- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
- Windows 1251 для linux
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Символ биты A 01000001 B 01000010
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:
file -i mypoem_draft.txt file -i mynovel.txt

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
enca mypoem_draft.txt enca mynovel.txt
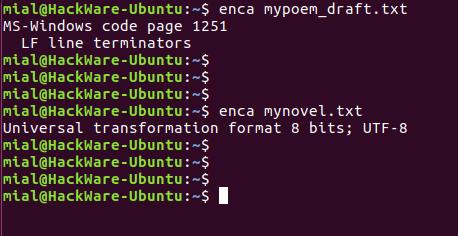
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
MS-Windows code page 1251 LF line terminators
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
enca -e mypoem_draft.txt CP1251/LF
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
enca -i mypoem_draft.txt CP1251
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
enca -m mypoem_draft.txt windows-1251
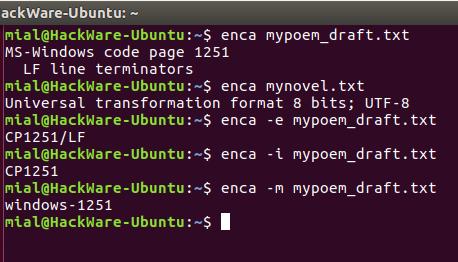
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
enca -m -L russian mypoem_draft.txt
Чтобы узнать список доступных языков наберите:
belarusian: CP1251 IBM866 ISO-8859-5 KOI8-UNI maccyr IBM855 KOI8-U bulgarian: CP1251 ISO-8859-5 IBM855 maccyr ECMA-113 czech: ISO-8859-2 CP1250 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK estonian: ISO-8859-4 CP1257 IBM775 ISO-8859-13 macce baltic croatian: CP1250 ISO-8859-2 IBM852 macce CORK hungarian: ISO-8859-2 CP1250 IBM852 macce CORK lithuanian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic latvian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic polish: ISO-8859-2 CP1250 IBM852 macce ISO-8859-13 ISO-8859-16 baltic CORK russian: KOI8-R CP1251 ISO-8859-5 IBM866 maccyr slovak: CP1250 ISO-8859-2 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK slovene: ISO-8859-2 CP1250 IBM852 macce CORK ukrainian: CP1251 IBM855 ISO-8859-5 CP1125 KOI8-U maccyr chinese: GBK BIG5 HZ none:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
echo $'СТРОКА_ДЛЯ_ПРОВЕРКИ' | chardet
echo $'СТРОКА_ДЛЯ_ПРОВЕРКИ' | enca -L ru
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
echo $'\xed\xe5 \xed\xe0 \xe9\xe4\xe5\xed\xf3\xea \xe0\xe7\xe0\xed\xed\xfb\xe9\xec\xee\xe4\xf3\xeb\xfc' | chardet : windows-1251 with confidence 0.970067019236
echo $'\xed\xe5 \xed\xe0 \xe9\xe4\xe5\xed\xf3\xea \xe0\xe7\xe0\xed\xed\xfb\xe9\xec\xee\xe4\xf3\xeb\xfc' | enca -L ru MS-Windows code page 1251 LF line terminators
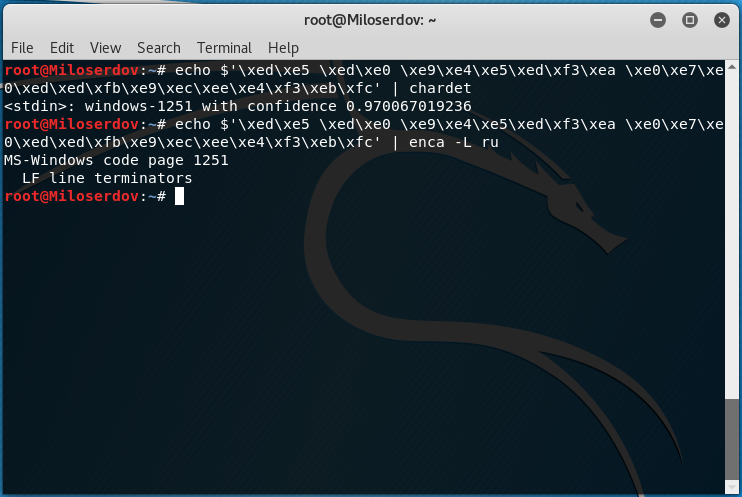
Если возникло сообщение об ошибке:
bash: chardet: команда не найдена
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
iconv опция iconv опции -f из-кодировки -t в-кодировку файл(ы) ввода -o файлы вывода
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
enca -i mypoem_draft.txt cat mypoem_draft.txt iconv -f CP1251 -t UTF-8//TRANSLIT mypoem_draft.txt -o poem.txt cat poem.txt enca -i poem.txt
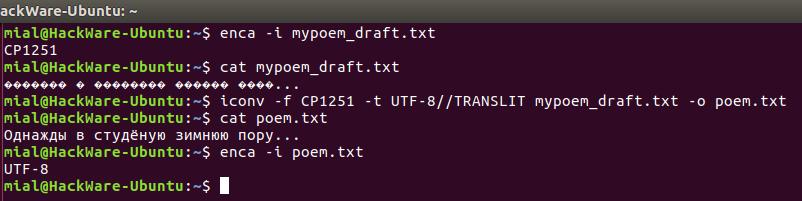
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном.
Внимание! Следующая команда изменяет исходный файл, при этом иногда его просто обнуляет. Поэтому обязательно начните с создания резервной копии:
cp mypoem_draft.txt mypoem_draft.txt.bac
Желаемую кодировку нужно указать после ключа -x:
enca -x UTF-8 mypoem_draft.txt
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
echo $'СТРОКА_ДЛЯ_ИЗМЕНЕНИЯ_КОДИРОВКИ' | iconv -f 'ЖЕЛАЕМАЯ_КОДИРОВКА'
echo $'\xed\xe5 \xed\xe0\xe9\xe4\xe5\xed \xf3\xea\xe0\xe7\xe0\xed\xed\xfb\xe9 \xec\xee\xe4\xf3\xeb\xfc' | iconv -f 'Windows-1251' не найден указанный модуль

Также для изменения кодировки применяются программы:
Windows 1251 для linux
Все что нужно сделать — это скачать найденую в сети CP1251-locale для FreeBSD и установить в систему:
Примечание: Забудьте про указанную выше локаль CP1251 и берите родную от FreeBSD, появилась RELENG_4 и в Current, ну или готовую из RELENG_4.
# tar zxvf FreeBSD-cp1251.tar.gz # cd cp1251/ # less README # make install
Использование locale CP1251 на консоли и виртуальных терминалах, вместо KOI8-R
1) установка locale ru_RU.CP1251 появилась в RELENG_4 (после 4.8-RELEASE) и в HEAD (после 5.1-RELEASE) взять можно уже выдранную оттуда(готовую): a) NewCP1251.tgz или выдрать готовую из одного из последних снапшотов(live-cd): b) ftp://current.freebsd.org/pub/FreeBSD/snapshots/i386/ или через cvsweb: c) http://www.freebsd.org/cgi/cvsweb.cgi/src/share/?only_with_tag=RELENG_4 2) настройка - /etc/login.conf: russian|Russian Users Accounts:\ :charset=CP1251:\ :lang=ru_RU.CP1251:\ :tc=default: или можно оставить оригинал для koi8-r поддержки и добавить класс win: # # Russian Users Accounts. Setup proper environment variables. # russian|Russian Users Accounts:\ :charset=KOI8-R:\ :lang=ru_RU.KOI8-R:\ :tc=default: win|Russian Windows Users Accounts:\ :charset=CP1251:\ :lang=ru_RU.CP1251:\ :tc=default: не забывать что пятое поле в master.passwd (vipw/adduser: man 5 passwd, man 5 vipw, man adduser и less /etc/adduser.conf) и есть login_class. Если мы хотим чтобы все default настройки были для CP1251, можем сделать: - /etc/profile (Bourne-Shell/Bash): . LANG=ru_RU.CP1251; export LANG LC_ALL=ru_RU.CP1251; export LC_ALL MM_CHARSET=CP1251; export MM_CHARSET . - /etc/csh.login (Csh/Tcsh): . setenv LANG ru_RU.CP1251 setenv MM_CHARSET CP1251 . либо у пользователя в $HOME, в .profile/.bash_profile (shell/bash), в .login (csh/tcsh). 3) консоль и виртуальные терминалы (фонты и клавиатура) - /etc/rc.conf: . # клавитурная мапа, найдена в интернете # ru.cp1251.kbd # положить в /usr/share/syscons/keymaps keymap=ru.cp1251 # можно не использовать, by default клавиша "CAPS LOCK" #keychange="61 ESC[K" # послоьку фонты cp866 самые удачные, используем их и скринмапу из cp866 в 1251 # найдено в сети win2cpp866.scm # положить в /usr/share/syscons/scrnmaps scrnmap="win2cpp866" font8x16=cp866-8x16 font8x14=cp866-8x14 font8x8=cp866-8x8 . прим: в /etc/ttys должно быть ttyv0 "/usr/libexec/getty Pc" cons25r on secure . ttyv5 "/usr/libexec/getty Pc" cons25r on secure . и так для всех используемых виртуальных экранов Если верхнее у вас прежде не было сделано, то чтобы изменения в /etc/ttys вступили в силу, необходимо выполнить команду: # kill -HUP 1 Прим: если у вас в каких-то приложениях использующих gettext, вместо русских ерунда, то создавайте сами эти хелпы или каких их назвать, в кодировке cp1251, уверен что все gettext сделаны в koi8r(возможно с дублем в cp1251), тут уж смотрите и делайте сами если нужно.
Для проверки локализации в html/php, смотри пункт Проверка локализации
Установка CP1251 locale в Linux:
Чтобы понять что, как и где создает утилита localedef, обязательно прочитайте man localedef, потому что в разных linux’ах locale распологается либо в /usr/share/locale/, либо /usr/lib/locale/. Вся локаль, включая 1251 уже содержится в i18n, необходимо лишь сгенерить из нее LC которая ляжет в /usr/share/locale/ru_RU.CP1251 или в /usr/lib/locale/ru_RU.CP1251 (зависит от типа Linux), достаточно выполнить команду:
localedef -c -i ru_RU -f CP1251 ru_RU.CP1251 после чего будет создана директория ru_RU.cp1251, как сказано выше: /usr/share/locale/ru_RU.cp1251 или /usr/lib/locale/ru_RU.cp1251 Все. Теперь просто переименуйте в ru_RU.CP1251 и проверьте наличие в системе: locale -a | grep ru_RU
Для проверки локализации в html/php, смотри пункт Проверка локализации
Можете воспользоваться моими заготовками для проверки html и php:
- .htacces                     Скачать wget’ом, затем cp htaccess .htaccess
- winlavr.php3                   Скачать wget’ом, затем cp winlavr.cp1251 winlavr.php3
- текст в cp1251 для winlavr.php3 Скачать wget’ом.
- winlavr.php3 — проверка преобразования/Windows-1251 кодировки — верхний/нижний регистр и стремные буквы
необходимо скачать указанные выше файлы .htaccess и winlavr.php3, разместить на WWW или в домашней странице и посмотреть результат.
Есть много разных CP1251 фонтов для X11, я таскаю за собой следующие:
Разворачиваете нужные или подходящие вам в /usr/X11R6/lib/X11/fonts, добавляете их в XF86Config, например:
. # FontPath "/usr/X11R6/lib/X11/fonts/local/" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/misc/" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/75dpi/" FontPath "/usr/X11R6/lib/X11/fonts/cyrillic/100dpi/" #--lavr Windows-CP1251 fonts FontPath "/usr/X11R6/lib/X11/fonts/win-micex/misc/" FontPath "/usr/X11R6/lib/X11/fonts/win-micex/75dpi/" FontPath "/usr/X11R6/lib/X11/fonts/win-micex/100dpi/" FontPath "/usr/X11R6/lib/X11/fonts/misc/" FontPath "/usr/X11R6/lib/X11/fonts/75dpi/:unscaled" FontPath "/usr/X11R6/lib/X11/fonts/100dpi/:unscaled" FontPath "/usr/X11R6/lib/X11/fonts/Type1/" FontPath "/usr/X11R6/lib/X11/fonts/CID/" FontPath "/usr/X11R6/lib/X11/fonts/PEX/" FontPath "/usr/X11R6/lib/X11/fonts/TTF/" FontPath "/usr/X11R6/lib/X11/fonts/Speedo/" FontPath "/usr/X11R6/lib/X11/fonts/75dpi/" FontPath "/usr/X11R6/lib/X11/fonts/100dpi/" FontPath "/usr/local/share/koi8r-ps/" # .
xset +fp /usr/X11R6/lib/X11/fonts/win-micex/misc xset +fp /usr/X11R6/lib/X11/fonts/win-micex/75dpi xset +fp /usr/X11R6/lib/X11/fonts/win-micex/100dpi
теперь смело можно смотреть файлы в Windows-CP1251 кодировке, запуская, например xterm с понравившимся фонтом:
для переключения раскладок в X11 можно воспользоваться портами FreeBSD: