Read line by line in Bash script
The best way to do this is to redirect the file into the loop:
# Basic idea. Keep reading for improvements. FILE=test while read CMD; do echo "$CMD" done < "$FILE" There are some additional improvements that could be made:
- Add IFS= so that read won't trim leading and trailing whitespace from each line.
- Add -r to read to prevent backslashes from being interpreted as escape sequences.
- Lower-case CMD and FILE . The Bash convention is that only environmental and internal shell variables are uppercase.
- Use printf in place of echo which is safer if $cmd is a string like -n , which echo would interpret as a flag.
file=test while IFS= read -r cmd; do printf '%s\n' "$cmd" done < "$file" use
What you have is piping the text "cat test" into the loop.
cat test | \ while read CMD; do echo $CMD done xargs is the most flexible solution for splitting output into command arguments.
It is also very human readable and easy to use due to its simple parameterisation.
Format is xargs -n $NUMLINES mycommand .
For example, to echo each individual line in a file /tmp/tmp.txt you'd do:
cat /tmp/tmp.txt | xargs -n 1 echo Or to diff each successive pair of files listed as lines in a file of the above name you'd do:
cat /tmp/tmp.txt | xargs -n 2 diff The -n 2 instructs xargs to consume and pass as separate arguments two lines of what you've piped into it at a time.
You can tailor xargs to split on delimiters besides carriage return/newline.
Use man xargs and google to find out more about the power of this versatile utility.
Работа с текстовыми выводами в Linux
![]()
Цель стати разобраться с текстовыми потоками. А также рассмотреть фильтрование текстовых выводы логов их редактирование, журналов сообщений и т.д. Проще говоря, рассмотреть фильтрация и корректировка выводимого на экран текста. Текстовый поток так называется, потому что это выводимая информация может быть не просто статичный текстовый файл, а те текстовые файлы, которые постоянно меняются или дополняются в режиме реального времени.
Список стандартных команд, которые понадобятся для достижения цели:
Cat, cut, expand, fmt, head, join, less, nl, od, paste, pr, sed, sort, split, tail, tr, unexpand, uniq, wc
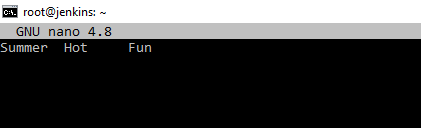
Для начала создадим пару текстовых файлов. Переходим в домашнюю корневую папку пользователя root. Переключение пользователя sudo su , и cd ~ . В любом текстовом редакторе создаем 2 файла hello1.txt и hello2.txt с содержанием как на скриншотах.

Команда cat
Начнем с команды, с которой уже не однократно встречались, команда cat. Сначала посмотрим справку по данной команде. man cat . Тут мы можем увидеть, что данная команда предназначена для объединения файлов и печати на стандартный вывод информации. Под стандартным выводом подразумевается вывод на консоль информации. Так же можно увидеть, что у данной команды есть ключи.
Самое простое применение данной команды. Вводим cat hello1.txt команда показывает то, что на скриншоте выше.
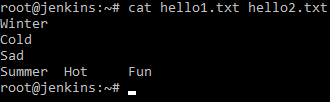
Проведем маленький эксперимент и выведем сразу информацию из двух созданных файлов.
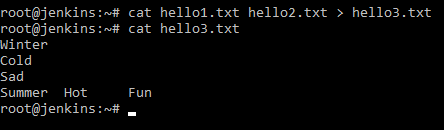
А в справке было написано, что команда может объединять содержимое файлов. Попробуем:
cat hello1.txt hello2.txt > hello3.txt cat hello3.txt
Мы вывели на стандартный вывод (консоль) содержимое файлов и передали то, что на экране в новый файл hello3.txt. А затем просто вывели на консоль. Результат можно посмотреть на скриншоте ниже.
Если нам файл более не нужен можно воспользоваться командой для удаления файлов
Команда cat более часто используется для объединения файлов, для просмотра содержимого чаще используются другие команды.
