Лекция 8 Типы моделей данных
Ядром любой базы данных является модель данных. Модель данных- совокупность структур данных и операций их обработки.
По способу установления связей между данными различают иерархическую, сетевую и реляционную модель.
Иерархическая модель данных
Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево), вид которого представлен на рисунке. 21.
К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей.
К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Например, как видно из рис. 21 для записи С4 путь проходит через записи А и ВЗ.

Рис.21 Графическое изображение иерархической структуры БД
Пример. Пример, представленный на рис. 15.9, иллюстрирует использование иерархической модели базы данных.Для рассматриваемого примера иерархическая структура правомерна, так как каждый студент учится в определенной (только одной) группе, которая относится к определенному (только одному) институту

Рис. 22. Пример иерархической структуры БД
Сетевая модель данных
В сетевой структуре при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. На рис. 23 изображена сетевая структура базы данных в виде графа.
Пример. Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС. Графическое изображение описанной в примере сетевой структуры, состоящей только из двух типов записей, показано на рис. 24. Единственное отношение представляет собой сложную связь между записями в обоих направлениях.
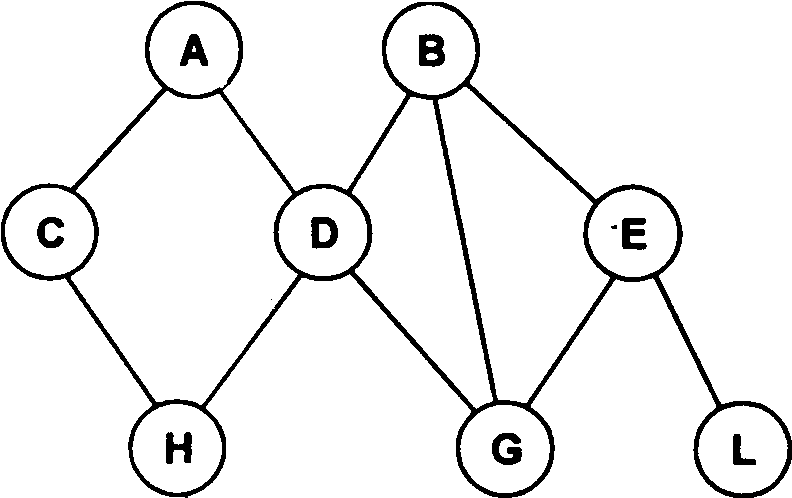
Рис. 23. Графическое изображение сетевой структуры
Студент (номер зачетной книжки, фамилия, группа)
Три типа логических моделей баз данных: иерархическая, сетевая, реляционная
Различают три класса (модели) организации баз данных: иерархические, сетевые и реляционные. Термин «модель» в данном случае рассматривается как структура, позволяющая количественно и качественно оценивать на логическом уровне организацию хранения и доступа к данным.
Иерархическая модель данных. Иерархическая модель данных как следует из названия, имеет иерархическую структуру, т.е. каждый из элементов связан только с одним стоящим выше элементом, но в то же время на него могут ссылаться один или несколько стоящих ниже элементов.
Рис.1.1. Иерархическая модель данных
В терминологии иерархической модели используются более конкретные понятия «элемент» (узел), «уровень» и «связь». Уровень чаще всего представляет собой атрибут (признак) описывающий некоторый объект. Иерархически модель изображается в виде строго упорядоченного графа, в котором каждый узел является вершиной. Эта модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих граф – дерево с иерархической структурой. Такой граф имеет единственную вершину, не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Число вершин первого уровня определяет число деревьев в базе данных.
Сетевая модель данных. Эта модель использует ту же терминологию, что и иерархическая модель: «узел», «связь», «уровень». Единственное отличие между иерархической и сетевой моделями данных заключается в том, что в последней каждый элемент данных (узел) может быть связан с любым другим элементом (узлом) (рис.1.2). Как известно из теории графов, сетевой граф может быть преобразован в граф-дерево.
Рис.1.2 Сетевая модель данных
Реляционная модель данных. Основная идея реляционной модели данных заключается в том, чтобы представить любой набор данных в виде двумерного массива – таблицы (табл.1.1)
Детали приборов
В простейшем случае реляционная модель описывает единственную двумерную таблицу, но чаще эта модель описывает структуру и взаимоотношения между несколькими различными таблицами.
Реляционные модели данных, или реляционные базы данных, являются в настоящее время основным способом в проектировании и организации информационных систем в производстве и бизнесе, поэтому мы рассмотрим теоретические основы и практические методы разработки реляционных баз данных.
