- /proc/meminfo + gawk = удобный JSON для discovery метрик в zabbix
- Русские Блоги
- Настройте используемую память zabbix для более точного и доступного использования памяти
- Русские Блоги
- Zabbix отслеживает использование памяти centos7 (запись мелкая, серый)
- Мониторинг памяти в Linux
- Мониторинг памяти в Linux — основные утилиты для контроля
/proc/meminfo + gawk = удобный JSON для discovery метрик в zabbix
После разведки и создании метрик, данные по метрикам должны приезжать в мониторинг раз в минуту одной операцией, для снижения эффекта наблюдения.
Первое что пришло на ум — создать скрипт, запилить в нем всю логику, разложить на сервера и добавить юсер-параметр zabbix агента, но это не спортивно, так как эту же штуку можно сделать используя gawk и без скриптов.
Создадим шаблон в мониторинге, переходим во вкладку макросы, создаем три макроса:
Макрос нужен для того чтобы gawk нашелся при попытке его запустить
PATH=$PATH:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin; LANG=en_US.UTF-8;Макрос нужен будет в discovery ( простыню про gawk, BEGIN я объясню в конце статьи )
gawk 'BEGIN \": \"%s\", \"\": \"%s\">",separator, $1, b;separator = ",";> END < print " ]>" >' /proc/meminfo Макрос нужен при получении метрик раз в минуту
gawk 'BEGIN < FS=":"; ORS = ""; print " < b=gensub(/ +/,"","g",gensub(/kB/,"","g",$2) ); $1=gensub(/\(|\)/,"_","g",$1); printf "%s\"%s\":\"%s\"",separator,$1,b;separator=",";>END < print ">" >' /proc/meminfo
Создадим обычную метрику meminfo system.run[ ,wait]
Обратите внимание на конструкцию вызова system.run и внутри два макроса очень коротко, лаконично и удобно