Команда cut
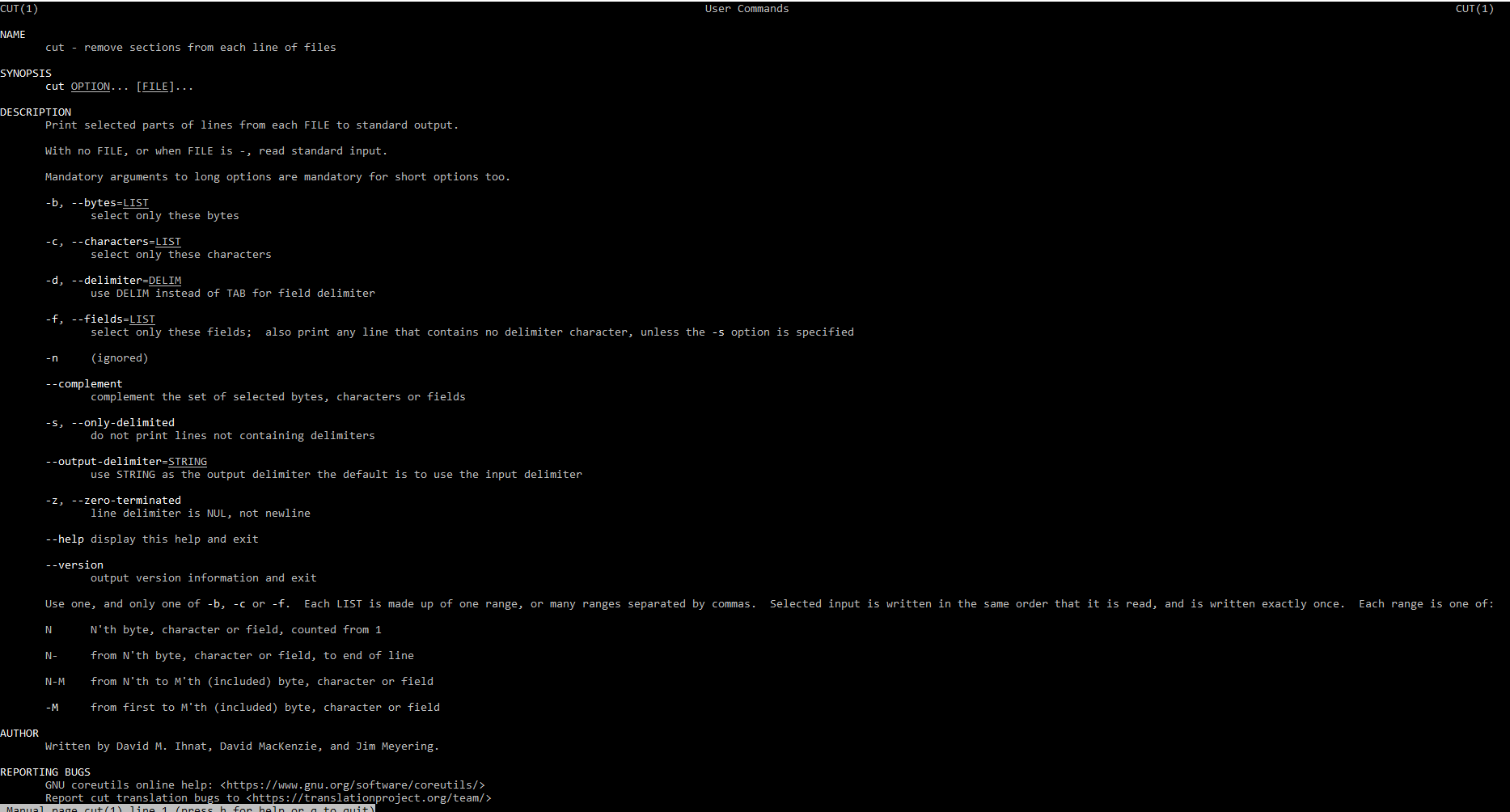
Данная команда предназначена для удаления секций из строчек файлов. Если посмотреть на ключи, то мы можем увидеть, что данная команда может удалять по различным признакам. По полям, по символам, по байтам, это интересная команда, которая позволяет нам вырезать части из файлов. Небольшой пример:
Данной командой мы говорим, что при выводе на экран нам необходимо "вырезать" перечисленные символы и вывести оставшееся на экран. Замечу, что команда cut не является текстовым редактором и поэтому фалы не правит! А только правит вывод в консоль. Если посмотреть командой cat hello1.txt файл остался неизменным.

Все команды, про которые речь в статье не редактируют исходные файлы, они только фильтруют или редактируют стандартный вывод информации. Для редактирования файлов используются текстовые редакторы.
Мы посмотрели, как данная команда редактирует вывод, на практике мы можем редактировать колонки, столбцы, вывода в каком-то конкретном логе или таблице. Т.е. мы можем выводить на экран только то, что нам нужно. Например, у нас есть лог события, какого-то, мы можем вывести только дату и события, остальное все лишнее отрезать данной командой в выводе.
Команда expand

Данная команда редко используется. Она необходима для конвертации символов табуляции в пробелы. Пример: expand hello2.txt и все табуляции превратились в пробелы. На практики редко применяемая команда.
Команда fmt
Как написано в мануале это текст форматер. Это серьезная команда, она умеет форматировать вывод текста различными способами.

Теперь посмотрим, как данной командой пользоваться.
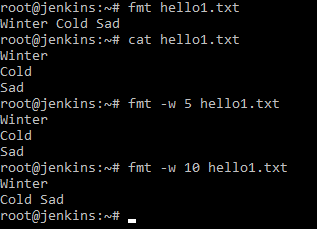
Например, написать fmt hello1.txt , как вы видите команда сделала вывод в одну строчку. Следовательно, команда без указания ключа, команда игнорирует все символы переноса каретки.
Т.е. все "enter" и перехода на новую строку он убрал.
Мы можем сказать, чтобы команда отформатировала текст так. чтобы на одной строке не было не более 5 символов, но это без переносов, если первое слово на 20 символов он его не перенесет, а если 2 слова по 2 символа, то оба оставит на этой строке.
Ничего не произошло, а если мы дадим fmt w 10 hello1.txt , то мы видим, что команда осуществила перенос. Таким образом можно просматривать длинные логи в удобном для нас виде, т. к. лог может уходить очень далеко в сторону, а через данную команду мы можем разбить на удобные абзацы для нас.
Команда head
Показывает первую часть файлов. Очень удобная команда, для просмотра того, что было в начале файла. По умолчанию показывает первые 10 строк файла.
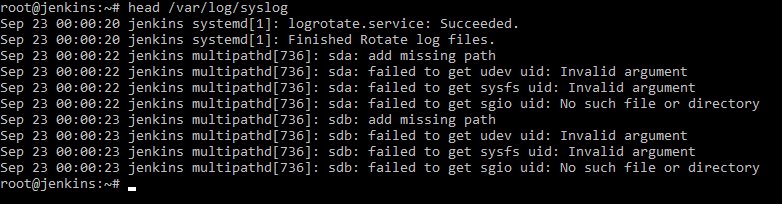
Для изменения, количества выводимых строк необходимо использовать ключ n и за ним указать необходимое количество строк.
Команда od
Превращает файлы в другие форматы. Грубо говоря это программа конвертор. Редко используется на практике.
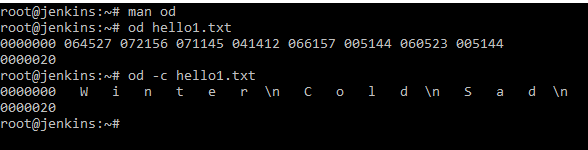
Используя данную команду по умолчанию, мы можем превратить файл в восьмеричный код od hello1.txt . Или с использованием ключа c превратить в формат ASCII, od c hello1.txt . это может понадобится для конвертации файла, например для другой машины со специфичным форматом данных.
Команда join
Данная команда, объединяет строчки файлов по общему полю. Для того, чтобы понять, как работает данная команда необходимо создать 2 текстовых файла touch .txt . Создаем сразу 2 файла 1.txt и 2.txt. И с помощью редактора nano редактируем. При применении команды join мы видим произошло объединение по полю нумерации.
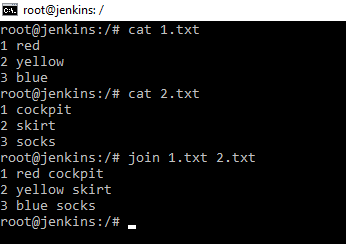
Это удобно, например, для слияния файлов, особенно логов, например, два файла логов и вам необходимо их сопоставить по времени.
Команда less

В описании команды говорится, что эта команда противоположна команде more. По сути это команда, которая позволяет читать файл.
Можно посмотреть работу ее на примере. Например, cat /var/log/syslog при запуске этой, команды мы получим очень большой вывод на несколько экранов. Если мы воспользуемся командой less /var/log/syslog , то вывод даст возможность листать постранично, через pgdn. Согласитесь, это намного упрощает чтение и просмотр файла. Бывает такое, что работа идет в консоли, в которой нету прокрутки, через мышку, то в таком случае данная команда становится вообще не заменимой. Если посмотреть описание, данная команда еще умеет делать небольшой поиск по файлу.
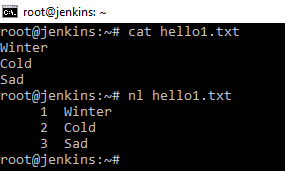
Команда nl

Нумерация строк. Простой пример. Берем файл и говорим пронумеровать строки. На картинке наглядно показано, как работает команда.
Команда paste
Команда вставка умеет вставлять построчно вставлять какие-то строки в файлы. Объединяет строки файлов, как написано в мануале.
У нас есть 2 файла 1.txt и 2.txt. Команда join их объединяла по определенному полю. Если мы применим команду paste мы увидим, что команда paste объединила их построчно.
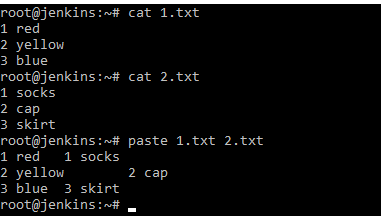
Т.е. это может быть очень удобно. У нас объединились первые строки, вторые строки и т.д. Например, если мы сопоставляем какие-нибудь события или файлы и т.д.
Команда pr

Данная команда конвертирует текстовые файлы для вывода на печать. Очень наглядно можно увидеть, как работает данная команда, если ее применить к большому файлу. Например, pr /var/log/syslog
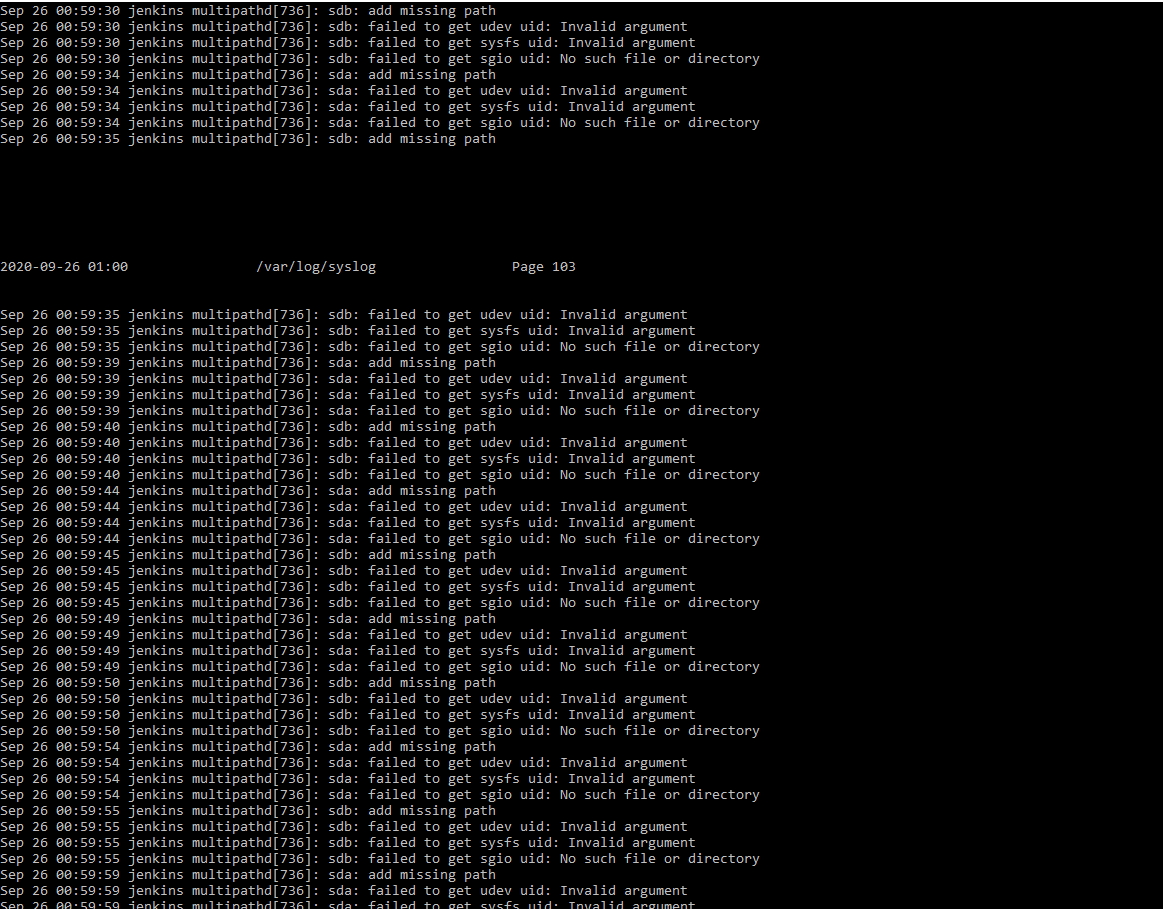
Как можно убедится, команда разбила вывод на страницы и подготовила данный вывод для печати.
Команда sed
Потоковый редактор для фильтрации и трансформирования текста. Это практически полноценный текстовый редактор, но опять же он не редактирует файлы, а работает с выводом.
Как его использовать, пример следующий заменим в файле 2.txt слово socks на слово people получается примерно так:

Функционал у команды очень большой, вывод можно для себя очень сильно изменить, заменить слова, удалить, отредактировать, отрезать, добавить, все это можно делать с помощью данной команды. При этом содержимое файла не меняется. Меняется только для нас вывод.
Команда sort
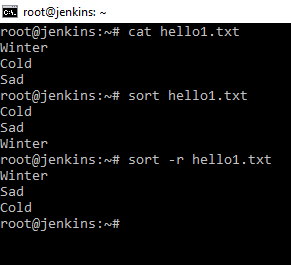
Сортирует строки в файлах по какому-то признаку. Поработаем с файлом hello1.txt. Если мы применим команду к данному файлу sort hello1.txt, то мы увидим, что вывод отсортировал строчки по алфавиту. А если применить ключик r, то от сортируется в обратном порядке. Это удобно использовать так же в совокупности с другими командами, отсортировать лишнее.
Команда split
Данная команда бьет файл на куски. Даная команда работает следующим образом. Даная команда разбивает файл на части, но при этом исходный не меняет. Например разобьем по строчкам фал 1.txt. split -l 2 1.txt . Разбивку делаем на 2 строчки. И мы видим, что у нас исходный файл остался неизменным, а появилось еще 2 файла xaa и xab. Они как раз и содержат разбиение.
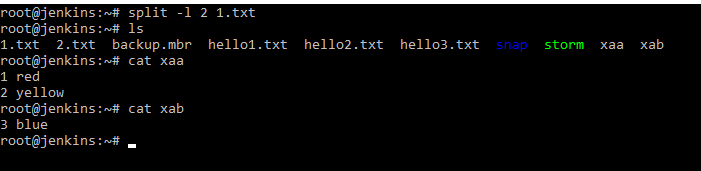
Данную команду удобно применять к большим файлам и использовать ключик для разбивки по размеру, например, по байтам b и указываем на какие куски разбить в байтах. Пример:
Команда tail
В отличии от команды head, данная команда показывает последнюю часть файла. Например, tail /var/log/syslog нам покажет последнюю часть лога событий.
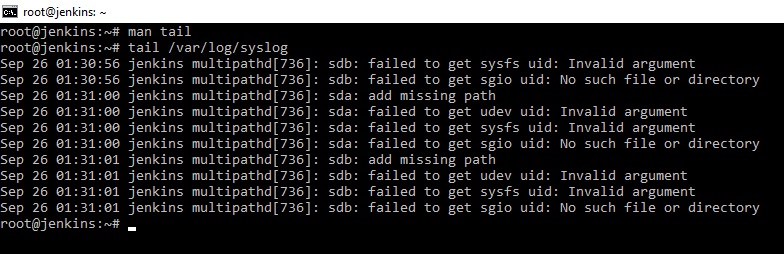
Добавляем ключ -n и число, мы получим число последних событий, которых мы указали. Очень полезный ключ -f, который говорит показывать добавление в файл на "живую", т.е в реальном времени. Очень удобно для диагностики, события пишутся в лог и сразу выводится на экран. Например, запись лога прокси сервера. Прерывание такого режима ctr+C.
Команда tr
Переводит или удаляет символы. Посмотрим на прямом выводе текста. Введем echo Hello. Далее введем echo Hello | tr -t A-Z a-z и заглавные буквы будут заменены строчными. Echo Hello | tr -t l L и маленькие l будет заменены на L. Echo Hello | tr -d l и буквы l будут удалены.
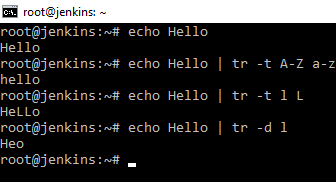
Мощный трансформатор текста. Работает непосредственно с текстом, ключей у него полно их можно посмотреть в мануале.
Команда unexpand
Работает в противоположную сторону команде expand. Конвертирует пробелы в знаки табуляции.
Обычно работают в паре expand и unexpand, для раздвижения столбцов.
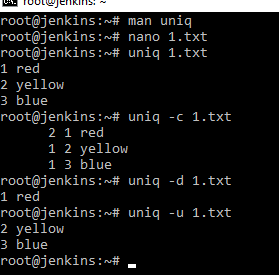
Команда uniq
Даная команда ищет уникальные и дублирующийся линии, т.е. она смотрит что у нас в строчках есть одинакового и разного. Для примера, я в файл 1.txt добавлю повторяющуюся строчку. И сделаю вывод uniq 1.txt команда покажет только уникальные строчки, а затем uniq c 1.txt и команда покажет строчки с числом повторений. Можно сказать, чтобы показала команда только дублирующиеся строчки uniq d 1.txt или неповторяющиеся uniq u 1.txt. Применение заключается в том. что если у нас есть файлы с повторяющееся информацией мы можем таким образом ее фильтровать.
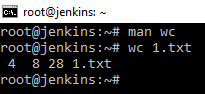
Команда wc

Показывает число строк, байт, слов и т.д. для определенного файла. Например: wc 1.txt показывает 4 строки, 8 слов, 28 символов.
Можно использовать с ключом w покажет количество слов. И т.д., можно получить информацию полностью по папке: