- Команда wc в Linux
- Синтаксис команды wc
- Применение команды wc
- Вывод
- Узнать количество строк в файле Linux
- Подсчет строк, слов и знаков с помощью wc
- Подсчёт данных в выводе командной строки Linux
- Поиск количества файлов в директории Linux
- Подсчет уникальных строк и дубликатов в текстовом файле Linux
- Подсчитать количество строк в файле Linux
- Количество строк в файле Linux
- Как узнать количество строк в файле Linux
- Выводы
- 8 Ways to Count Lines in a File in Linux
- The concept of Data Streams and Piping
- Data streams
- Piping
- Ways to Count Lines in a File in Linux
- WC
Команда wc в Linux
Анализ файлов — неотъемлемая часть работы с ними. Иногда возникает необходимость подсчитать количество строк или слов в тексте. С этой задачей эффективно справляется команда wc Linux.
Утилита устанавливается по умолчанию практически во всех дистрибутивах GNU/Linux. В этой статье рассмотрим её функции и применение на практике.
Синтаксис команды wc
Для запуска утилиты откройте терминал и введите:
Терминал будет ожидать ввода данных. После нажатия комбинации клавиш Ctrl + D командный интерпретатор завершит работу программы и выведет три числа, обозначающих количество строк, слов и байт введённой информации.
Утилита может обрабатывать файлы. Стандартная инструкция выглядит так:
Программа также может принимать параметры для анализа отдельных значений. Наиболее используемые из них приведены в таблице ниже:
| Параметр | Длинный вариант | Значение |
| -c | —bytes | Отобразить размер объекта в байтах |
| -m | —count | Показать количесто символов в объекте |
| -l | —lines | Вывести количество строк в объекте |
| -w | —words | Отобразить количество слов в объекте |
Под объектом следует понимать файл или данные, полученные на стандартный поток ввода.
Команда может обработать несколько файлов, если указать их через пробел или выбрать по шаблону.
Применение команды wc
Обработка стандартного потока ввода с завершением через Ctrl + D:

Согласно анализу, было введено 4 строки, содержащих 5 слов, объёмом в 35 байт.
Перенаправление потока вывода на вход wc:

Обработка всех файлов с расширением .sh в текущем каталоге:

В конце выводится итоговая информация, суммирующая значения для каждого столбца.
Выведем только количество символов и строк двух файлов:
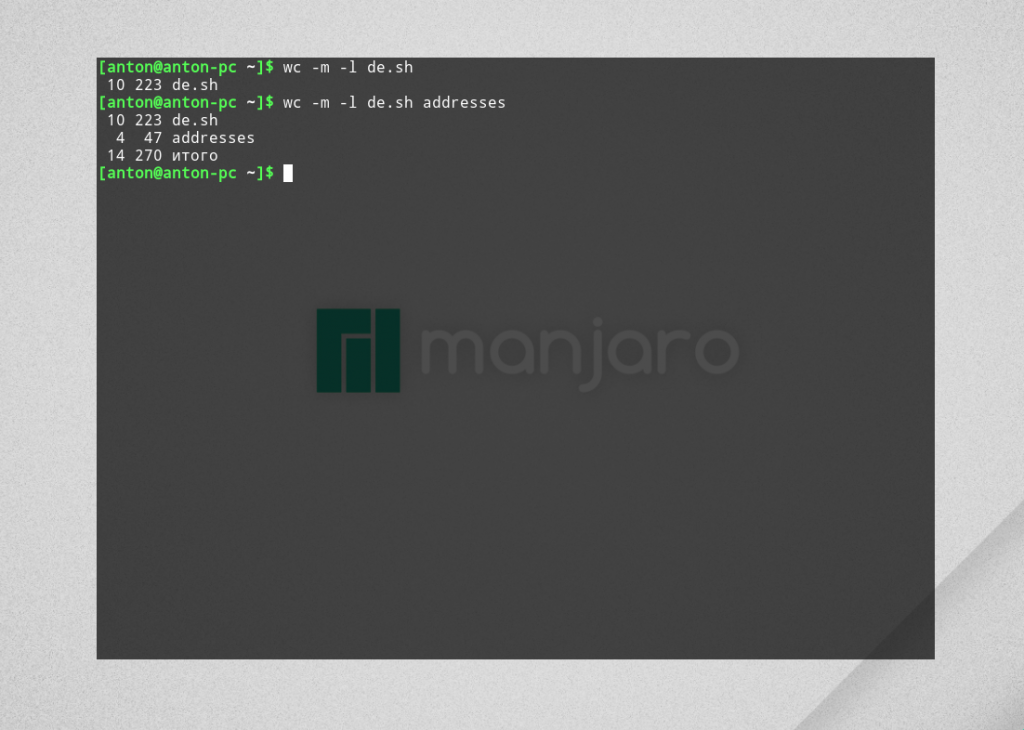
Обратите внимание: порядок указания параметров не влияет на итоговый вид информации. Программа всегда выводит данные в виде СТРОК — СЛОВ — БАЙТ (СИМВОЛОВ) [— ФАЙЛ]. Если какой-то параметр будет отсутствовать, его столбец просто проигнорируется, не задевая остальные. Количество символов будет стоять первым, если в команде содержался и вывод байт.
Вывод
Команда wc Linux является эффективным инструментом при анализе файлов в GNU/Linux. Она может обрабатывать как стандартный поток ввода, так и несколько файлов одновременно. Для извлечения конкретных данных используются параметры командной строки.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
Узнать количество строк в файле Linux
Довольно частенько нужно подсчитать количество файлов при выводе в консоли BASH. Хорошо если файлов 10 единиц. Как быть если их сотни и у каждого файла сложное имя. Тут идеально подойдёт команда wc. Её наилучше использовать вместе с фильтром. Например с командой grep команда wc хорошо сочетается. Возможно подсчитать количество слов в документе.
С помощью команды wc вы можете подсчитать количество строк, слов и символов в указанном файле. Если указано более одного файла в инструктивной строке, то программа wc осуществляет подсчет строк, слов и символов в каждом файле и потом выдает общее число. Вы можете с помощью ключей указать либо подсчет лишь строк, или только слов, или символов. Синтаксис команды:
Подсчет строк, слов и знаков с помощью wc
Система отвечает строкой в следующем формате: l w c файл
где l — число строчек в файле;
w — число слов в файле;
c — число символов в файле.
Чтобы подсчитать количество строк, слов и символов в нескольких файлах, используйте следующий формат:
Система говорит следующим образом:
l w c файл1
l w c файл2
l w c total
Число строк, слов и символов для файл1 и файл2 отражается на отдельных строках. На последней строке отображается общее число строк, слов и знаков в двух файлах.
Подсчет данных в документе
wc text.txt
вывод: 40 149 947 text.txt
В первоначальной колонке содержится количество строк, во второй кол-во слов, в третьей кол-во знаков
wc -l file.txt #вывести количество строк (ряд знаков, написанных или напечатанных в одну линию)
wc -c file.txt #вывести количество байт
wc -m file.txt #вывести число символов
wc -L file.txt #вывести длину самой длинной строки
wc -w file.txt #вывести число слов
Подсчёт данных в выводе командной строки Linux
Подсчет количества .txt-файлов в текущем каталоге с помощью wc:
При выводе в инструктивной строке очень часто попадают файлы с точками вместо имён .. или . .Тут необходимо отфильтровать вывод и только потом применять команду wc. Как подсчитать количество файлов в папки. Тут добавлена сортировка и удаление дублей. uniq — убирает дубли, перед unic обязана идти сортировка sort
Поиск количества файлов в директории Linux
ls | grep «name» | sort | uniq | wc -l
Подсчет уникальных строк и дубликатов в текстовом файле Linux
Буквально сегодня на работе столкнулся с довольно простой задачей, состоящей из двух подзадач: 1) нужно было подсчитать в текстовом файле количество уникальных строк 2) подсчитать в уже другом файле количество строчек, которые дублируются.
С этими задачами я справился и после этого подумал — по какой причине бы не написать небольшой пост, вдруг кому-нибудь пригодится. Подсчитаем в нём количество уникальных строчек с помощью следующей команды:
$ sort data.txt | uniq -u | wc -l
Всё достаточно просто. Утилита uniq с функцией -u выводит на экран уникальные строки (u—unique, видимо так) и с помощью | результат перенаправляется в утилиту wc , какая просто считает количество строк, т.к. исполняется с опцией -l. В самом начале нам необходимо просортировать входной поток данных (текстовый файл), иначе утилита uniq не сможет правильно подсчитать уникальные строки. Выполняется сортировка с помощью sort и результат, используя |, перенаправляется в uniq. После исполнения такой команды для файла data.txt на экран будет выведено число 5.
Для этого чтобы решить вторую подзадачу, сделаем всё тоже самое, только uniq станет выполнен с опцией -d (видимо d—duplicate):
$ sort data.txt | uniq -d | wc -l
В результате на экран выведено количество 2. Обе подзадачи решены достаточно простым способом. Записал небольшую демонстрацию кому забавно.
Подсчитать количество строк в файле Linux
Нет ничего проще, чем подсчитать количество строчек в файле.
Подсчитать общее количество строк в файлах (именованная область данных на носителе информации) по шаблону. Если же вам необходимо подсчитать количество строк нескольких файлов, можете использовать шаблон, например:
Количество строк в файле Linux
Несмотря на то, что утилиты с графическим интерфейсом гораздо удобнее в использовании и адаптированы под высокие разрешения, в терминале можно делать многие вещи гораздо быстрее. Например, утилита wc просто подсчитывает количество строк в файле.
Но само количество строк мало о чём говорит, поэтому совмещение нескольких команд позволяет считать строки с учётом требуемых параметров. Мы рассмотрим несколько примеров как подсчитать количество строк в файле linux с использованием таких команд, как grep, sed и awk.
Как узнать количество строк в файле Linux
Команду wc мы уже рассматривали, нас интересует только параметр -l. В общем случае он считает количество переходов на новую строку, поэтому учитываются все строки, в том числе пустые. С этой задачей она справится быстрее остальных команд, таких как grep, sed, awk. Но эти команды способны подсчитать строки с заданным условием.
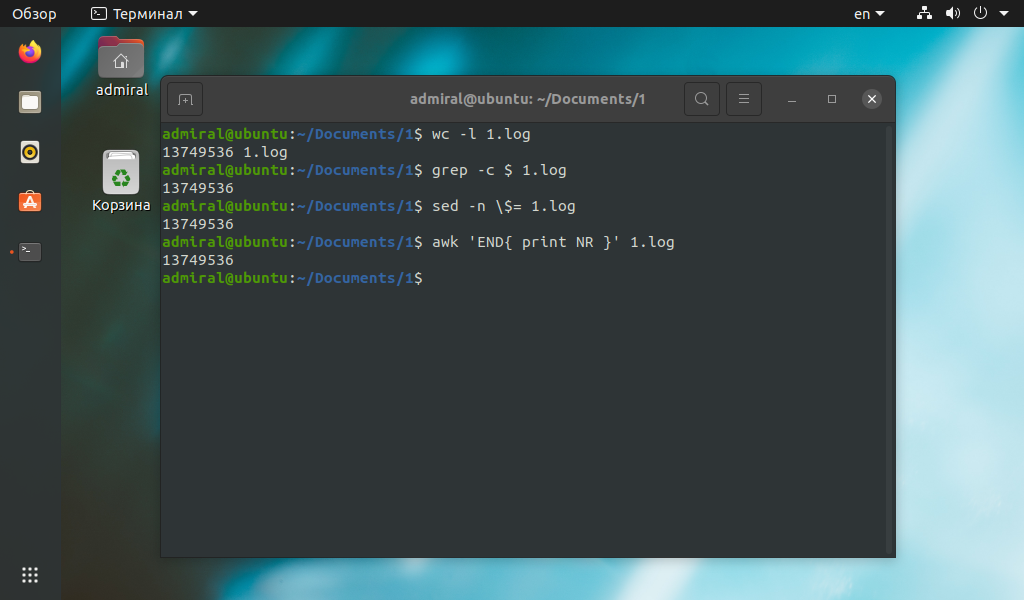
Как видите, результат один и тот же, только вот команда wc потратила на порядок меньше времени. Поэтому остальные команды стоит использовать для более сложных запросов. Рассмотрим несколько примеров.
Команда grep поможет найти строки только с нужным текстом:
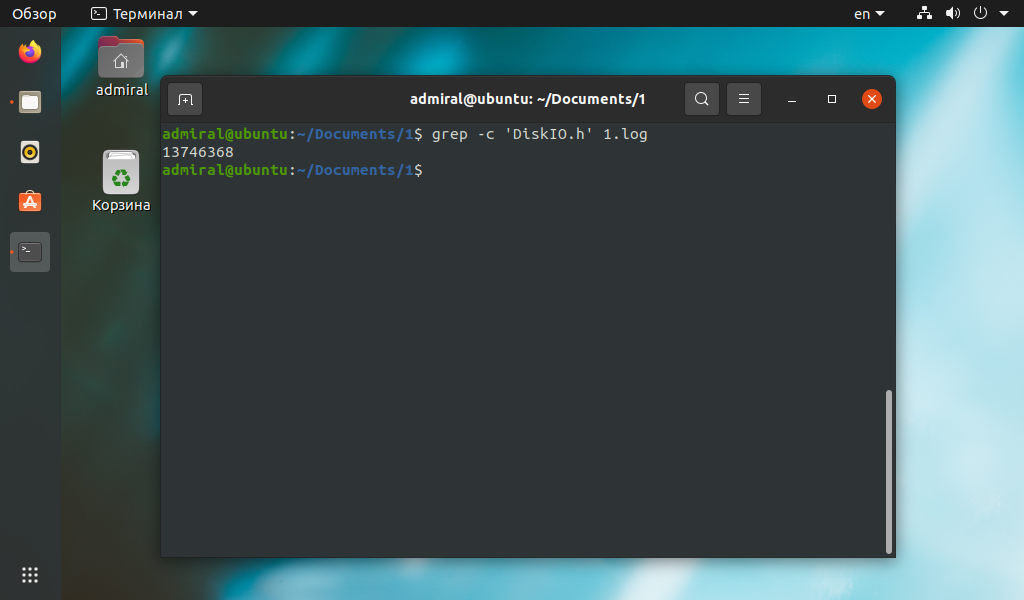
Команда grep умеет работать с регулярными выражениями и объединять условия с помощью операторов И, ИЛИ, НЕ.
Команда sed умеет обрабатывать текст, но проще всего посчитать количество результирующих строк командой wc. Например, можно удалить все строки длиной менее 3 символов, а в более сложных случаях подсчитать количество строк без комментариев.
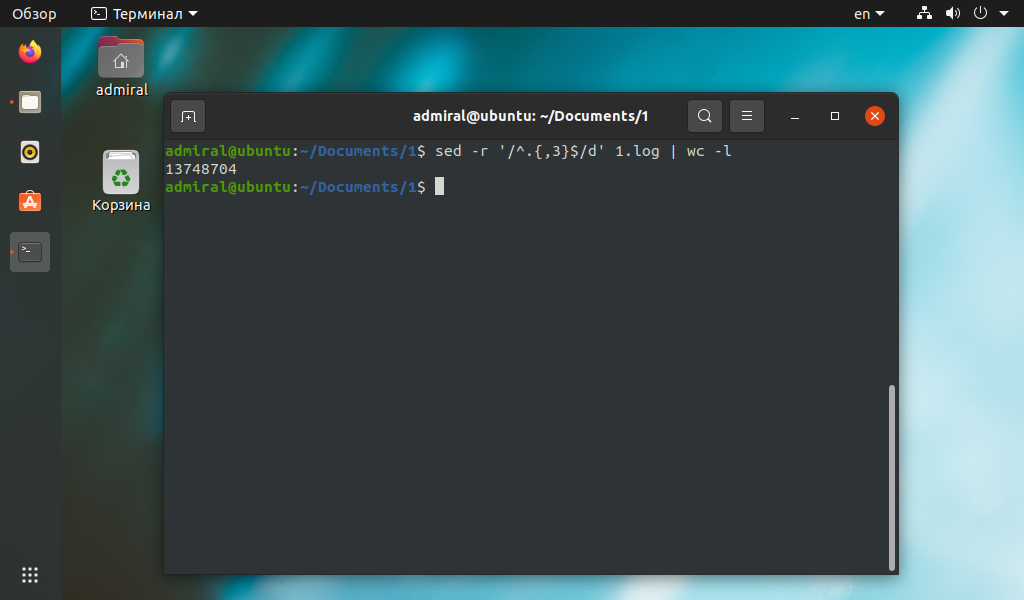
Столь простой пример можно было выполнить и другими командами. Синтаксис команды awk в этом случае гораздо понятнее.
awk ‘length >3’ имя_файла | wc -l
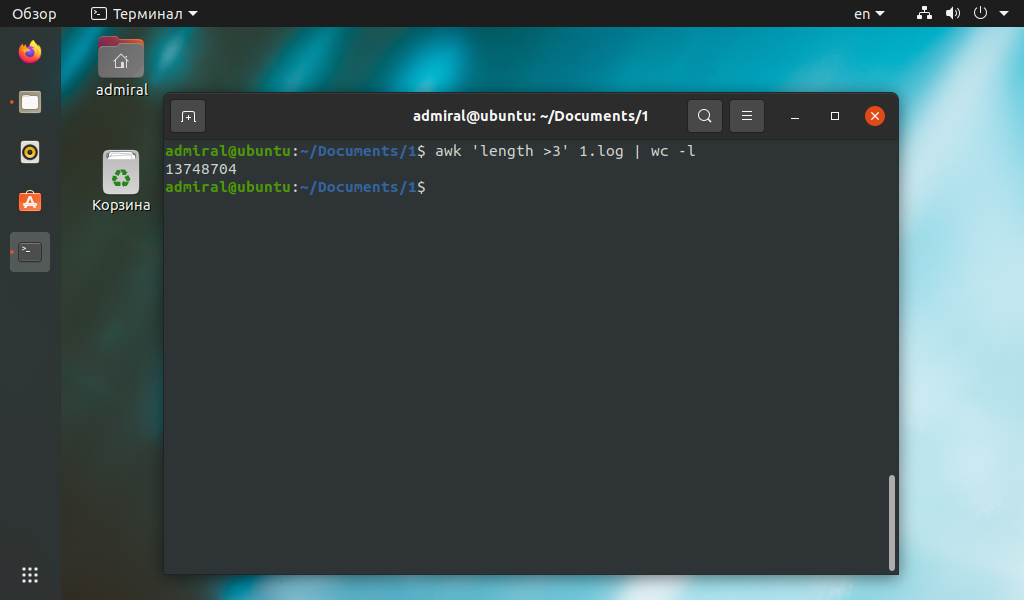
Другим примером использования команды awk может стать подсчёт строк с поиском нужного значения в табличном файле csv. В этом примере мы подсчитали количество строк, у которых значение второго параметра больше 50.
