SETERE OCR, или чем заменить ABBYY на Linux
В настоящее время, многие пользователи вынуждены менять привычную ОС Windows на различные варианты ОС на базе Linux. Как известно, далеко не всё привычное ПО, с которым пользователи обычно работают в операционной системе Windows, так же поддерживается и на Linux.
Сегодня мы поговорим о том, как быть, если Вы использовали для работы с PDF файлами, распознавания текста, его дальнейшего редактирования и т.д., программу ContentReader PDF (бывш. ABBYY FineReader). Данная программа не поддерживается операционными системами Linux, но есть замечательный отечественный аналог – SETERE OCR.
SETERE OCR (Optical Character Recognition) — это программный продукт, который позволяет компьютеру «распознавать» текст из изображений или PDF-документов. Он используется для автоматического извлечения текста из исходных изображений и преобразования его в формат, который может быть обработан компьютером.
SETERE OCR использует современные алгоритмы машинного обучения, чтобы точно распознать текст, даже если он имеет нестандартный шрифт или расположен на заднем плане изображения. Он также может распознавать текст на нескольких языках, включая русский, английский, немецкий и другие.
Кроме того, программу SETERE OCR можно использовать для преобразования отсканированных документов в другие форматы, такие как HTML или XML, для дальнейшей обработки.
Программа SETERE OCR также предлагает ряд полезных функций, облегчающих работу с отсканированными документами. Например, он может автоматически определять ориентацию документа и соответствующим образом поворачивать его. Он также включает в себя ряд параметров предварительной обработки изображения, таких как повышение контрастности и устранение перекосов, для улучшения качества вывода. Кроме того, пользователи могут настроить параметры распознавания, чтобы они лучше соответствовали их конкретному типу документа или языку.
Не маловажным преимуществом программы является то, что она включена в Единый реестр российских программ для ЭВМ и баз данных (запись № 12153).
- Автоматизация процессов: SETERE OCR позволяет автоматически извлекать текст из изображений или PDF-документов, что существенно ускоряет процесс и экономит время.
- Точность: SETERE OCR использует современные алгоритмы машинного обучения, чтобы достигать высокой точности распознавания текста, даже если он имеет нестандартный шрифт или расположен на заднем плане изображения.
- Поддержка многих языков: SETERE OCR может распознавать текст на нескольких языках, включая русский, английский, немецкий и другие
Основные возможности SETERE OCR:
- Сканирование с сетевых и локальных сканеров и МФУ
- Открытие и просмотр PDF-документов, фотографий и файлов изображений. Редактирование страниц в PDF-документах
- Распознавание текста и таблиц автоматически более чем на 190 мировых языках
- Распознавание произвольно расположенных от оси документа текстов и таблиц
- Конвертирование документов в форматы: pdf, odt, docx, txt и другие
- Сохранение исходной структуры документов при конвертировании
- Чтение ссылок и сохранение их при конвертировании
- Выделение некорректно распознанных символов
- Установка пароля и настройка прав доступа к документу при конвертировании в PDF-формат
На каких операционных системах работает SETERE OCR:
- Astra Linux CE 2.12,
- Astra Linux SE 1.6,
- Astra Linux SE 1.7,
- РЕД ОС 7.2, РЕД ОС 7.3,
- Альт 8 СП Рабочая станция,
- Альт Рабочая станция 9.2, Альт Рабочая станция 10,
- Альт Рабочая станция К10, Альт Образование 10,
- Simply Linux 10
Подведем итоги. SETERE OCR очень полезен для бизнеса, поскольку он помогает эффективно и быстро извлекать информацию из больших объемов документов, таких как контракты.
SETERE OCR (Optical Character Recognition) – это мощный инструмент для распознавания текста из изображений или PDF-документов. Использование этой программы приносит множество преимуществ, которые могут значительно улучшить эффективность вашей работы.
Программа так же привлекает своей гибкой системой лицензирования. Дак давайте же разберёмся, какие типы и виды лицензий SETERE OCR существуют и озвучим их особенности.
Варианты лицензирования по типу лицензии:
- Локальная лицензия. Аналог лицензии «Standalone» для ABBYY FineReader PDF. Устанавливается на одно рабочее место (ПК), использование программы в сети невозможно.
- Конкурентная лицензия. Аналог лицензии «Concurrent» для ABBYY FineReader PDF. Может быть установлена на неограниченном количестве компьютеров, но одновременно ПО можно использовать на количестве ПК или ВМ, не превышающем объем закупленных лицензий.
Варианты лицензирования по сроку действия:
- срочная лицензия на 1 год (12 месяцев);
- срочная лицензия на 3 года (36 месяцев);
- бессрочная лицензия (без ограничения срока действия).
Варианты лицензирования по сроку действия технической поддержки (ТП):
- для срочных лицензий в стоимость включается Стандартная ТП на весь срок действия лицензии;
- для бессрочных лицензий в стоимость включается Стандартная ТП на срок 1 год (минимум) или на 2 года.
Описание технической поддержки
- Право на установку и использование новых релизов в рамках приобретенной минорной версии, а также установка и использование новых минорных версий.
- Доступ к справочному центру ПО.
- Консультации по установке, использованию и настройке ПО.
- Анализ совместимости оборудования.
- Прием запросов пользователей круглосуточно, отработка запросов
- в рабочие дни с 8 до 18 часов по московскому времени.
- Базовый уровень техподдержки предоставляется всем пользователям, приобретающим бессрочные лицензии Продукта, у которых завершилось действие сертификатов технической поддержки тип «Стандартная».
- Право на установку и использование новых релизов только в рамках приобретенной минорной версии.
- Доступ к справочному центру ПО.
KBookOCR for Linux. Убийца FineReader-а для Linux на начальной стадии
Возможно каждый из нас переживал период в своей жизни который сопровождался активно оцифровкой аналогов материала. Я имею в виду необходимость работы с текстом из неоцифрованных источников. Имеется в виду не только проблема сканирования, но и так же множество материала который к сожалению доходит до конечного потребитель не совсем в пригодном для использования виде. И я думаю у каждого из нас очень часто в голове пробегали лестные мысли об распространителя книги в формате djvu или pdf в котором весь контент был представлен сугубо графически без возможности использование материалов для своей деятельности.
Для Windows-пользователей существует вариант использования FineReader, который без труда осуществлял процесс распознавания со всеми вытекающими.
Linux — решение проблемы
Ну а что делать людям, которые способны использовать более продвинутые операционные системы сохраняя при этом свои финансы на приемлемом уровне? Разумеется существуют проекты консольных утилит по распознаванию текста. На базе одной из самых развитых открытых технологий OCR создали целый дистрибутив по развертыванию сервера для OCR с веб-интерфейсом для общения с этим самым сервером. Но не думаю что конечному потребителю интересны такие монструозные решения. А сама по себе технология реализована во многих дистрибутивах в виде консольного приложения, которое может оперировать не популярными форматами, из которых чаще всего и необходимо “выдрать” текст (djvu, pdf), а графическими файлами что осложняет процесс использования.
Разумеется такое положение вещей и любовь Линуксоидов к оптимизации всего и вся привели к появлению проекта BookOCR, основателям которого и программистом выступает замечательный человек mr-protos, которого пока нету на Хабре. Далее его статья о создании BookOCR:
BookOCR
mr-protos создал в меру простой bash-скрипт bookocr.sh:
bookocr.tar.xz (размещено на dropbox)
Алгоритм его работы:
1. проверка расширения файла (.djvu или .pdf. В случае иного расширения скрипт выдаст предупреждение);
2. постраничное конвертирование файла в .png для дальнейшего распознавания. (результат складывается во временную папку ~/.tmp_pdf или ~/.tmp_djvu);
3. распознавание сконвертированных страниц с помощью OCR;
4. объединение постранично-распознанных текстовых файлов в один;
5. удаление временной папки.
Использование скрипта:
- cuneiform
- ghostscript
- djvulibre-bin
- libtiff-tools
- libnotify-bin
KBookOCR
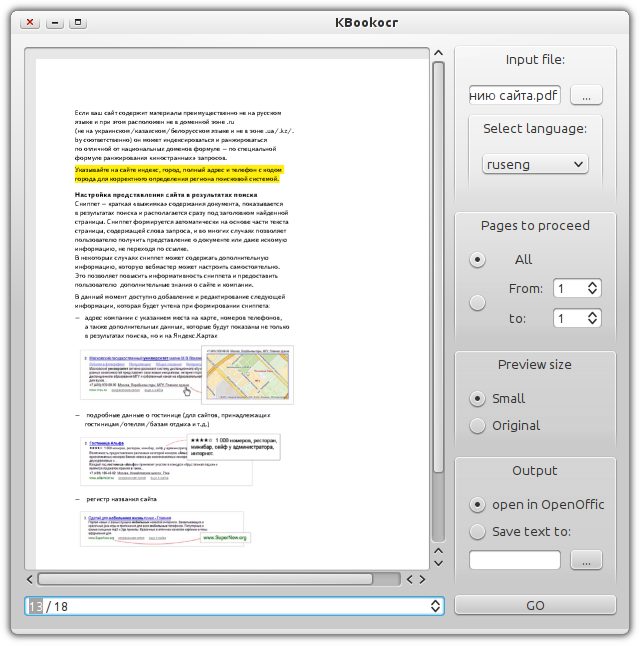
Разумеется данный проект стал толчком для еще одной амбициозной идеи, которую совместно с автором BookOCR воплотил в жизнь Ваш покорный слуга b0noI. Идея заключалась в том что бы реализовать систему пригодную для использования визуальными эстетами во всем предпочитающих визуально-красивое оформление (это как минимум), а как максимум создать проект на базе Linux, который бы позволял выполнять функционал FineReader в столь же удобной и эстетично прекрасном варианте.
Для разработки была выбрана библиотека Qt. С одной стороны этот проект представляет с собой надстройку над проектом BookOCR, однако не все так просто. Так как при интеграции приходилось вносить существенные изменения в изначальный скрипт. Особые проблемы были при реализации предпросмотра djvu файлов, так как если для pdf существует проект poppler, то в указанном случаи предпросмотр пришлось реализовать сторонней bash утилитой. Именно по этому в систему при установки KbookOCR, по мимо самого KbookOCR, устанавливается не только BookOCR, но и консольная утилита которая используется для получения картинки используемой при предпросмотре.
Текущее состояние проекта
- выполнять предпросмотр документа который необходимо распознать (пролистывать страницы);
- указывать язык распознавания. На текущий момент отсутствует распознавания языка в документе, однако это планируется сделать. Так же нет возможности указывать двойной язык распознавания документа (за исключением rus/eng);
- менять размеры предпросмотра. Доступно два варианта — оригинальный размер или же уменьшенный;
- распознавать можно по заданному диапазону или же весь документ;
- сохранение распознанного документа. Доступно два варианта — или же сохранить результат в обычный текстовый файл, либо же открыть результат в OpenOffice Writer.
RoadMap
- работу со сканером;
- автоопределение языка в документе;
- более гибкий предпросмотр. с прорисовкой миниатюр страниц, а так же с более гибким указанием масштаба отображения;
- более гибкое указание диапазона распознавание.
Послесловие
И хотя KbookOCR является наиболее свежим детищем нашего дуэта, программа не является первым и единственным нашим творением. В следующей серии мы расскажем Вам о нашем первом совместном проекте для Linux — KbashPod для подкастофилов.
UPD:
- Поддержка сканера (via scanimage);
- Вывод результата в формате html, rtf (via cuneiform);
- Обработка форматирования текста (via cuneiform);
- Динамическое изменение масштаба предпросмотра.