Метрика meminfo является источником данных для метрик которые будут обнаружены
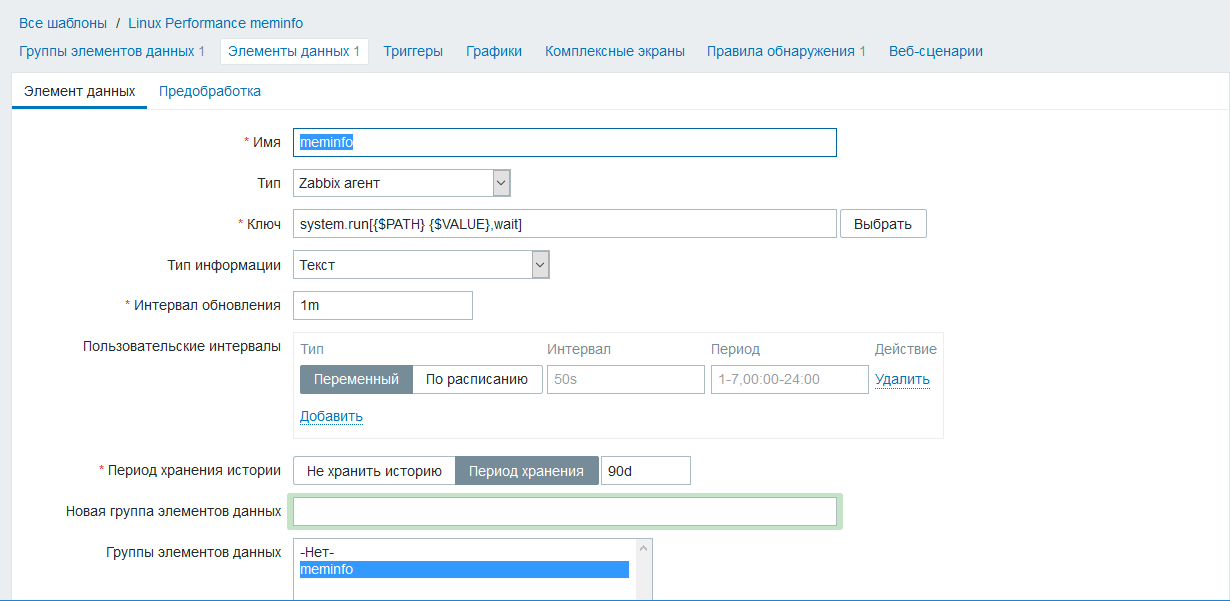
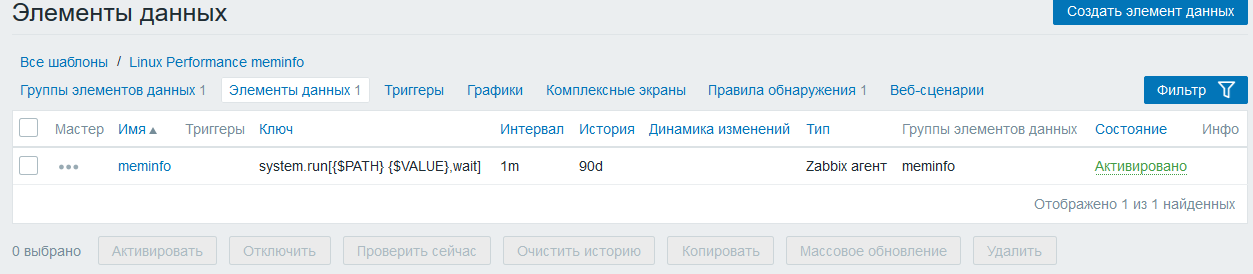
Создаем правило обнаружения meminfo
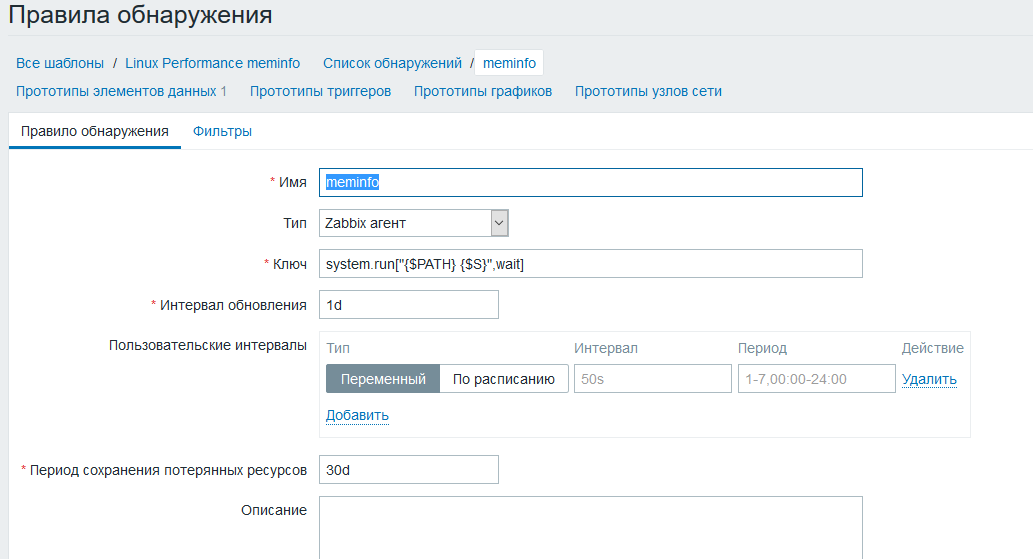
Перейдем в фильтр и добавим [не равно] VmallocTotal|VmallocChunk это делается для исключения двух ненужных нам параметров
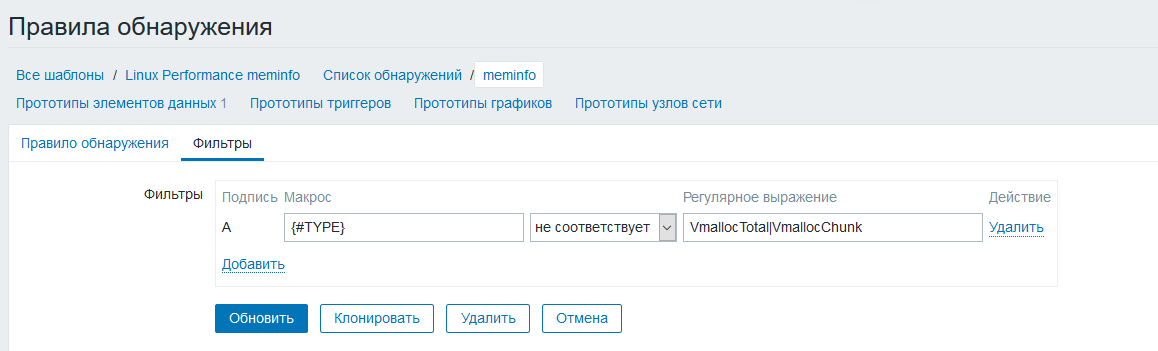
Создаем прототип элемента данных, тип данных зависимый элемент, в качестве источника данных выбираем метрику созданную ранее
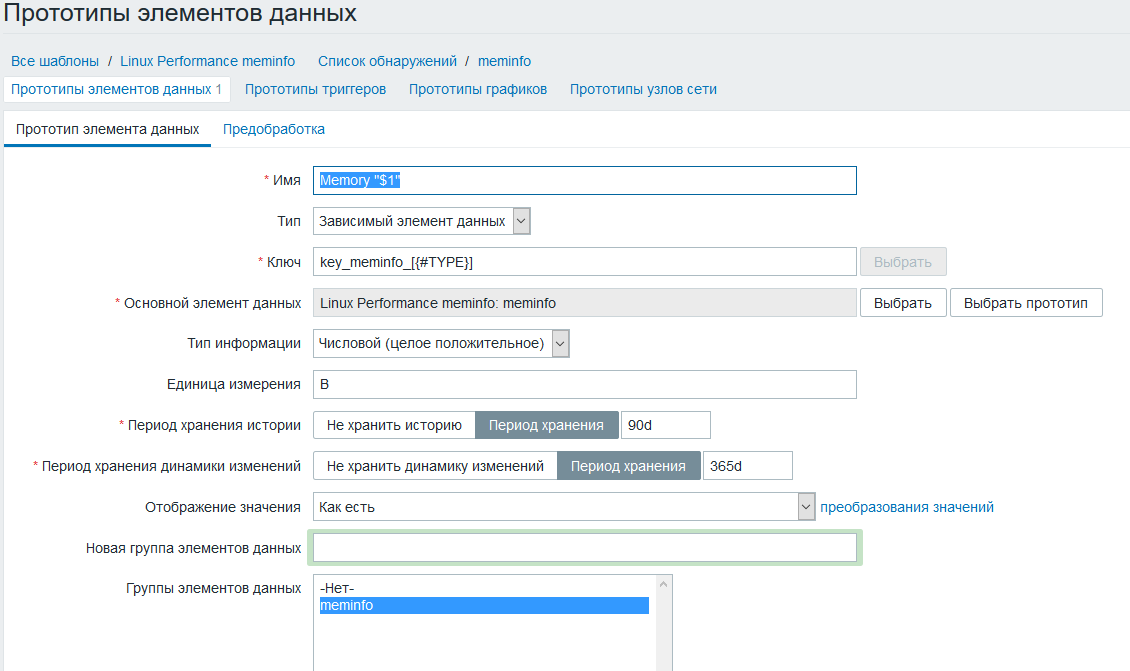
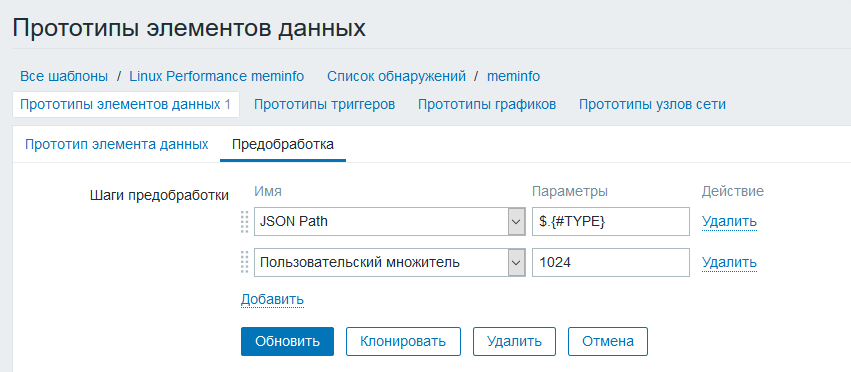
В пред-обработке настраиваем JSONPath + добавляем множитель так как цифры приезжают к нам килобайтах, а нужны в байтах для правильного отображения на графиках и в последних данных.
