2.2.2 Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
- каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L;
- каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L
Плюсы сетевой модели данных:
Минусы сетевой модели данных:
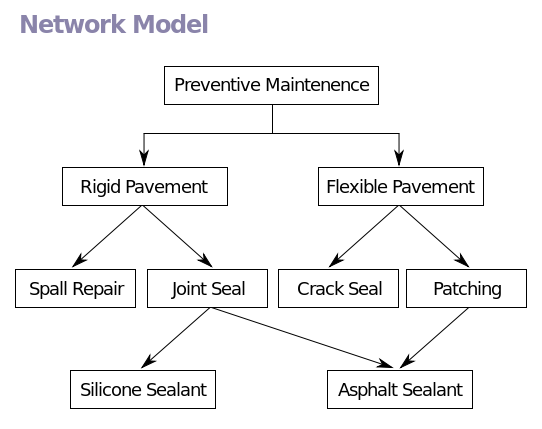
П ример сетевой модели приведен на рисунке 6:
Рисунок 6 – Сетевая модель данных
2.2.3 Объектно-ориентированная модель данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма.
Плюсы объектно-ориентированной модели:
- Возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Минусы объектно-ориентированной модели:
- Высокая понятийная сложность
- Неудобство обработки данных
- Низкая скорость выполнения запросов
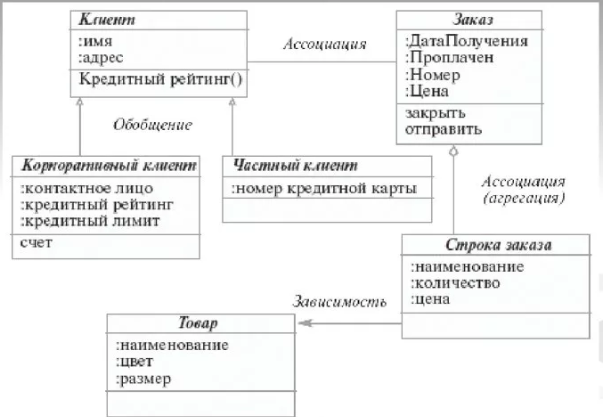
Пример объектно-ориентированной модели приведен на рисунке 7:
Рисунок 7 – Объектно-ориентированная модель данных
2.2.4 Реляционная модель данных
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation — «отношение»).
Реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Ограничения реляционной модели:
- Должны отсутствовать записи-дубликаты
- Столбцы реляционной таблицы поименованы, поэтому их порядок не важен.
- Порядок записей может быть произвольным
- Каждая запись уникальна и однозначно определяется значением ключа.
- Каждый элемент таблицы называется полем, может быть однозначно определен.
- В столбце записываются данные одного типа
Недостатки традиционных реляционных моделей:
- Избыточность по полям (из-за создания связей)
- В качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
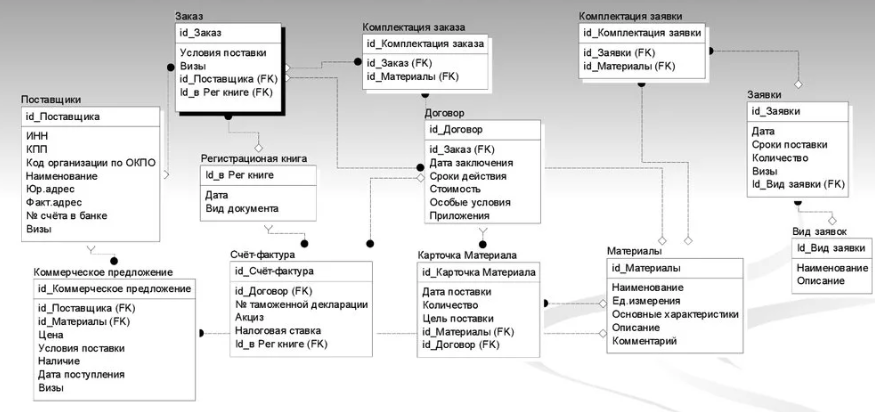
П ример реляционной модели приведен на рисунке 8:
Рисунок 8 – Реляционная модель данных
7.2.2. Сетевая модель данных
В сетевой модели при тех же основных понятиях (уровень, узел, связь) каждый порожденный элемент может быть иметь более одного порождающего элемента.
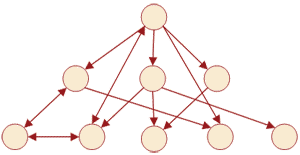
Рис. 7.2.2.1. Сетевая модель данных
Сетевая модель отличается большей гибкостью, чем иерархическая, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска требуемых элементов данных, так как уже не требуется обязательное прохождение всех предшествующих ступеней.
Примером сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС.

Рис. 7.2.2.2. Принцип построения сетевой модели организации БД.
7.2.3. Реляционная модель данных
Можно доказать, что и иерархическую, и сетевую структуры данных можно преобразовать в двумерную таблицу. Такое представление является наиболее удобным и для пользователя, и для компьютера, – подавляющее большинство современных информационных систем работает именно с такими таблицами. Базы данных, которые состоят из двумерных таблиц, называют реляционными.
Основная идея реляционного подхода состоит в том, чтобы представить произвольную структуру данных в виде двумерной таблицы или, как говорят, нормализовать структуру. Нормализация – это процесс прохода по веткам иерархического дерева с целью разместить листочки» со всеми их узлами и ветками в отдельных строках таблицы.
Основы теории реляционных БД разработал в 70-х годах XX века Э.Кодд (США).
Основными понятиями реляционной модели данных являются сущность, отношение, атрибут и кортеж.
Сущность – это конкретный объект реального мира в какой-либо предметной области. т.е. объектом можно назвать то «нечто», для которого существуют название и способ отличить один подобный объект от другого. Например, каждый ВУЗ – это объект. Объектами также являются человек, фирма, сплав, химическое соединение и т. д. Объектами могут быть не только материальные предметы, но и более абстрактные понятия, отражающие реальный мир, например, события, произведения искусства, правовые нормы, научные теории и пр.
Группы всех подобных объектов образует набор объектов. Например, наборами объектов могут быть факультеты ВУЗа, товары на складе, люди, работающие на предприятии. Конкретный объект в такой группе называют экземпляром объекта.
Данные о сущности хранятся в двумерных таблицах, которые называются реляционными. Формальное построение таблиц связано с фундаментальным понятием отношение (от английского слова relation – отношение).
Каждая строка таблицы представляет собой одну запись файла данных, каждый столбец – одно поле.

Рис. 7.2.3.1. Структура табоицы базы данных
Атрибут (или данное) – это некоторый показатель, который характеризует некий объект и принимает для конкретного экземпляра объекта некоторое числовое, текстовое или иное значение. Например, возьмем в качестве набора объектов группы факультета. Число студентов в группе – это атрибут, который принимает числовые значения (у одной группы 25, у другой 18). Название группы – это атрибут, который принимает текстовые значения (у одной – ФК-11, у другой – ЭКО-12 и т.д.).
Очень часто в современных информационных системах используются «качественные» данные об объектах, например рейтинг (фильма, спортсмена, политика), увлечения человека, его темперамент.
Атрибут некоторого набора объектов сам может быть набором объектов, имеющим собственные атрибуты. Например, атрибутом человека (как экземпляра набора объектов «Люди») является ВУЗ, который этот человек окончил (МГУ, МарГТУ и т.п.). С другой стороны, конкретный ВУЗ – это экземпляр набора объектов «Вузы» и характеризуется множеством данных: фамилия ректора, адресом, специализацией, количеством студентов и т.д. Наконец, ректор, в свою очередь – это экземпляр набора объектов «Люди». Таким образом, возникает возможность установления связи между экземплярами объектов из разных наборов.
Списки возможных значений атрибутов называются классификаторами (справочниками, словарями). Например, страна, гражданином которой является конкретное лицо, служит атрибутом этого лица. Список всех стран планеты – это и есть классификатор, из которого выбирают значение атрибута для конкретного лица.
Иногда для конкретного объекта один и тот же атрибут может принимать несколько значений. Например, одна фирма изготавливает разные виды продукции, один человек может иметь несколько увлечений и т. п. Такие данные образуют так называемые повторяющиеся группы.
Значения некоторых данных постоянны у конкретных объектов (например, год рождения человека); значения других могут меняться с течением времени (например, образование человека, его должность, число работающих на предприятии и т.п.).
Кортеж – это элемент отношения , строка таблицы; упорядоченный набор из N элементов.
Хотя любое отношение можно изобразить в виде таблицы, нужно четко понимать, что отношения не являются таблицами. Это близкие, но не совпадающие понятия. Термины, которыми оперирует реляционная модель данных, имеют соответствующие «табличные» синонимы:
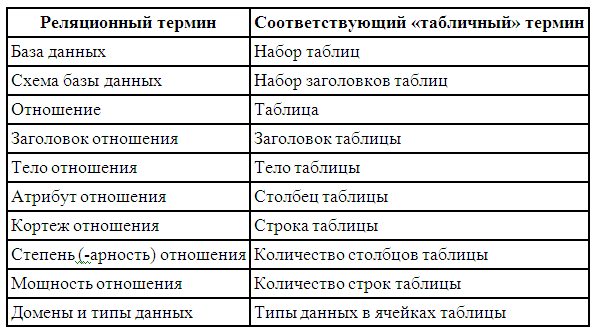
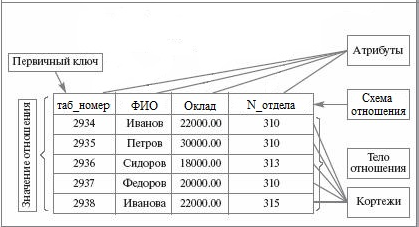
Рис. 7.2.3.2. Основные понятия баз данных
- В отношении нет одинаковых кортежей.
- Кортежи не упорядочены (сверху вниз).
- Все атрибуты содержат однородные по типу данные.
- Имена атрибутов должны быть уникальны в пределах отношения.
- Атрибуты не упорядочены (слева направо).