка определяет тип набора. По сути, это имя связи, установленной между данными. Тип записи, откуда выходит стрелка – владелец набора, тип записи, куда входит стрелка – член набора. Одни и те же типы данных могут участвовать в произвольном количестве связей, т.е. между двумя типами записей может быть произвольное количество наборов. Запись может быть владельцем одного набора и членом другого.

На уровне экземпляров связь реализуется закольцованной цепью (рис. 3.3). Для реализации на уровне экземпляров в сетевой модели должно поддерживаться правило уникальности владения – экземпляр члена может иметь только одного владельца (рис. 3.4).

Рис. 3.3. Реализация на уровне экземпляров

Рис. 3.4. Правило уникальности владения
Кроме операций с узлами сети (найти, изменить, создать) имеются операции с дугами (присоединить запись к набору, отсоединить запись от набора).
Сетевую модель данных отличает наличие успешно действующих СУБД, естественность реализации связи «многие ко многим», гибкость, возможность построения структуры данных любой сложности, эффективность реализации. Однако эта модель является самой сложной с точки зрения проектирования базы данных и программирования приложений.
3.3. Реляционная модель данных
Среди множества существующих моделей данных наибольшую популярность и развитие получила реляционная модель. Она отличается строгим математическим обоснованием, которое позволило, с одной стороны, подвести научный базис под языки манипулирования данными, с другой стороны получить строгую, научно обоснованную методологию проектирования корректных баз данных. Реляционная модель данных была предложена Э. Коддом в публикациях 1970 г. и 1979 г. Подавляющее большинство современных СУБД поддерживает именно эту модель данных.
База данных в реляционной модели представляется совокупностью плоских двумерных таблиц. Эти таблицы имеют следующие свойства:
- Каждый элемент таблицы – один элемент данных;
- Все столбцы таблицы однородны, т.е. все элементы столбца имеют одинаковую природу;
- Столбцы однозначно именуются;
- В таблице нет двух одинаковых строк;
- Строки и столбцы могут просматриваться в любом порядке.
Соблюдение всех свойств, за исключением свойства 4, обеспечивает по умолчанию любая реляционная СУБД. Свойство 4 направлено на то, чтобы все строки таблицы были различимы. Однако на практике возможны случаи одинаковых строк. Поэтому СУБД соблюдение этого свойства не контролируют. При необходимости его соблюдение обеспечивается соответствующим проектированием структуры таблицы. Проектирование таблиц с данным свойством будет рассмотрено ниже. Таблица в реляционной модели называется отношением (relation). Можно дать два определения отношения.
- Пусть дана совокупность множеств
 , не обязательно различных. ОтношениеR, определенное на этих n множествах, есть множество упорядоченных кортежей , что. Множество– домены отношенияR, n – степень отношения R (число столбцов таблицы). Количество кортежей (строк) – мощность (кардинальное число) отношения R.
, не обязательно различных. ОтношениеR, определенное на этих n множествах, есть множество упорядоченных кортежей , что. Множество– домены отношенияR, n – степень отношения R (число столбцов таблицы). Количество кортежей (строк) – мощность (кардинальное число) отношения R.
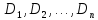 , не обязательно различных. ОтношениеR, определенное на этих n множествах, есть множество упорядоченных кортежей
, не обязательно различных. ОтношениеR, определенное на этих n множествах, есть множество упорядоченных кортежей 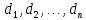 , что
, что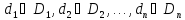 . Множество
. Множество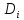 – домены отношенияR, n – степень отношения R (число столбцов таблицы). Количество кортежей (строк) – мощность (кардинальное число) отношения R.
– домены отношенияR, n – степень отношения R (число столбцов таблицы). Количество кортежей (строк) – мощность (кардинальное число) отношения R. 2. R – подмножество декартова произведения доменов 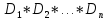 . Использование понятия подмножества во втором определении связано с тем, что не все кортежи, порождаемые операцией декартова произведения, имеют смысл для данного отношения. Различают понятие домена и атрибута. Атрибут – подмножество значений домена, имеющее смысл для данной предметной области. Например, домен ВИД ТРАНСПОРТА может содержать значения, соответствующие любым видам транспорта, которые применялись где-либо когда-либо. Атрибут, возможно, с тем же именем, будет содержать виды транспорта, использующиеся на предприятии для доставки продукции, если отношение относится к службе доставки. Если отношение относится к подсистеме учета командировочных расходов, такой атрибут будет содержать виды транспорта, использующиеся для поездок в командировки. Отношения записывается в виде схемы отношения: R(A1 A2 … An), где R – имя отношения (имя таблицы); Ai – имена атрибутов. Домены и соответствующие им атрибуты могут быть простыми и составными. Простой домен – атомарный (неделимый), сложный или составной домен – иерархическая структура внутри таблицы (рис. 3.5).
. Использование понятия подмножества во втором определении связано с тем, что не все кортежи, порождаемые операцией декартова произведения, имеют смысл для данного отношения. Различают понятие домена и атрибута. Атрибут – подмножество значений домена, имеющее смысл для данной предметной области. Например, домен ВИД ТРАНСПОРТА может содержать значения, соответствующие любым видам транспорта, которые применялись где-либо когда-либо. Атрибут, возможно, с тем же именем, будет содержать виды транспорта, использующиеся на предприятии для доставки продукции, если отношение относится к службе доставки. Если отношение относится к подсистеме учета командировочных расходов, такой атрибут будет содержать виды транспорта, использующиеся для поездок в командировки. Отношения записывается в виде схемы отношения: R(A1 A2 … An), где R – имя отношения (имя таблицы); Ai – имена атрибутов. Домены и соответствующие им атрибуты могут быть простыми и составными. Простой домен – атомарный (неделимый), сложный или составной домен – иерархическая структура внутри таблицы (рис. 3.5).  Рис. 3.5. Простой и составной домен На начальном этапе проектирования при постановке задачи таблицы вида рис. 3.5 допускаются.
Рис. 3.5. Простой и составной домен На начальном этапе проектирования при постановке задачи таблицы вида рис. 3.5 допускаются.