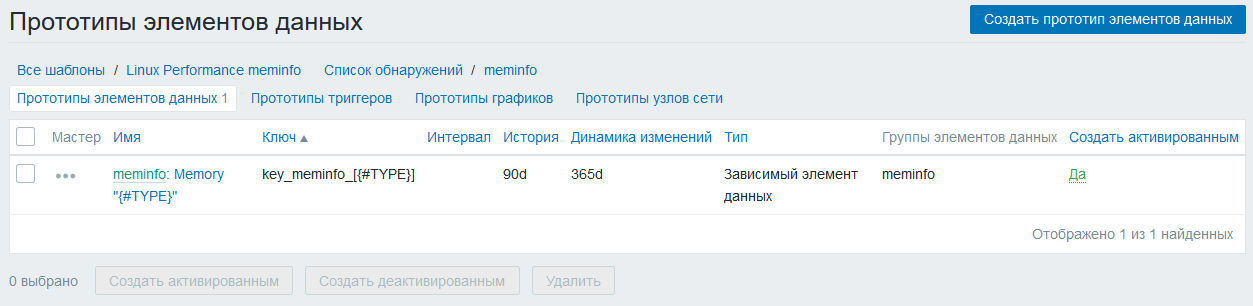
Линкуем созданный шаблон с хостом
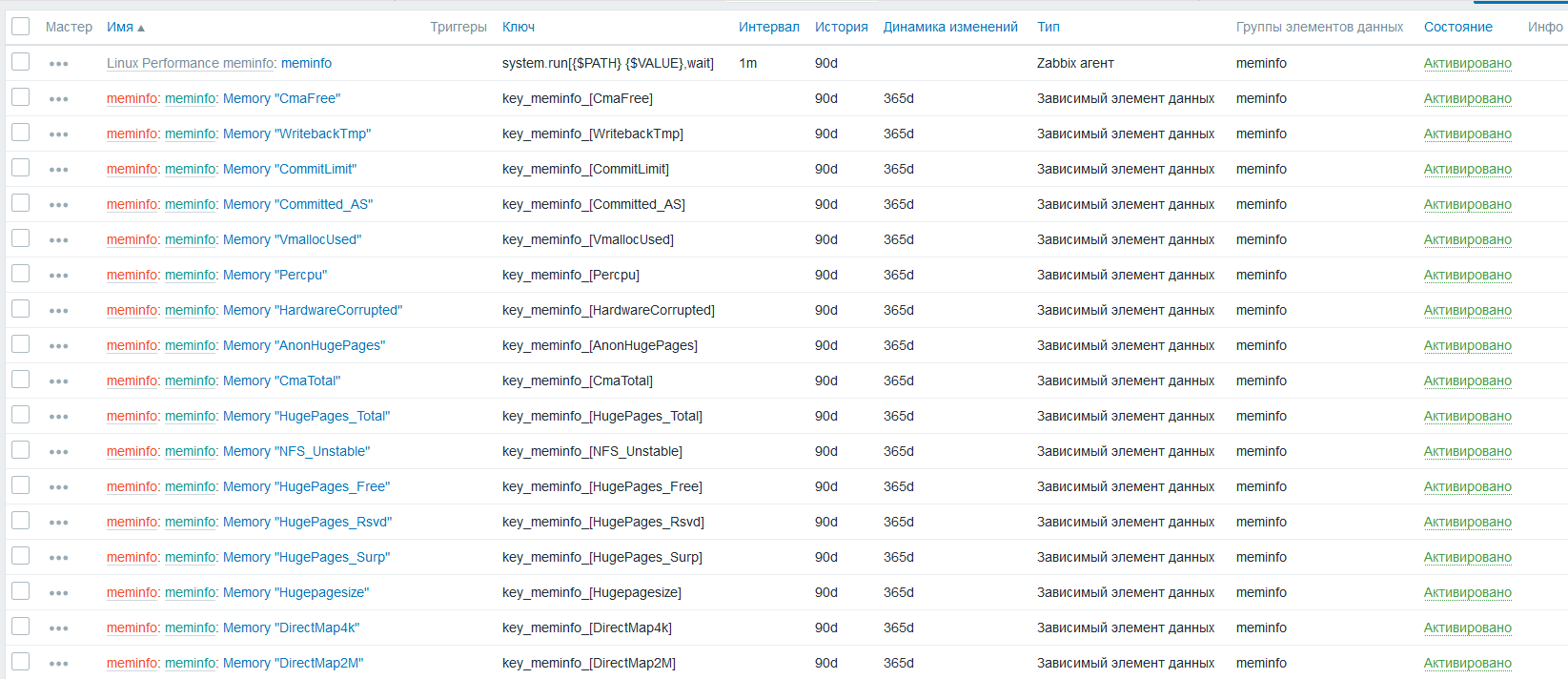
метрики нашлись, данные по ним распределились в правильном исчислении то есть в байтах

можем посмотреть и графики
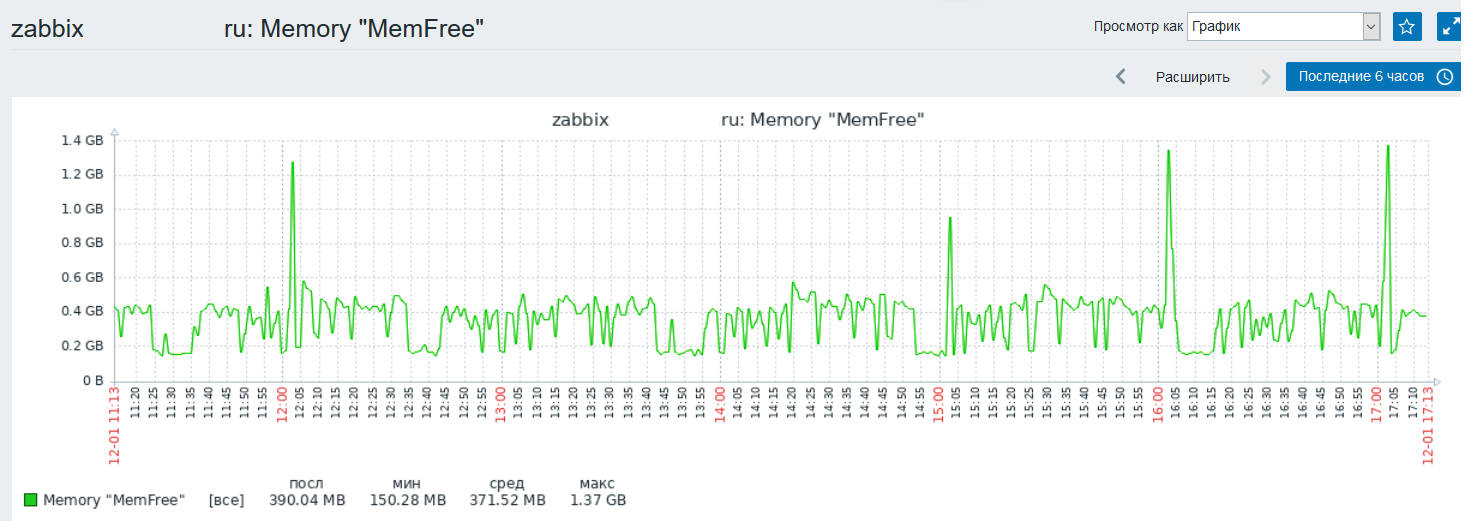
Теперь самое интересное, как использовать gawk для создания JSON для discovery и для базовой метрики
Вот полный честный вывод JSON для discovery
root@server:~# gawk 'BEGIN \": \"%s\", \"\": \"%s\">",separator, $1, b;separator = ",";> END < print " ]>" >' /proc/meminfo ": "MemTotal", "": "8139880">,": "MemFree", "": "147628">,": "MemAvailable", "": "4764232">,": "Buffers", "": "115316">,": "Cached", "": "6789504">,": "SwapCached", "": "9356">,": "Active", "": "4742408">,": "Inactive", "": "2733636">,": "Active_anon_", "": "2411644">,": "Inactive_anon_", "": "340828">,": "Active_file_", "": "2330764">,": "Inactive_file_", "": "2392808">,": "Unevictable", "": "0">,": "Mlocked", "": "0">,": "SwapTotal", "": "3906556">,": "SwapFree", "": "3585788">,": "Dirty", "": "368">,": "Writeback", "": "0">,": "AnonPages", "": "568164">,": "Mapped", "": "2294960">,": "Shmem", "": "2182128">,": "KReclaimable", "": "198800">,": "Slab", "": "340536">,": "SReclaimable", "": "198800">,": "SUnreclaim", "": "141736">,": "KernelStack", "": "7040">,": "PageTables", "": "90568">,": "NFS_Unstable", "": "0">,": "Bounce", "": "0">,": "WritebackTmp", "": "0">,": "CommitLimit", "": "7976496">,": "Committed_AS", "": "5189180">,": "VmallocTotal", "": "34359738367">,": "VmallocUsed", "": "25780">,": "VmallocChunk", "": "0">,": "Percpu", "": "24480">,": "HardwareCorrupted", "": "0">,": "AnonHugePages", "": "0">,": "ShmemHugePages", "": "0">,": "ShmemPmdMapped", "": "0">,": "FileHugePages", "": "0">,": "FilePmdMapped", "": "0">,": "CmaTotal", "": "0">,": "CmaFree", "": "0">,": "HugePages_Total", "": "0">,": "HugePages_Free", "": "0">,": "HugePages_Rsvd", "": "0">,": "HugePages_Surp", "": "0">,": "Hugepagesize", "": "2048">,": "Hugetlb", "": "0">,": "DirectMap4k", "": "773632">,": "DirectMap2M", "": "7606272">,": "DirectMap1G", "": "2097152"> ]> root@server:~# Вот так выглядит JSON для discovery
": "MemTotal", "": "8139880">, ": "MemFree", "": "147628">, ": "MemAvailable", "": "4764232">, ": "Buffers", "": "115316">, ": "Cached", "": "6789504">, ": "SwapCached", "": "9356">, . ": "DirectMap4k", "": "773632">, ": "DirectMap2M", "": "7606272">, ": "DirectMap1G", "": "2097152"> ]> root@server:~# root@server:~# gawk 'BEGIN < b = gensub(/ +/,"","g", gensub(/kB/,"","g",$2) ); $1=gensub(/\(|\)/,"_","g",$1); printf "%s\": \"%s\", \"\": \"%s\">",separator, $1, b;separator = ",";> END < print " ]>" >' /proc/meminfoFS=»:»; — разделяет строку на части и передает разделившееся части в $1, $2 . $n
Дальше происходит магия gawk организует сам цикл с перечислением всех полученных строк, принимая во внимание то что строки будут разделятся по «:» то мы в $1 получать всегда имя параметра, а в $2 всегда его значение, правда не очень в удобном формате
собственно это выглядит — есть строка из цикла CommitLimit: 7976496 kB которая разделяется:
Нужно пред-обработать обе строки
b = gensub(/ +/,»»,»g», gensub(/kB/,»»,»g»,$2) ); содержится две функции gensub