Постреляционная модель. Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Существует ряд случаев, когда это отношение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
Для сравнения рассмотрим представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей на примере информации о накладных и товарах (рис.1).
Таблица INVOICES содержи данные о номерах накладных (INVNO) и номерах покупателей (CUSTNO). В таблице INVOICE.ITEMS содержатся данные о каждой из накладных: номер накладной, название товара и количество товара. Таблица INVOICES связана с таблицей INVOICE.ITEMS по полю INVNO.
Как видно из таблиц, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке требуется выполнять операцию соединения данных из двух таблиц.
Помимо обеспечения вложенности полей Постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов.
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость.
Поскольку Постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности её обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Рассмотренная постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся системы Bubba и Dasdb.
Объектно-ориентированные базы данных применяются с конца 1980-х для обеспечения управления базами данных приложениями, построенными в соответствии с концепцией объектно-ориентированного программирования. Объектная технология расширяет традиционную методику разработки приложений новым моделированием данных и методами программирования. Для повторного использования кода и улучшения сохранности целостности данных в объектном программировании данные и код для их обработки организованы в объекты. Таким образом, практически полностью снимаются ограничения на типы данных.
Если данные состоят из коротких, простых полей фиксированной длины (имя, адрес, баланс банковского счета), то лучшим решением будет применение реляционной базы данных. Если, однако, данные содержат вложенную структуру, динамически изменяемый размер, определяемые пользователем произвольные структуры (мультимедиа, например), представление их в табличной форме будет, как минимум, непростым. В то же время в ООСУБД каждая определенная пользователем структура – это объект, непосредственно управляемый базой данных.
В РСУБД связи управляются пользователем, создающим внешние ключи. Затем для обнаружения связей динамически во время выполнения система просматривает две (или больше) таблицы, сравнивая внешние ключи до достижения соответствия. Этот процесс, называемый объединением (join), является слабой стороной реляционной технологии. Более двух или трех уровней объединений – сигнал, чтобы искать лучшее решение. В ООСУБД пользователь просто объявляет связь, и СУБД автоматически генерирует методы управления, динамически создавая, удаляя и пересекая связи. Ссылки при этом прямые, нет необходимости в просмотре и сравнении или даже поиске индекса, который может сильно сказаться на производительности. Таким образом, применение объектной модели предпочтительнее для баз данных с большим количеством сложных связей: перекрестных ссылок, ссылок, связывающих несколько объектов с несколькими (many-to-many relationships) двунаправленными ссылками.
В отличие от реляционных, ООСУБД полностью поддерживают объектно-ориентированные языки программирования. Разработчики, применяющие С++ или Smalltalk, имеют дело с одним набором правил (позволяющих использовать такие преимущества объектной технологии, как наследование, инкапсуляция и полиморфизм). Разработчик не должен прибегать к трансляции объектной модели в реляционную и обратно. Прикладные программы обращаются и функционируют с объектами, сохраненными в базе данных, которая использует стандартную объектно-ориентированную семантику языка и операции. Напротив, реляционная база данных требует, чтобы разработчик транслировал объектную модель к поддерживаемой модели данных и включил подпрограммы, чтобы обеспечить это отображение во время выполнения. Следствием являются дополнительные усилия при разработке и уменьшение эффективности.
И, наконец, ООСУБД подходят (опять же без трансляций между объектной и реляционной моделями) для организации распределенных вычислений. Традиционные базы данных (в том числе и реляционные и некоторые объектные) построены вокруг центрального сервера, выполняющего все операции над базой. По существу, эта модель мало отличается от мэйнфреймовой организации 60-х годов с центральной ЭВМ – мэйнфреймом (mainframe), выполняющей все вычисления, и пассивных терминалов. Такая архитектура имеет ряд недостатков, главным из которых является вопрос масштабируемости. В настоящее время рабочие станции (клиенты) имеют вычислительную мощность порядка 30 — 50 % мощности сервера базы данных, то есть большая часть вычислительных ресурсов распределена среди клиентов. Поэтому все больше приложений, и в первую очередь базы данных и средства принятия решений, работают в распределенных средах, в которых объекты (объектные программные компоненты) распределены по многим рабочим станциям и серверам и где любой пользователь может получить доступ к любому объекту. Благодаря стандартам межкомпонентного взаимодействия (об этом позже) все эти фрагменты кода комбинируются друг с другом независимо от аппаратного, программного обеспечения, операционных систем, сетей, компиляторов, языков программирования, различных средств организации запросов и формирования отчетов и динамически изменяются при манипулировании объектами без потери работоспособности