Мониторинг использования CPU в Zabbix
Приведу пример мониторинга использования каждого ядра процессора используя Zabbix.
Допустим на высоконагруженном NAT сервере основная нагрузка от softirq, присутствует один процессор с 8 ядрами, а также на сервере установлен Zabbix агент.
И чтобы увидеть равномерно ли распределены прерывания сетевого адаптера по ядрам процессора, создадим элементы данных на Zabbix сервере, в которых укажем:
Тип: Zabbix агент
Тип информации: Числовой (с плавающей точкой)
Единица измерения: %
А также ключ:
system.cpu.util[0,softirq,avg5]
Где 0 — номер процессора, softirq — тип нагрузки, avg5 — средняя нагрузка за 5 минут. Аналогично создадим элементы данных для других ядер процессора с ключами, а также добавим их на один график:
system.cpu.util[1,softirq,avg5] system.cpu.util[2,softirq,avg5] system.cpu.util[3,softirq,avg5] .
Вместо softirq можно указать idle, nice, user (по умолчанию для Linux), system (по умолчанию для Windows), iowait, interrupt, softirq, steal, guest, guest_nice.
А вместо avg5 можно указать: avg1 (среднее за одну минуту, по умолчанию) или avg15 (среднее за 15 минут).

Чтобы не указывать ядра процессоров вручную, можно создать правило обнаружения:
И указать в нем элемент данных, например:
Также можно создать триггер, чтобы узнать когда значение будет больше 90:
Ниже приведу примеры элементов данных, которые отображают различную информацию о CPU, кстати эти элементы данных по умолчанию присутствуют в шаблоне «Template OS Linux».
Processor load (1 min average per core):
Processor load (5 min average per core):
Processor load (15 min average per core):
Context switches per second:
Смотрите другие мои статьи в категории Zabbix.
Zabbix: Мониторинг выборочного процесса (CPU, MEM)
Как создать универсальный Zabbix шаблон для мониторинга Linux процесса, указанного по имени.
1. Создание нового шаблона Zabbix
Идем в Configuration -> Templates -> Create template и добавляем имя, группу и описание шаблона.
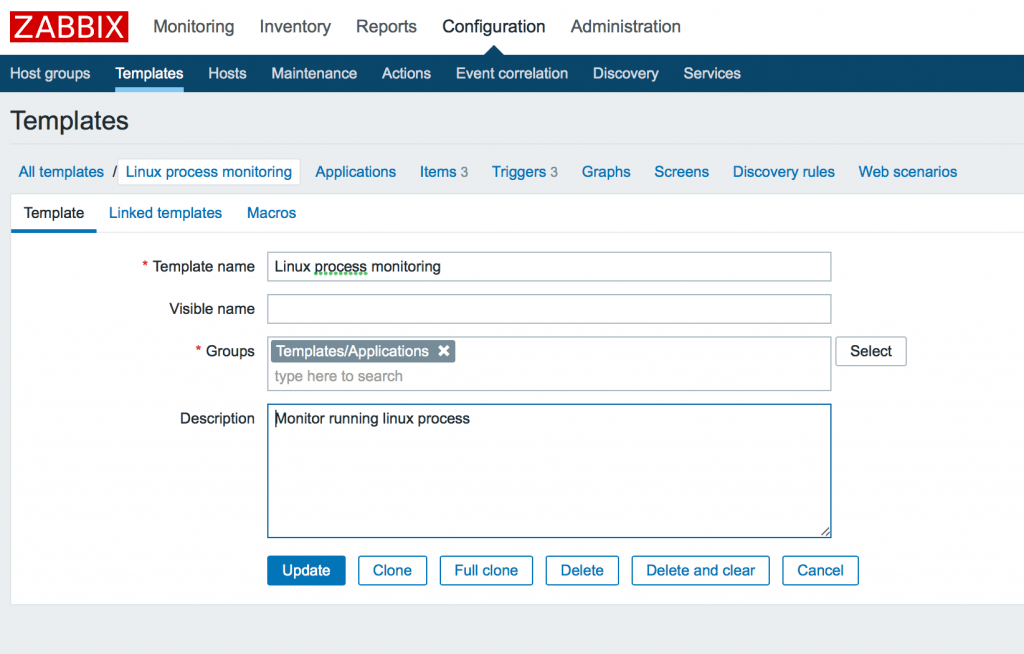
2. Добавление макроса
Мы хотим мониторить 3 параметра:
- количество процессов, с уведомлением о том, что процессов стало меньше (упали)
- использование памяти, с уведомлением о превышении
- использование процессора, с уведомлением о превышении
Давайте тут же определим значения по умолчанию. Для этого мы будем использовать макросы шаблона (вкладка Macros), чтобы потом была возможность заменить их для каждого хоста.
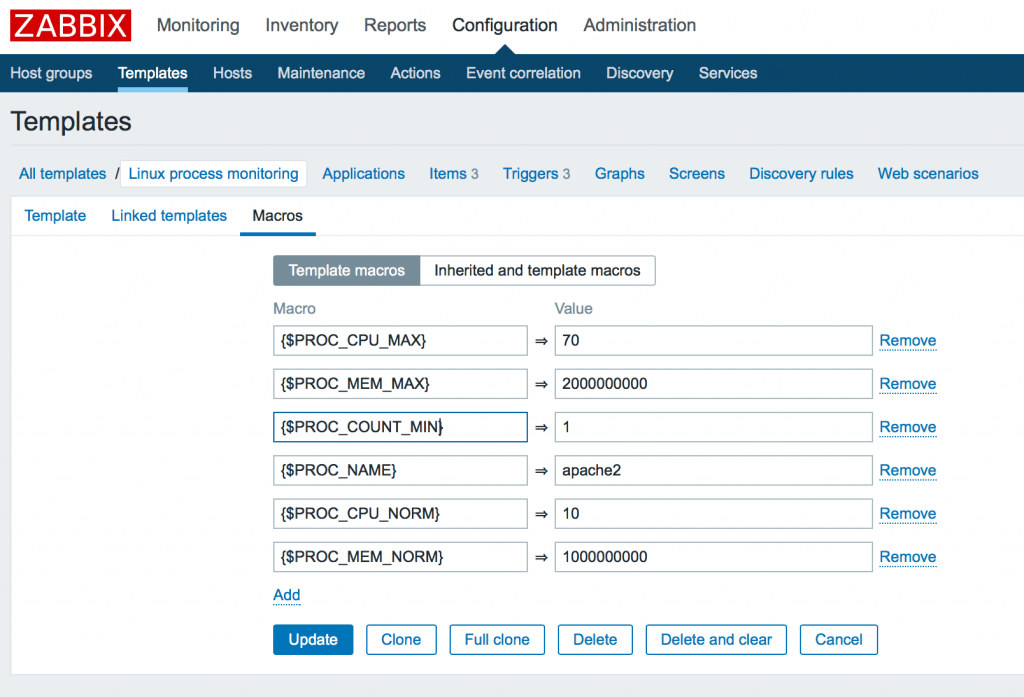
В этом примере мы создали 6 макросов.
$PROC_CPU_MAX> => 70 $PROC_MEM_MAX> => 2000000000 $PROC_COUNT_MIN> => 1 $PROC_NAME> => apache2 $PROC_CPU_NORM> => 10 $PROC_MEM_NORM> => 1000000000 Тут вы можете увидеть максимально использование cpu 70%, использование памяти 2G, минимально 1 запущенный процесс, а так же имя процесса для примера: apache2. Так же мы должны задать нормальные значения наших параметров для построения гистерезиса в целях защиты от ложных срабатываний (описано ниже). По этому мы так же указываем как 10% и как 1G.
3. Добавление элементов данных
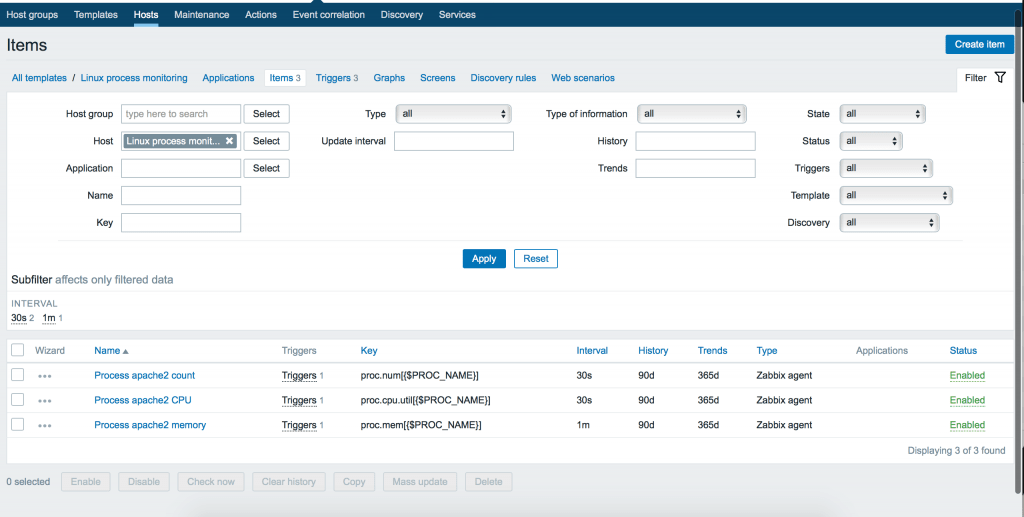
Теперь мы должны добавить элементы входных данных (items). Переходим в меню Items нашего шаблона и кликаем кнопку: Create item. Затем создаем 3 элемента:
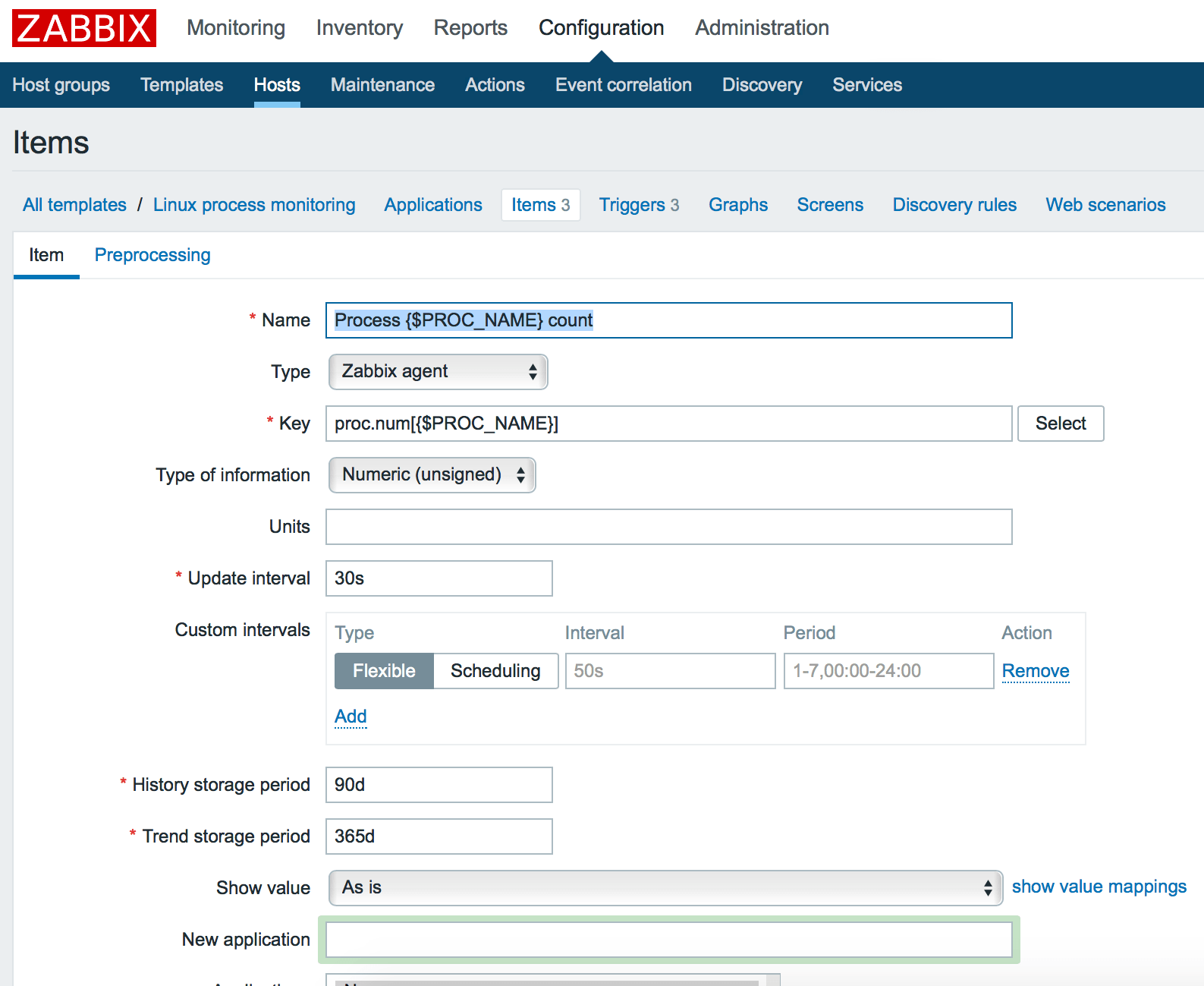
Мы можем использовать как макрос для задания конкретного имени процесса позже внутри конечной конфигурации хоста. Итак, добавляем 3 элемента с 3 ключами:
proc.num[$PROC_NAME>] proc.cpu.util[$PROC_NAME>] proc.mem[$PROC_NAME>]
Заметим, что параметры могут иметь различные типы данных. Так к примеру proc.num, proc.mem имеет тип данных: Numeric (int), а proc.cpu.util – Numeric (float). Вы можете удостовериться в правильности указания типа данных в меню Key -> Select или официальной документации Zabbix.
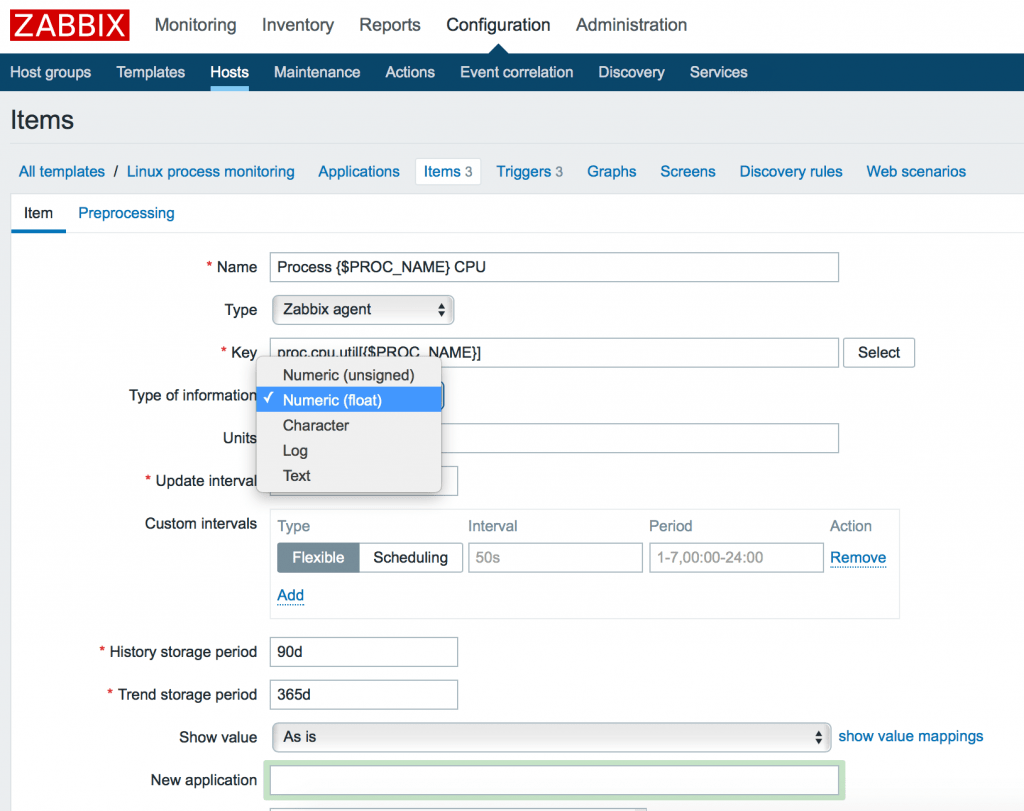
4. Триггеры с гистерезисом
Пришло время создать тригеры. Переходим в закладку Triggers нашего шаблона. Вы можете использовать встроенный конструктор выражений, нажав Problem expression -> Add, затем выбрав item и function. К примеру last (most recent) T value. Но это только одно последнее значение. Оно будет меняться каждый раз, что вызовет нестабильность в определении статуса. Чтобы определить жесткое (установившееся) значение статуса, это значение должно повториться несколько раз подряд. Для такого подсчета лучше использовать функцию count. Болле подробную информацию о функциях вы можете получить в официальной документации Zabbix.
Итак, создаем триггер, который будет срабатывать при привышении потребления памяти больше чем 3 раза подряд.
Linux process monitoring:proc.mem[$PROC_NAME>].count(#3,$PROC_MEM_MAX>,gt)>>=3 Мы можем прочитать его так: “Количество (count) последних 3 значений (#3), которые были больше (gt) чем равно >= 3″. Что означает, что все последние 3 значения были были больше чем PROC_MEM_MAX. Это хороший способ определения устоявшегося значения.
Но что делать с возвратом в нормальное состояние? Если мы просто оставим так как есть, мы рискуем получить что-то на подобие этого:
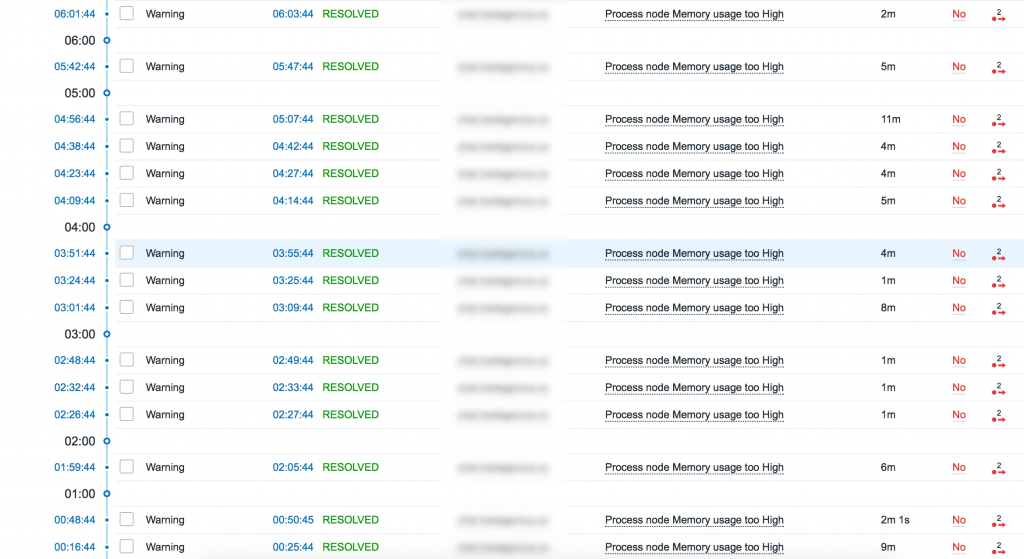
Каждые 5-10 минут статус меняет значение, колеблясь то выше, то ниже указанного порога. Он получает 3 подряд превышающих значения и триггер срабатывает, после чего он получает 3 нормальных значения и помечает проблему как RESOLVED (решена)! Что же делать? Нам поможет гистерезис с указанием не только максимального, но и нормального значения. Триггер будет в состоянии PROBLEM (проблема) до тех пор, пока значение нашего элемента не опустится до $.
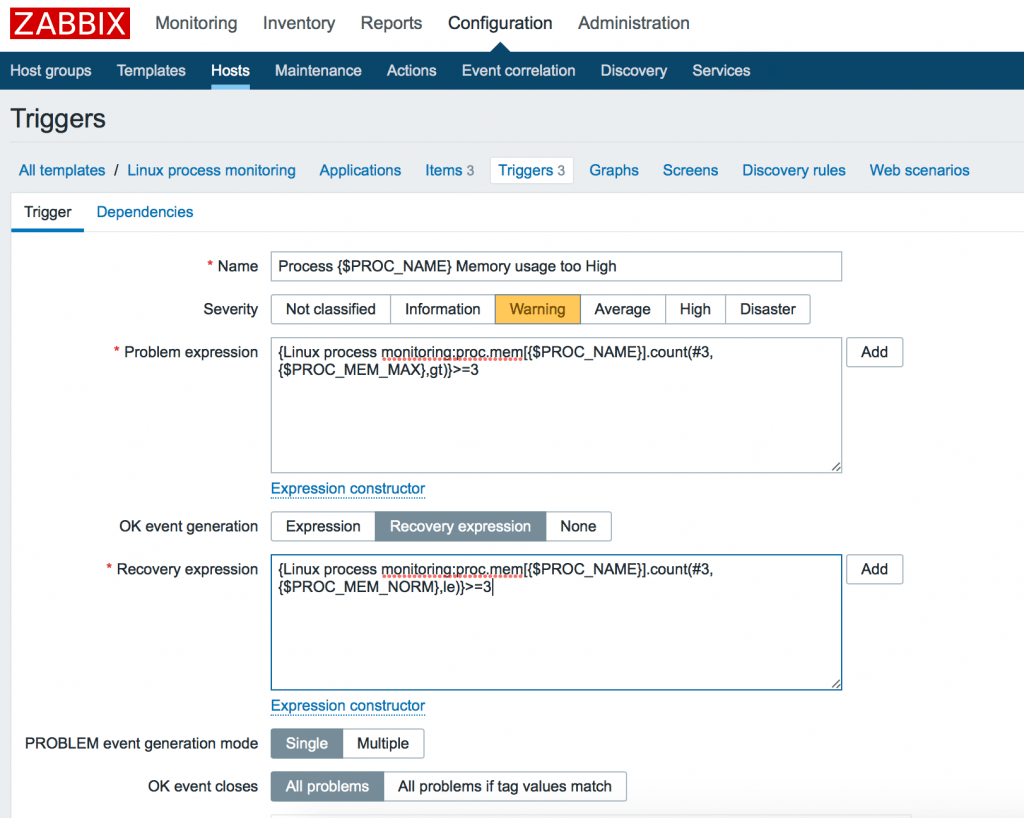
Итак, нажимаем OK event generation -> Recovery expression и добавляем выражение:
Linux process monitoring:proc.mem[$PROC_NAME>].count(#3,$PROC_MEM_NORM>,le)>>=3 Его можно прочитать как: “Количество (count) последних трех (#3) значений элемента, которые были меньше или равны (le) числу было >= 3 раз. То есть установившееся в нормальном положении значение.
Подобным образом добавляем остальные тригеры (для использования процессора и количества процессов):
Linux process monitoring:proc.mem[$PROC_NAME>].count(#3,$PROC_MEM_MAX>,gt)>>=3 Linux process monitoring:proc.mem[$PROC_NAME>].count(#3,$PROC_MEM_NORM>,le)>>=3 Linux process monitoring:proc.cpu.util[$PROC_NAME>].count(#3,$PROC_CPU_MAX>,gt)>>=3 Linux process monitoring:proc.cpu.util[$PROC_NAME>].count(#3,$PROC_CPU_NORM>,le)>>=3 Linux process monitoring:proc.num[$PROC_NAME>].count(#3,$PROC_COUNT_MIN>,lt)>>=3 Linux process monitoring:proc.num[$PROC_NAME>].count(#3,$PROC_COUNT_MIN>,ge)>>=3 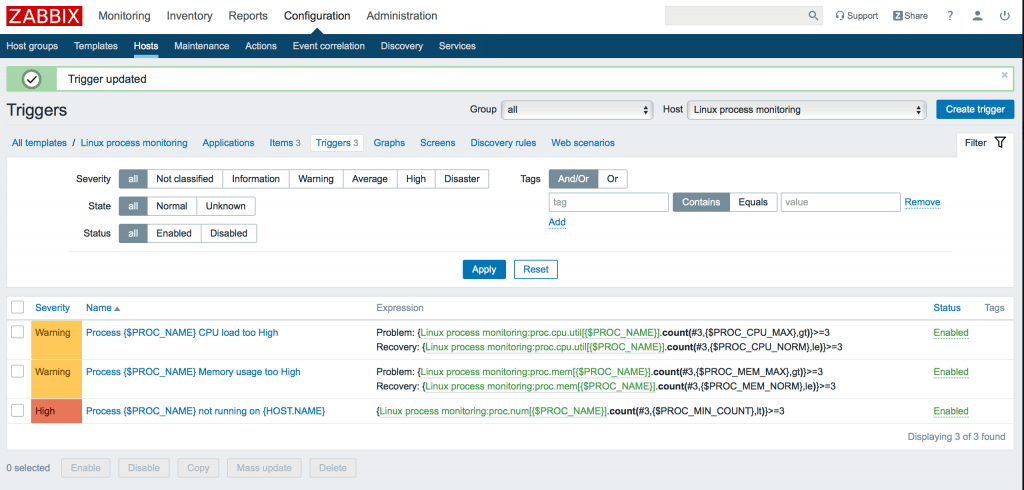
5. Конфигурация хоста
Теперь мы можем добавить наш шаблон к хосту. Идем в Configuration -> Hosts -> ваш сервер -> Templates. И добавляем только что созданный шаблон к серверу. Далее мы должны переопределись макросы.
Для примера на нашем сервере необходимо мониторить процесс node (node.js). Давайте посмотрим один из моих графиков данного процесса:
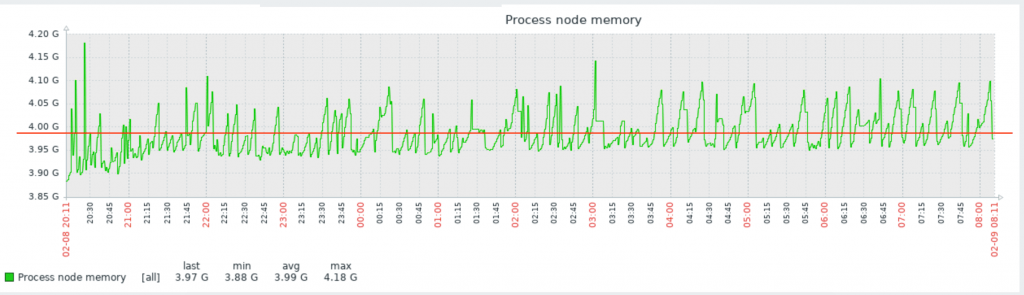
Вы видите, что у меня он потребляет порядка 4Gb RAM. Это нормальное состояние для моего сервиса. Так же вы видите колебание в районе красной линии. Без гистерезиса Zabbix нас просто заспамил бы сообщениями об изменении статуса в районе этой линии. В моем примере нормальное значение потребления памяти для указания в гистерезисе это 4G, а максимальное – больше чем 4.20G, пусть будет 4,5G. Добавим эти значения, а так же имя нашего процесса как макросы для данного хоста:
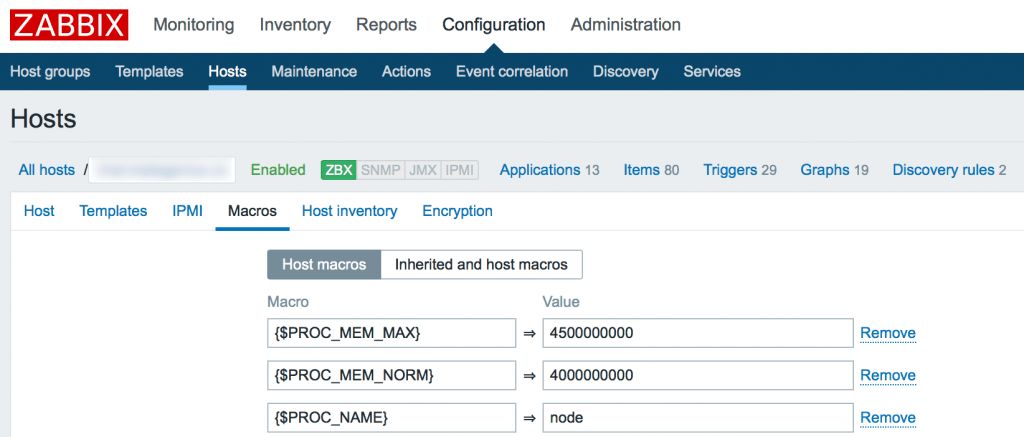
Итак, мой триггер перейдет в состоянии PROBLEM только когда значение потребляемой памяти будет больше чем 4,5Gb 3 раза подряд. А вернется он в нормальное состояние только тогда, когда потребление снизится ниже 4Г 3 раза подряд.
Готово! Позравляю! Теперь можно проверить последние данные в разделе Monitoring -> Latest data.
Вы можете скачать представленный в данной статье шаблон для вашего использования : linux-process.zip