awk ‘$2+0 > 50’ имя_файла | wc -l
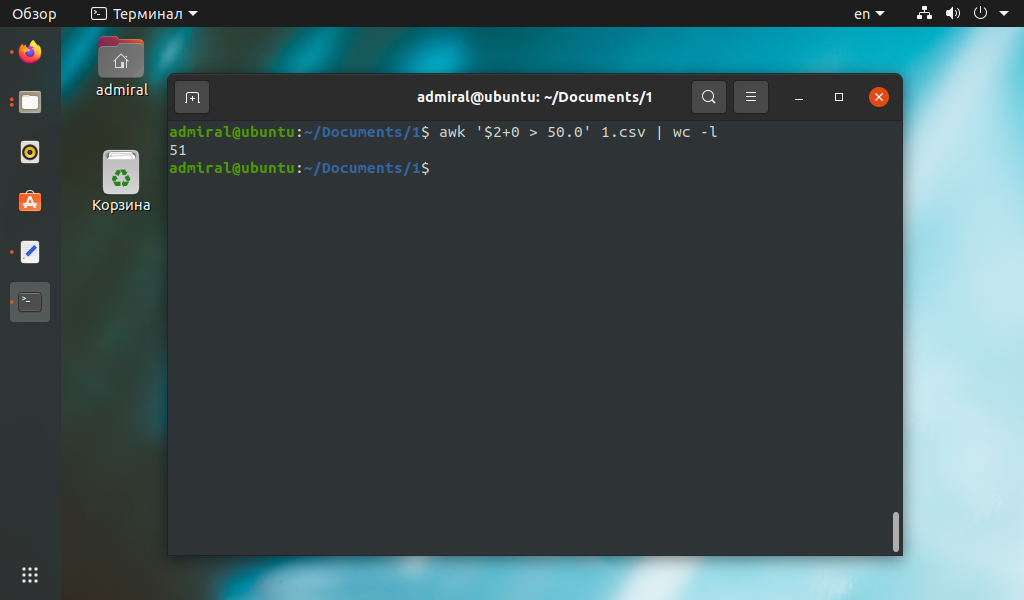
Мы добавили 0 к выражению неспроста, он позволяет отсеять нечисловые выражения.
Выводы
Теперь вы знаете как посчитать количество строк в файле linux. К плюсам подсчёта количества строк с помощью консольных команд можно отнести универсальность и скорость работы. Мы рассмотрели далеко не все команды, способные подсчитать количество строк, есть tr, nl, не говоря уже о языках программирования, вроде PERL. Но имеются и существенные минусы, например, сложный синтаксис регулярных выражений, внести изменения в команду порой сложнее, чем написать её заново.
Если правильно подойти к подсчёту строк, то он может стать основой для сбора статистики и оценки файлов. Как вы могли убедиться, одну и ту же задачу можно выполнить нескольким способами, поэтому выбирайте наиболее подходящую команду.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
8 Ways to Count Lines in a File in Linux
![wc -l < [filename] on a green background](https://bytexd.com/wp-content/uploads/2022/06/8-Ways-to-Count-Lines-in-a-File-in-Linux-800x500.png)
Counting lines in a Linux file can be hectic if you don’t know the applicable commands and how to combine them. This tutorial makes the process comfortable by walking you through eight typical commands to count lines in a file in Linux.
For example, the word count, wc , command’s primary role, as the name suggests, is to count words. However, since a group of words forms a line, you can use the command to count lines besides characters and words.
All you do is redirect the input of a file to the command alongside the -l flag.
Apart from the wc , you can use the awk, sed, grep, nl , pr , cat and perl commands. Before that, it would help to understand data streams and piping in Linux.
Table of Contents
The concept of Data Streams and Piping
Data streams
Three files come together to complete the request when you run a command: standard input, standard output, and error files.
The standard input, abbreviated as stdin and redirected as < , feeds the computer with data. The standard output, abbreviated as stdout and redirected as >, shows the result of running a command. If an error occurs when processing the result, we see the standard error, often abbreviated as stderr .
The primary stdin is the keyboard, while the stdout is the (monitor) screen. However, due to the flexibility of Linux and the fact that everything in Linux is a file, we can change the stdin , stdout , or stderr to suit our needs, as you will see when counting lines with the wc command.
Before that, you should understand the concept of piping in Linux.
Piping
Piping in Linux, denoted by | , means running two or more commands simultaneously on the terminal. For example, we can cat a file, let’s call the file index.txt . But instead of waiting to see the output, we redirect it to the sort command, which outputs the data alphabetically.
Now that you understand the main concepts applied when customizing a file’s input to get the number of lines, let’s see eight ways to count lines in a file in Linux.
Ways to Count Lines in a File in Linux
WC
The wc command returns a file’s line numbers, words, and characters, respectively.
Let’s create a file, practice.txt , and append the following lines.
We are counting file lines. We use the wc, awk, sed, grep, and perl commands. The process is easy because we can redirect ouptut and pipe commands. Linux is becoming fun!
Running the wc command on the file, we get the following output:
Likewise, we can control the output using specific flags with the input redirection symbol.