- Linux understand Page cache and buffer cache
- Linux understand Page cache
- What does Page cache work?
- How to check page cache is actually used.
- We will confirm that accessing data in the cache is fast.
- Linux understand buffer cache
- What does Buffer cache work?
- How to check Buffer cache is actually used.
- We will confirm that accessing data in the cache is fast.
- Conclusion
- Essential Page Cache theory #
- Read requests #
- Write requests #
- what are pagecache, dentries, inodes?
- 4 Answers 4
Linux understand Page cache and buffer cache
In this tutorial, I have written about Linux understand Page cache and buffer cache in Linux System.
Most file-system cache data read from disk.
Linux understand Page cache
What does Page cache work?
A cache of data is accessed via the file system.
How to check page cache is actually used.
Create a large file
[root@DevopsRoles ~]# mkdir /test [root@DevopsRoles ~]# dd if=/dev/zero of=/test/large.txt count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.62731 s, 644 MB/s [root@DevopsRoles ~]# echo 3 > /proc/sys/vm/drop_caches
Check memory usage before putting it in the page cache
[root@DevopsRoles ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 377344 0 64336 0 0 441 5203 131 293 0 2 97 0 0 [root@DevopsRoles ~]# cat /test/large.txt > /dev/null
Check memory usage after getting on page cache
[root@DevopsRoles ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 6500 0 435008 0 0 3265 3008 108 179 0 2 98 0 0 We will confirm that accessing data in the cache is fast.
[root@DevopsRoles ~]# time cat /test/large.txt > /dev/null real 0m1.068s user 0m0.003s sys 0m0.987s [root@DevopsRoles ~]# time cat /test/large.txt > /dev/null real 0m1.064s user 0m0.003s sys 0m0.981s Linux understand buffer cache
What does Buffer cache work?
Cache data accessed via raw I/O. It is a page cache for block devices.
How to check Buffer cache is actually used.
[root@DevopsRoles ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 5668 0 435832 0 0 6434 2087 116 132 0 2 98 0 0 [root@DevopsRoles ~]# dd if=/dev/sda of=/dev/null count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.59043 s, 659 MB/s
Increase buffer cache (buff)
We will confirm that accessing data in the cache is fast.
[root@DevopsRoles ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 13408 359528 68520 0 0 7715 1888 123 127 0 2 98 0 0 [root@DevopsRoles ~]# time dd if=/dev/sda of=/dev/null count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.13208 s, 926 MB/s real 0m1.138s user 0m0.001s sys 0m1.068s
[root@DevopsRoles ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 13664 359220 68520 0 0 8896 1747 130 119 0 2 98 0 0 [root@DevopsRoles ~]# time dd if=/dev/sda of=/dev/null count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.13821 s, 921 MB/s real 0m1.144s user 0m0.001s sys 0m1.072s
Conclusion
Linux understand Page cache and buffer cache. I hope will this your helpful. Thank you for reading the DevopsRoles page!
Essential Page Cache theory #
First of all, let’s start with a bunch of reasonable questions about Page Cache:
- What is the Linux Page Cache?
- What problems does it solve?
- Why do we call it «Page» Cache ?
In essence, the Page Cache is a part of the Virtual File System (VFS) whose primary purpose, as you can guess, is improving the IO latency of read and write operations. A write-back cache algorithm is a core building block of the Page Cache.
NOTE
If you’re curious about the write-back algorithm (and you should be), it’s well described on Wikipedia, and I encourage you to read it or at least look at the figure with a flow chart and its main operations.
“Page” in the Page Cache means that linux kernel works with memory units called pages. It would be cumbersome and hard to track and manage bites or even bits of information. So instead, Linux’s approach (and not only Linux’s, by the way) is to use pages (usually 4K in length) in almost all structures and operations. Hence the minimal unit of storage in Page Cache is a page, and it doesn’t matter how much data you want to read or write. All file IO requests are aligned to some number of pages.
The above leads to the important fact that if your write is smaller than the page size, the kernel will read the entire page before your write can be finished.
The following figure shows a bird’s-eye view of the essential Page Cache operations. I broke them down into reads and writes.
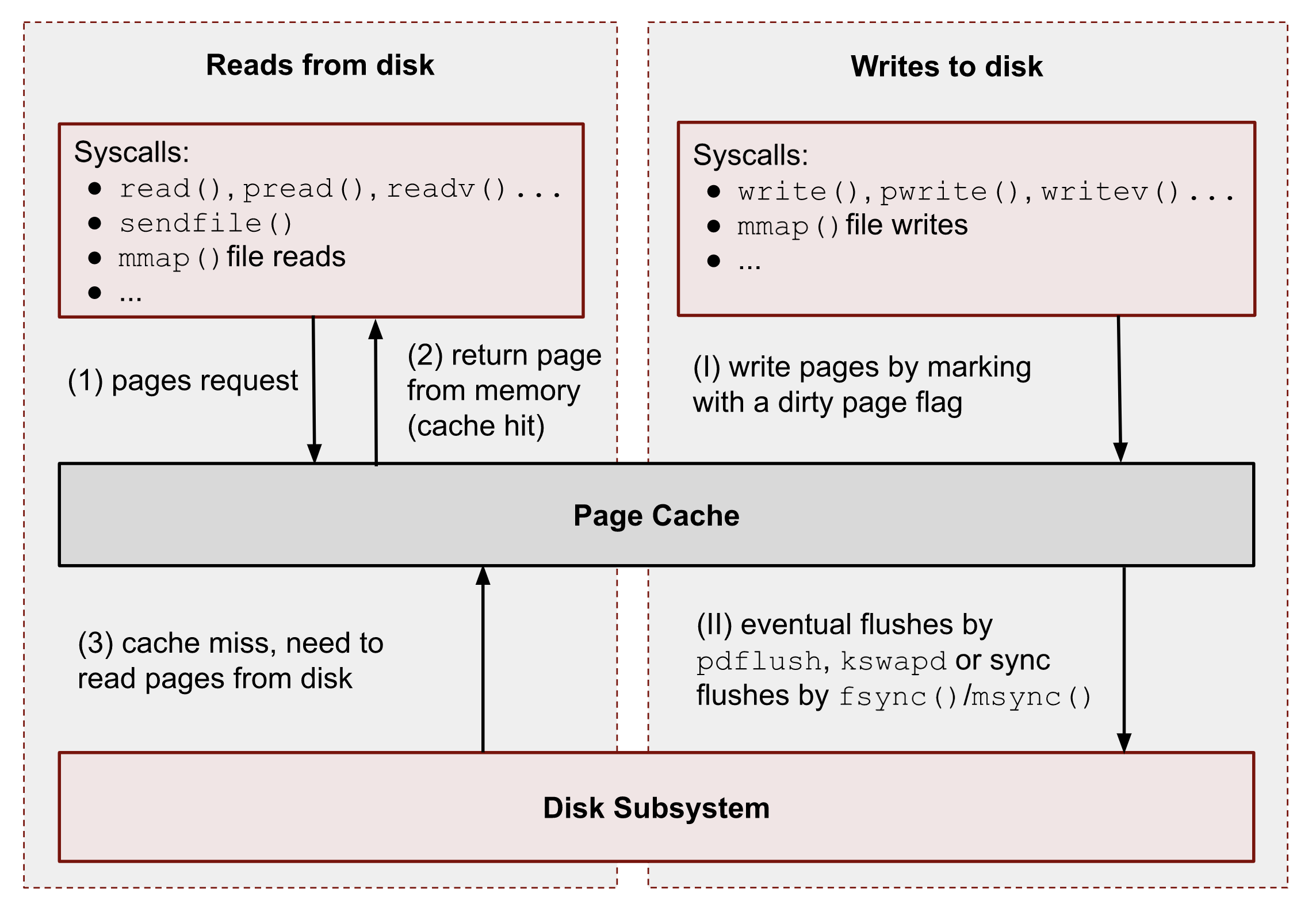
As you can see, all data reads and writes go through Page Cache. However, there are some exceptions for Direct IO ( DIO ), and I’m talking about it at the end of the series. For now, we should ignore them.
NOTE
In the following chapters, I’m talking about read() , write() , mmap() and other syscalls. And I need to say, that some programming languages (for example, Python) have file functions with the same names. However, these functions don’t map exactly to the corresponding system calls. Such functions usually perform buffered IO. Please, keep this in mind.
Read requests #
Generally speaking, reads are handled by the kernel in the following way:
① – When a user-space application wants to read data from disks, it asks the kernel for data using special system calls such as read() , pread() , vread() , mmap() , sendfile() , etc.
② – Linux kernel, in turn, checks whether the pages are present in Page Cache and immediately returns them to the caller if so. As you can see kernel has made 0 disk operations in this case.
③ – If there are no such pages in Page Cache, the kernel must load them from disks. In order to do that, it has to find a place in Page Cache for the requested pages. A memory reclaim process must be performed if there is no free memory (in the caller’s cgroup or system). Afterward, kernel schedules a read disk IO operation, stores the target pages in the memory, and finally returns the requested data from Page Cache to the target process. Starting from this moment, any future requests to read this part of the file (no matter from which process or cgroup) will be handled by Page Cache without any disk IOP until these pages have not been evicted.
Write requests #
Let’s repeat a step-by-step process for writes:
(Ⅰ) – When a user-space program wants to write some data to disks, it also uses a bunch of syscalls, for instance: write() , pwrite() , writev() , mmap() , etc. The one big difference from the reads is that writes are usually faster because real disk IO operations are not performed immediately. However, this is correct only if the system or a cgroup doesn’t have memory pressure issues and there are enough free pages (we will talk about the eviction process later). So usually, the kernel just updates pages in Page Cache. it makes the write pipeline asynchronous in nature. The caller doesn’t know when the actual page flush occurs, but it does know that the subsequent reads will return the latest data. Page Cache protects data consistency across all processes and cgroups. Such pages, that contain un-flushed data have a special name: dirty pages.
(II) – If a process’ data is not critical, it can lean on the kernel and its flush process, which eventually persists data to a physical disk. But if you develop a database management system (for instance, for money transactions), you need write guarantees in order to protect your records from a sudden blackout. For such situations, Linux provides fsync() , fdatasync() and msync() syscalls which block until all dirty pages of the file get committed to disks. There are also open() flags: O_SYNC and O_DSYNC , which you also can use in order to make all file write operations durable by default. I’m showing some examples of this logic later.
This website uses «cookies«. Using this website means you’re OK with this. If you are NOT, please close the site page.
what are pagecache, dentries, inodes?
I am trying to understand what exactly are pagecache, dentries and inodes. What exactly are they? Do freeing them up also remove the useful memcached and/or redis cache? — Why i am asking this question? My Amazon EC2 server RAM was getting filled up over the days — from 6% to up to 95% in a matter of 7 days. I am having to run a bi-weekly cronjob to remove these cache. Then memory usage drops to 6% again.
These approaches should not really have anything to do with memcached or redis. These two applications would be maintaining their own internal caching mechanisms to provide their functionality to the end user, and whether or not your 3 system operations impact them is an implementation detail of Memcached or redis.
I’m a bit late to this thread but it would be good to know how you determine that 95% of RAM is used in your vm. Often there is a misconception that all physical memory is used while it is exactly in the buffers+cache we are discussing here. See link for a good explanation of those columns.
Amazon EC2 detailed monitoring reports the memory (RAM) usage and it used to show 95% usage.. Sometimes even 98-99%
@kassav yes. Like i mentioned at the end of the question. Ran the 3rd command via a cron job at 1 hour intervals
4 Answers 4
With some oversimplification, let me try to explain in what appears to be the context of your question because there are multiple answers.
It appears you are working with memory caching of directory structures. An inode in your context is a data structure that represents a file. A dentries is a data structure that represents a directory. These structures could be used to build a memory cache that represents the file structure on a disk. To get a directly listing, the OS could go to the dentries—if the directory is there—list its contents (a series of inodes). If not there, go to the disk and read it into memory so that it can be used again.
The page cache could contain any memory mappings to blocks on disk. That could conceivably be buffered I/O, memory mapped files, paged areas of executables—anything that the OS could hold in memory from a file.
Your commands flush these buffers.
I actually do. My AWS ec2 RAM is going from 5% to 95% in about a week and never going down (still don’t know why). Am having to clean these cache on a bi weekly basis using a cronjob
I am trying to understand what exactly are pagecache, dentries and inodes. What exactly are they?
user3344003 already gave an exact answer to that specific question, but it’s still important to note those memory structures are dynamically allocated.
When there’s no better use for «free memory», memory will be used for those caches, but automatically purged and freed when some other «more important» application wants to allocate memory.
No, those caches don’t affect any caches maintained by any applications (including redis and memcached).
My Amazon EC2 server RAM was getting filled up over the days — from 6% to up to 95% in a matter of 7 days. I am having to run a bi-weekly cronjob to remove these cache. Then memory usage drops to 6% again.
Probably you’re mis-interpreting the situation: your system may just be making efficient usage of its ressources.
To simplify things a little bit: «free» memory can also be seen as «unused», or even more dramatic — a waste of resources: you paid for it, but don’t make use of it. That’s a very un-economic situation, and the linux kernel tries to make some «more useful» use of your «free» memory.
Part of its strategy involves using it to save various kinds of disk I/O by using various dynamically sized memory caches. A quick access to cache memory saves «slow» disk access, so that’s often a useful idea.
As soon as a «more important» process wants to allocate memory, the Linux kernel voluntarily frees those caches and makes the memory available to the requesting process. So there’s usually no need to «manually free» those caches.
The Linux kernel may even decide to swap out memory of an otherwise idle process to disk (swap space), freeing RAM to be used for «more important» tasks, probably also including to be used as some cache.
So as long as your system is not actively swapping in/out, there’s little reason to manually flush caches.
A common case to «manually flush» those caches is purely for benchmark comparison: your first benchmark run may run with «empty» caches and so give poor results, while a second run will show much «better» results (due to the pre-warmed caches). By flushing your caches before any benchmark run, you’re removing the «warmed» caches and so your benchmark runs are more «fair» to be compared with each other.