Вложенная функция gensub(/kB/,»»,»g»,$2) исключает из вывода kB а базовая gensub(/ +/,»»,»g», . ); исключает пробелы, получаем чистую цифиру.
Следом в имени параметров нужно предусмотреть что должно быть символов скобок ( ) так как мониторинг их не перевариват, ни при создании метрик, ни при разнесении данных.
Сказанно — сделано, регуляркой уберем скобки из имени параметра, заменим поджопником нижней чертой _ $1=gensub(/\(|\)/,»_»,»g»,$1);
После подготовленные параметры, собираем JSON и выводим
После того как все строки обработаны, gawk выполняет END < print " ]>» что закрывает JSON и финализирует.
Вот таким простым способом без скриптов можно сделать обнаружения и формирование JSON с данными, добавив метрики в мониторинг и получая максимальный эффект от простоты применения.
Русские Блоги
Настройте используемую память zabbix для более точного и доступного использования памяти
[[email protected] ~]# free -m total used free shared buffers cached Mem: 995 785 209 0 6 92 -/+ buffers/cache: 686 308 Swap: 478 200 278
Доступная память: доступная память = свободная + буферы + кэшированные, т.е. 308 = 209 + 6 + 92
Используемая память: Used memory = used-buffers-cached, то есть 686 = 785-6-92
При использовании собственного шаблона Linux Template OS для zabbix для мониторинга сервера было обнаружено, что используемая память полностью заполнена. Это потому, что zabbix получает используемую память сервера через ключ vm.memory.size [used]. Но значение, полученное с помощью vm.memory.size [used] (используется 785, как показано ниже), также включает буферы и кэширование.
Буферы и кэширование также доступны серверу. Просто Linux сам использует как можно больше памяти и освобождает буферы и кешированное пространство только тогда, когда памяти недостаточно.
Доступная память, полученная с помощью vm.memory.size [available], довольно точна. Таким образом, мы изменим ключевое значение Используемой памяти, чтобы получить точное значение используемой памяти, вычтя доступную память из общей памяти.

конкретный:
1. Настроить | Шаблоны | Шаблон ОС Linux, выберите Элементы, щелкните Используемая память, чтобы ввести конфигурацию, как показано ниже, перед изменением.
2. Изменить тип и формулу
Тип выберите Расчетный # Тип расчета
Ввод формулы (last («vm.memory.size [total]») — last («vm.memory.size [available]»)), вычтите доступную память из общей памяти, чтобы получить точную используемую память.

Ввод формулы (100 * last («vm.memory.size [available]») / last («vm.memory.size [total]»)), разделите доступную память на общую память, чтобы получить коэффициент использования памяти.



спусковой крючок:
1. Configuration—>Templates—>Template OS Linux—>Triggers—>create trigger
Name: free mem less 10%
Expression:

Если состояние элементов или триггера не поддерживается, возможно, возникла проблема с выражением, и вам необходимо проверить и протестировать
Память меньше 10%. В настоящее время ресурсы памяти сервера фактически ограничены. Вы можете использовать этот триггер для запуска сценария для перезапуска служб, которые занимают больше памяти. Как правило, службы на сервере относительно фиксированы. Те, кто потребляет больше памяти, — это те , Вы можете выбрать несколько перезапусков (один экземпляр с осторожностью), и лучше всего контролировать службу, чтобы избежать сценария автоматического перезапуска службы, не запускающего службу.
Русские Блоги
Zabbix отслеживает использование памяти centos7 (запись мелкая, серый)
Мониторинг памяти: мониторинг использования памяти
Тревога срабатывания: когда уровень использования превышает 95% Сообщение о тревоге

used : Память, используемая программой
free : Нераспределенная память
buff/cache : Системный кеш ( buff cache Блокировать кеш устройства) (page cache Файловый кеш )
[buff/cache Кэш можно освободить: /proc/sys/vm/drop_caches (По умолчанию 0 ) ]

echo 1 > /proc/sys/vm/drop_caches Очистить pagecache
echo 2 > /proc/sys/vm/drop_caches Чистая переработка slab Объекты в распределителе (включая кэш записей каталога и inode Кэш)
echo 3 > /proc/sys/vm/drop_caches Значит ясно pagecache с участием slab Кэшированные объекты в распределителе
available : Доступная память системы
available=free+buff/cache- Память, не подлежащая вторичной переработке (общая память, tmpfs 、 ramfs Подождите)
2 : Пользовательский шаблон


Имя Шаблона: Memory used percent
2.2 : Создание элементов мониторинга

Ключевое значение: vm.memory.size[usedpercent]
Тип информации: число (без положительного или отрицательного)

имя: Memory used percent too high

Пункты мониторинга: Memory used percent: Memory used percent
Особенности: avg()-Average value of a period T

Тест построителя выражений:



Максимальное значение: 100.0000
Пункты мониторинга: Memory used percent: Memory used percent
3 : Хост присоединяется к шаблону
Мониторинг памяти в Linux
В Linux мониторинг памяти производится всеми распространенными системами: Nagios, Zabbix и т.п. В рамках данного материала рассмотрим как можно вручную проверить какой объем оперативной памяти доступен и каким консольные утилиты лучше использовать чтобы получить информацию.
Мониторинг памяти в Linux — основные утилиты для контроля
Прежде всего, vmstat
В выводе утилиты присутствует блок memory со следующими колонками:
swpd — показывает память, выделенную под swap
free — свободная память
buff — зарезервировано системой для тех процессов которые в определенный момент будут нуждаться в памяти
cache — кэшированная память, то что система использовала недавно
Для swap выделяется количество входящих и исходящих блоков, которые обрабатываются в единицу времени:
si — in, количество блоков в секунду которое система считывает
so — out, количество блоков в секунду которое система записывает в swap
Размер блока зависим от формата файловой системы и настроек.
Можно запустить vmstat с ключом -а
inactive — показывает память, выделенную для процессов и зарезервированную, которая при этом в определенных ситуациях система может использовать
active — используемая процессами
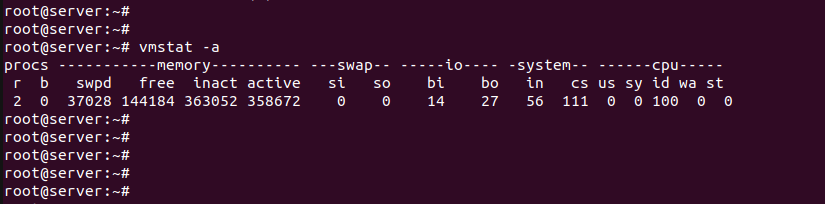
В самой доступной форме информация представлена в выводе free
shared — общая память для нескольких процессов, которая может задействоваться без системных вызовов ядра, обычно раздел можно увидеть смонтированным в /tmpfs
buff/cache — то же, что в vmstat, но два параметра представлены вместе
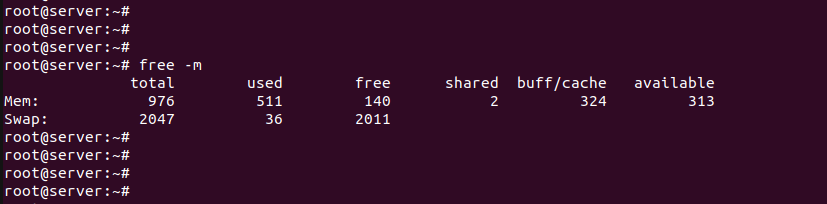
Всю информацию по серверу, в т.ч. о расходе оперативной памяти можно получить из top
shift + m обеспечит сортировку по памяти
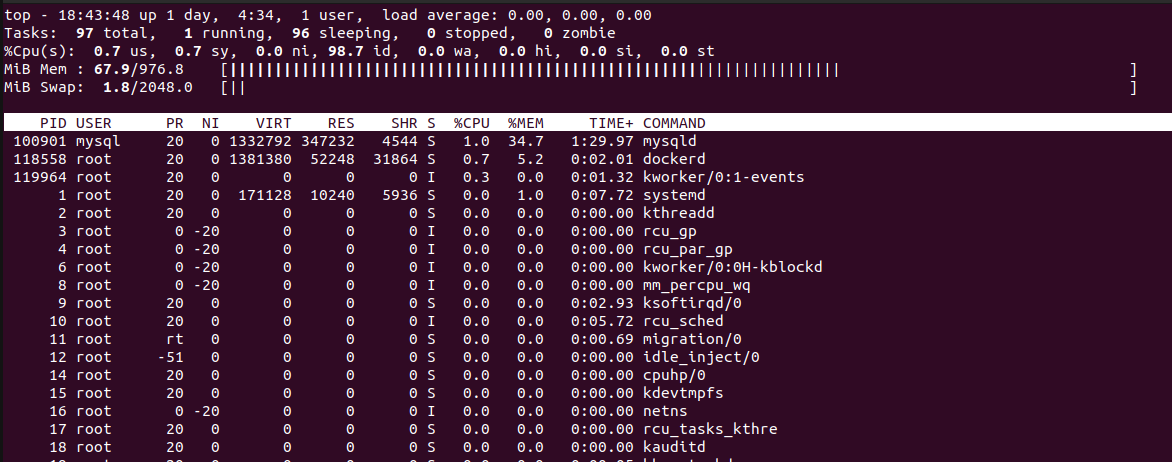
top покажет общее потребление, а также процессы, которые потребляют больше всего RAM. На скриншоте видно, что в системе это прежде всего mysqld.
Второй в списке процесс Docker с идентификатором 118558.
Читайте про утилиту top, а также про то что делать если памяти недостаточно, но увеличить её объем физически нельзя.